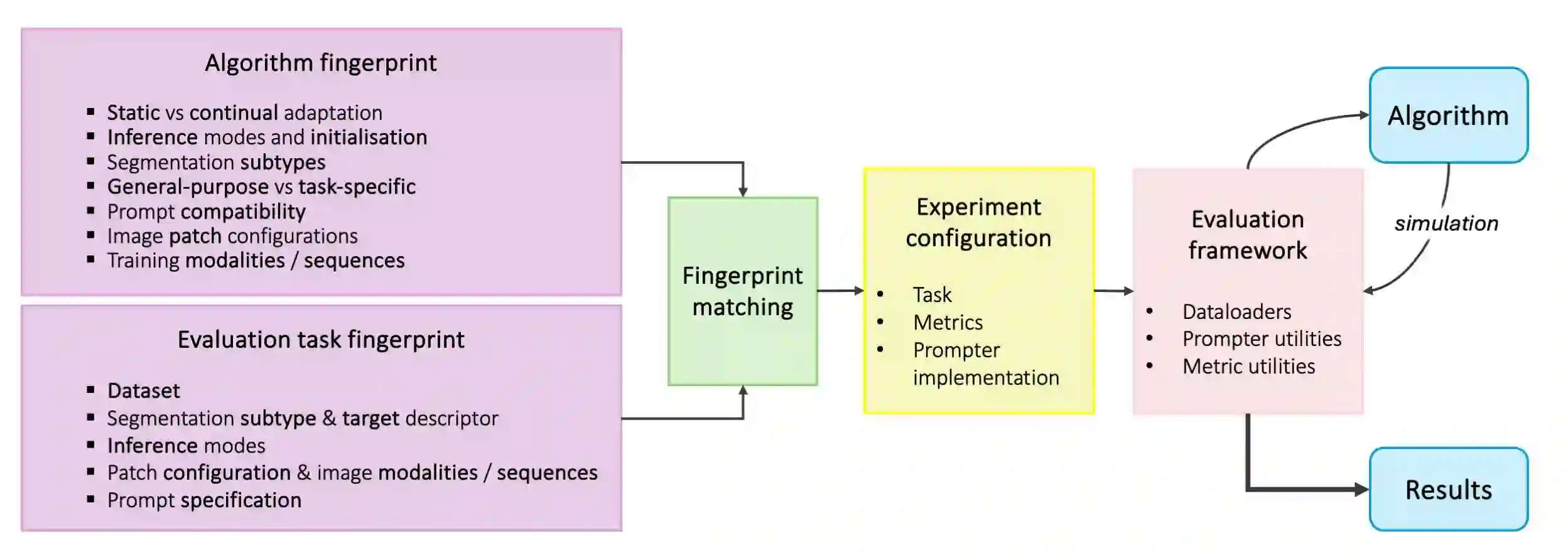
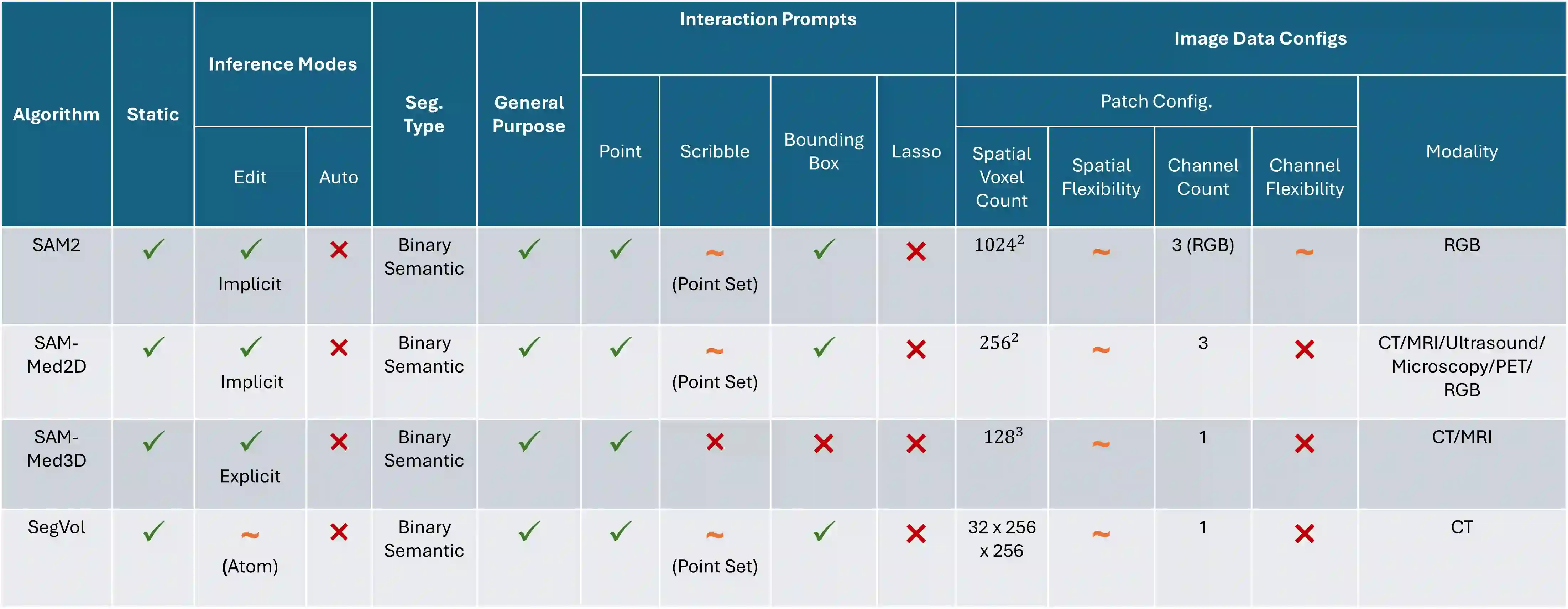
Interactive segmentation is a promising strategy for building robust, generalisable algorithms for volumetric medical image segmentation. However, inconsistent and clinically unrealistic evaluation hinders fair comparison and misrepresents real-world performance. We propose a clinically grounded methodology for defining evaluation tasks and metrics, and built a software framework for constructing standardised evaluation pipelines. We evaluate state-of-the-art algorithms across heterogeneous and complex tasks and observe that (i) minimising information loss when processing user interactions is critical for model robustness, (ii) adaptive-zooming mechanisms boost robustness and speed convergence, (iii) performance drops if validation prompting behaviour/budgets differ from training, (iv) 2D methods perform well with slab-like images and coarse targets, but 3D context helps with large or irregularly shaped targets, (v) performance of non-medical-domain models (e.g. SAM2) degrades with poor contrast and complex shapes.
翻译:交互式分割是构建鲁棒、可泛化的医学体图像分割算法的一种有前景的策略。然而,不一致且临床不现实的评估阻碍了公平比较,并歪曲了真实世界的性能。我们提出了一种基于临床的方法来定义评估任务和指标,并构建了一个用于构建标准化评估流程的软件框架。我们在异构且复杂的任务上评估了最先进的算法,并观察到:(i) 在处理用户交互时最小化信息损失对于模型鲁棒性至关重要,(ii) 自适应缩放机制能提升鲁棒性并加速收敛,(iii) 如果验证阶段的提示行为/预算与训练阶段不同,性能会下降,(iv) 2D方法在处理板状图像和粗略目标时表现良好,但3D上下文有助于处理大尺寸或不规则形状的目标,(v) 非医学领域模型(例如SAM2)在对比度差和形状复杂时性能会下降。