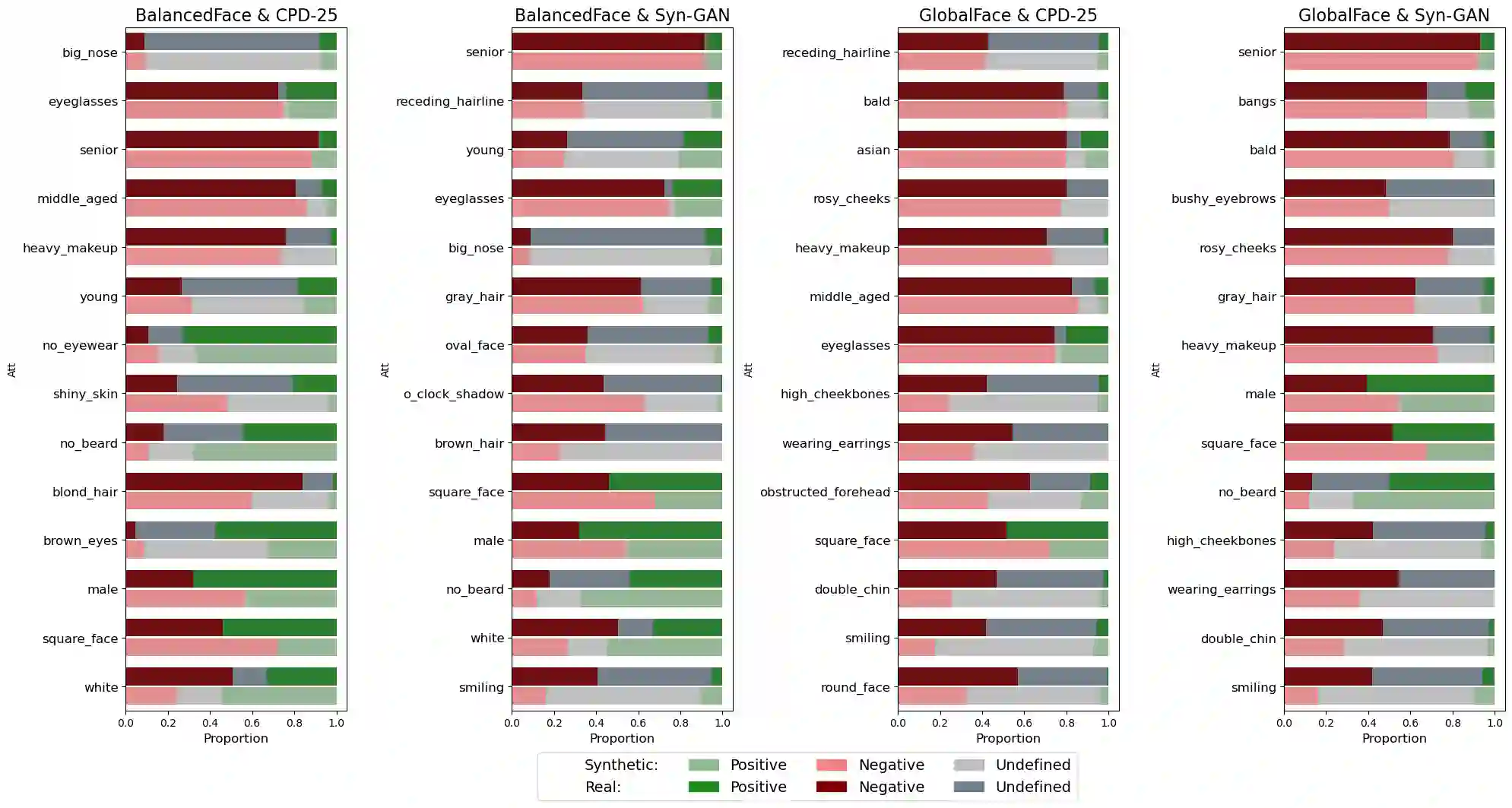
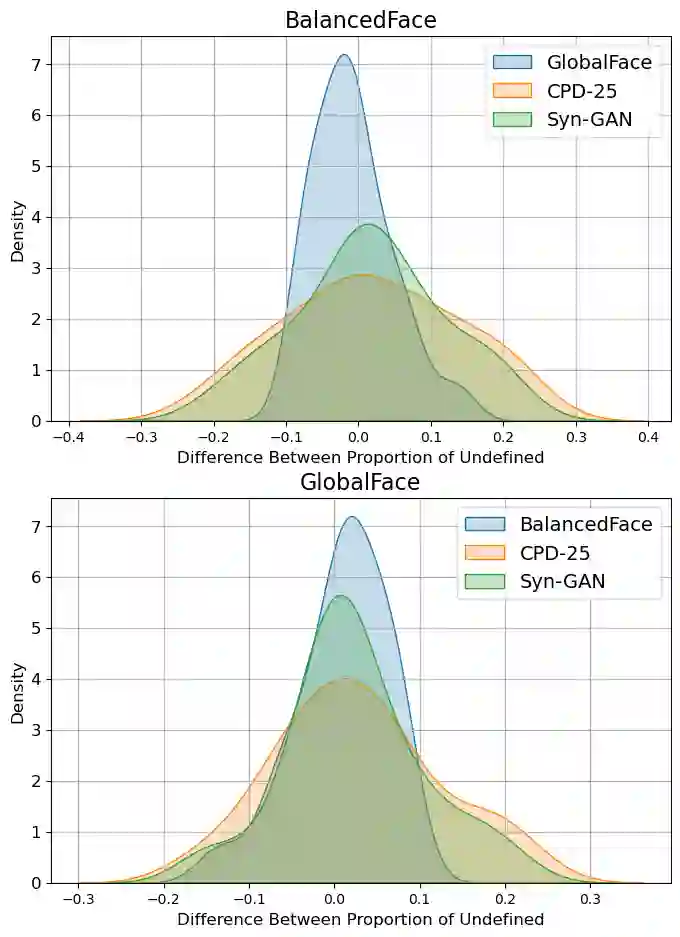
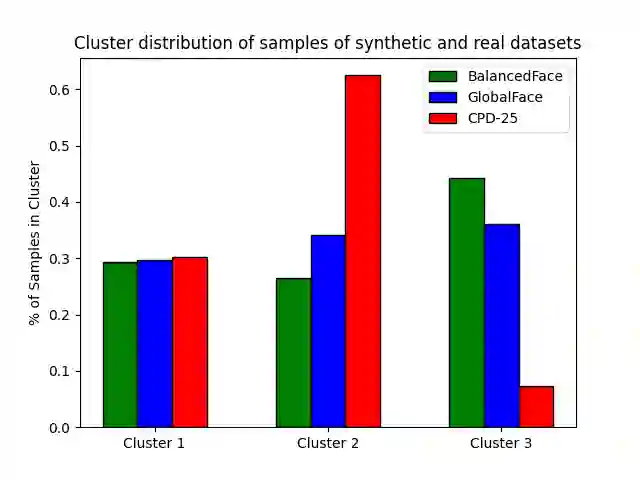
Face recognition applications have grown in parallel with the size of datasets, complexity of deep learning models and computational power. However, while deep learning models evolve to become more capable and computational power keeps increasing, the datasets available are being retracted and removed from public access. Privacy and ethical concerns are relevant topics within these domains. Through generative artificial intelligence, researchers have put efforts into the development of completely synthetic datasets that can be used to train face recognition systems. Nonetheless, the recent advances have not been sufficient to achieve performance comparable to the state-of-the-art models trained on real data. To study the drift between the performance of models trained on real and synthetic datasets, we leverage a massive attribute classifier (MAC) to create annotations for four datasets: two real and two synthetic. From these annotations, we conduct studies on the distribution of each attribute within all four datasets. Additionally, we further inspect the differences between real and synthetic datasets on the attribute set. When comparing through the Kullback-Leibler divergence we have found differences between real and synthetic samples. Interestingly enough, we have verified that while real samples suffice to explain the synthetic distribution, the opposite could not be further from being true.
翻译:人脸识别应用随着数据集规模、深度学习模型复杂度及计算能力的增长而同步发展。然而,尽管深度学习模型不断进化以增强能力,计算能力持续提升,可供使用的数据集却在陆续被撤销并从公共访问中移除。隐私与伦理问题已成为该领域的重要议题。研究者们借助生成式人工智能,致力于开发可用于训练人脸识别系统的完全合成数据集。然而,当前进展尚不足以在性能上媲美基于真实数据训练的最先进模型。为探究基于真实数据集与合成数据集训练的模型之间的性能差异,我们利用大规模属性分类器(MAC)为四个数据集(两个真实数据集、两个合成数据集)生成标注。基于这些标注,我们对四个数据集中各属性的分布展开研究,并进一步审视真实数据集与合成数据集在属性集上的差异。通过Kullback-Leibler散度进行对比时,我们发现真实样本与合成样本之间存在差异。有趣的是,我们验证得出:真实样本足以解释合成分布,但反之则远非如此。