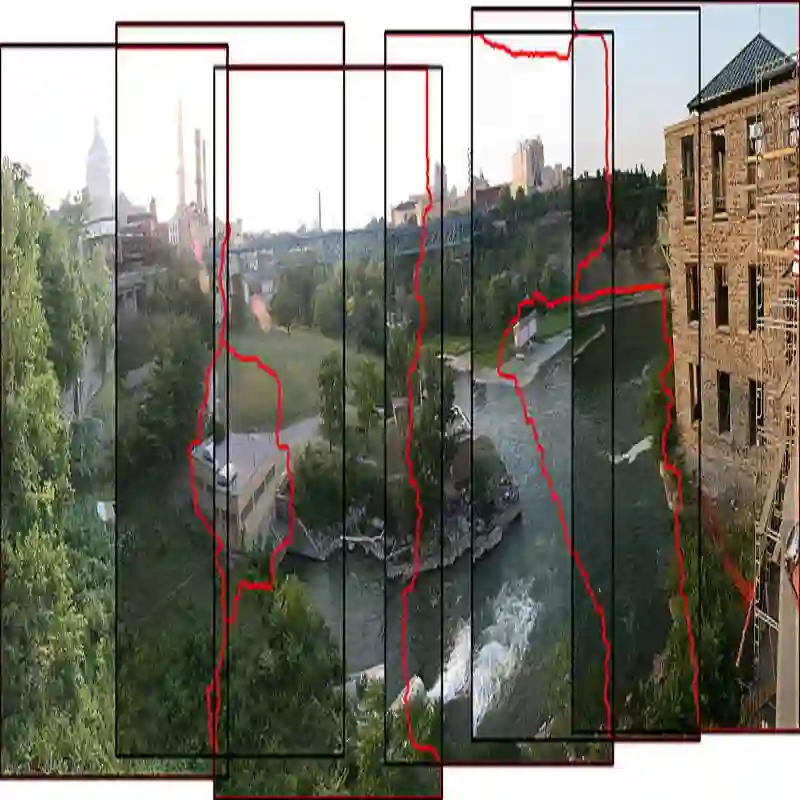
We present \textit{RopStitch}, an unsupervised deep image stitching framework with both robustness and naturalness. To ensure the robustness of \textit{RopStitch}, we propose to incorporate the universal prior of content perception into the image stitching model by a dual-branch architecture. It separately captures coarse and fine features and integrates them to achieve highly generalizable performance across diverse unseen real-world scenes. Concretely, the dual-branch model consists of a pretrained branch to capture semantically invariant representations and a learnable branch to extract fine-grained discriminative features, which are then merged into a whole by a controllable factor at the correlation level. Besides, considering that content alignment and structural preservation are often contradictory to each other, we propose a concept of virtual optimal planes to relieve this conflict. To this end, we model this problem as a process of estimating homography decomposition coefficients, and design an iterative coefficient predictor and minimal semantic distortion constraint to identify the optimal plane. This scheme is finally incorporated into \textit{RopStitch} by warping both views onto the optimal plane bidirectionally. Extensive experiments across various datasets demonstrate that \textit{RopStitch} significantly outperforms existing methods, particularly in scene robustness and content naturalness. The code is available at {\color{red}https://github.com/MmelodYy/RopStitch}.
翻译:我们提出了\textit{RopStitch},一种兼具鲁棒性与自然性的无监督深度图像拼接框架。为确保\textit{RopStitch}的鲁棒性,我们提出通过一种双分支架构将内容感知的通用先验融入图像拼接模型。该架构分别捕获粗粒度与细粒度特征并将其融合,从而在多样化的未见真实场景中实现高度泛化的性能。具体而言,双分支模型包含一个预训练分支用于捕获语义不变表示,以及一个可学习分支用于提取细粒度判别特征,两者通过一个可控因子在相关度层面融合为一个整体。此外,考虑到内容对齐与结构保持往往相互矛盾,我们提出了虚拟最优平面的概念以缓解这一冲突。为此,我们将该问题建模为估计单应性分解系数的过程,并设计了一个迭代系数预测器与最小语义失真约束来识别最优平面。该方案最终通过将两个视图双向扭曲至最优平面,整合到\textit{RopStitch}中。在多个数据集上的大量实验表明,\textit{RopStitch}显著优于现有方法,尤其在场景鲁棒性与内容自然性方面。代码发布于{\color{red}https://github.com/MmelodYy/RopStitch}。