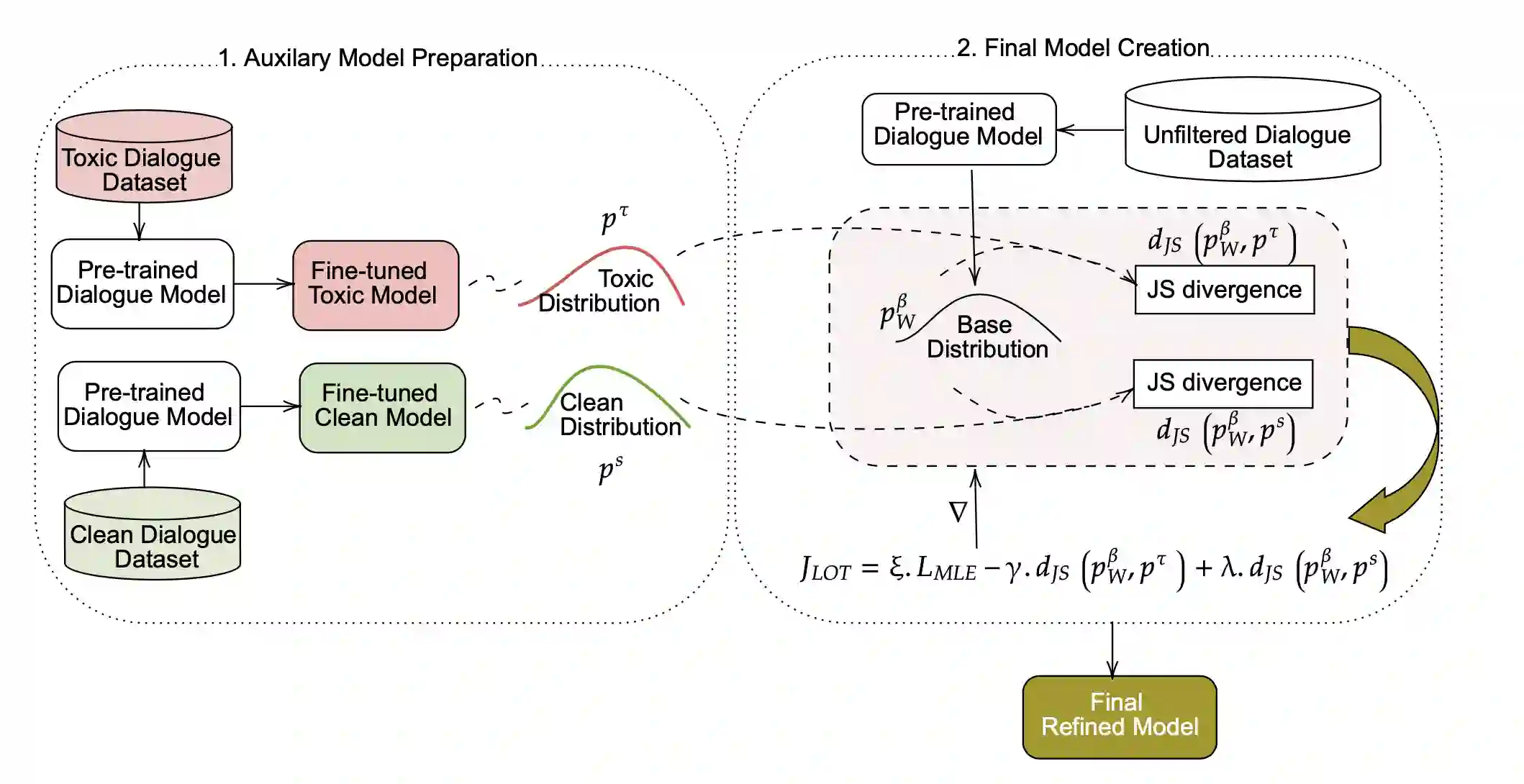
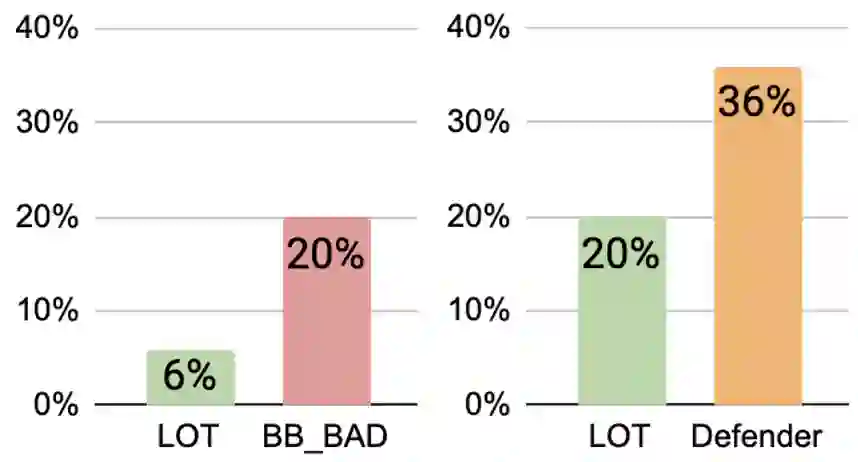
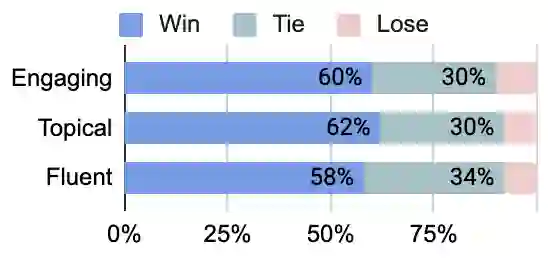
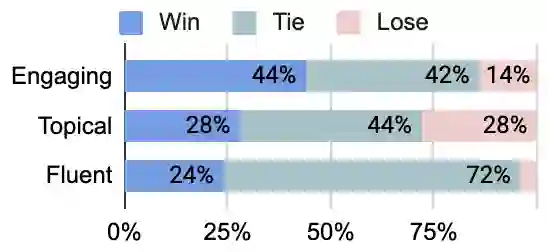
Conversational models that are generative and open-domain are particularly susceptible to generating unsafe content since they are trained on web-based social data. Prior approaches to mitigating this issue have drawbacks, such as disrupting the flow of conversation, limited generalization to unseen toxic input contexts, and sacrificing the quality of the dialogue for the sake of safety. In this paper, we present a novel framework, named "LOT" (Learn NOT to), that employs a contrastive loss to enhance generalization by learning from both positive and negative training signals. Our approach differs from the standard contrastive learning framework in that it automatically obtains positive and negative signals from the safe and unsafe language distributions that have been learned beforehand. The LOT framework utilizes divergence to steer the generations away from the unsafe subspace and towards the safe subspace while sustaining the flow of conversation. Our approach is memory and time-efficient during decoding and effectively reduces toxicity while preserving engagingness and fluency. Empirical results indicate that LOT reduces toxicity by up to four-fold while achieving four to six-fold higher rates of engagingness and fluency compared to baseline models. Our findings are further corroborated by human evaluation.
翻译:对话模型,尤其是生成式和开放域模型,由于基于网络社交数据进行训练,特别容易生成不安全内容。先前缓解这一问题的方法存在缺陷,例如破坏对话流畅性、对未见过的有毒输入上下文泛化能力有限,以及为安全而牺牲对话质量。本文提出了一种名为“LOT”(意即“学会不”)的新框架,该框架通过对比损失从正负训练信号中学习来增强泛化能力。我们的方法与标准对比学习框架的不同之处在于,它自动从预先学习的安全与不安全语言分布中获取正负信号。LOT框架利用散度将生成结果从不安全子空间引导至安全子空间,同时保持对话的流畅性。我们的方法在解码过程中节省内存和时间,有效降低毒性,同时保持参与度和流畅性。实验结果表明,与基线模型相比,LOT将毒性降低多达四倍,同时参与度和流畅性提高四到六倍。我们的发现还得到了人工评估的进一步证实。