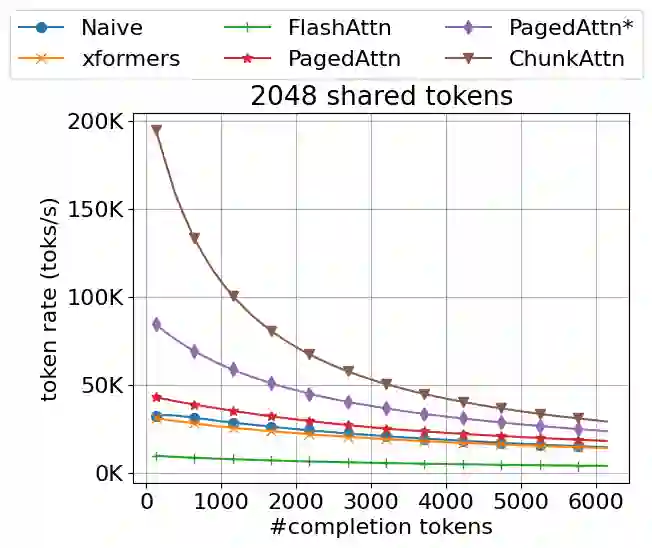
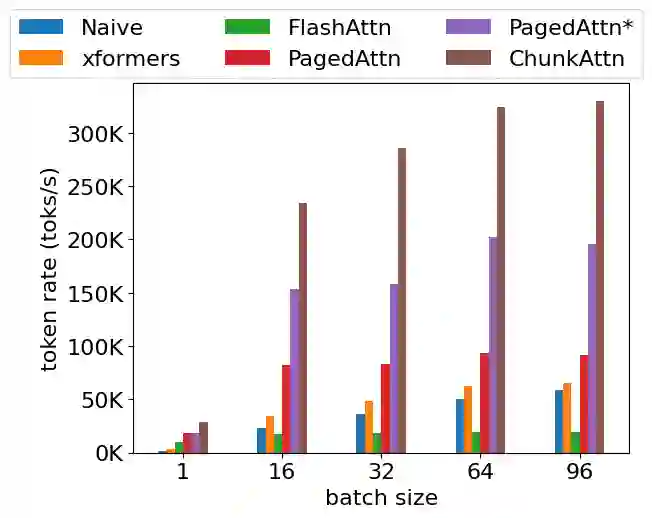
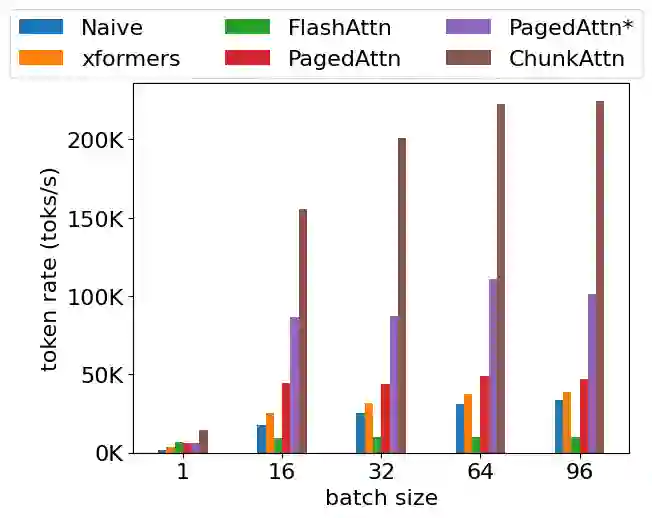
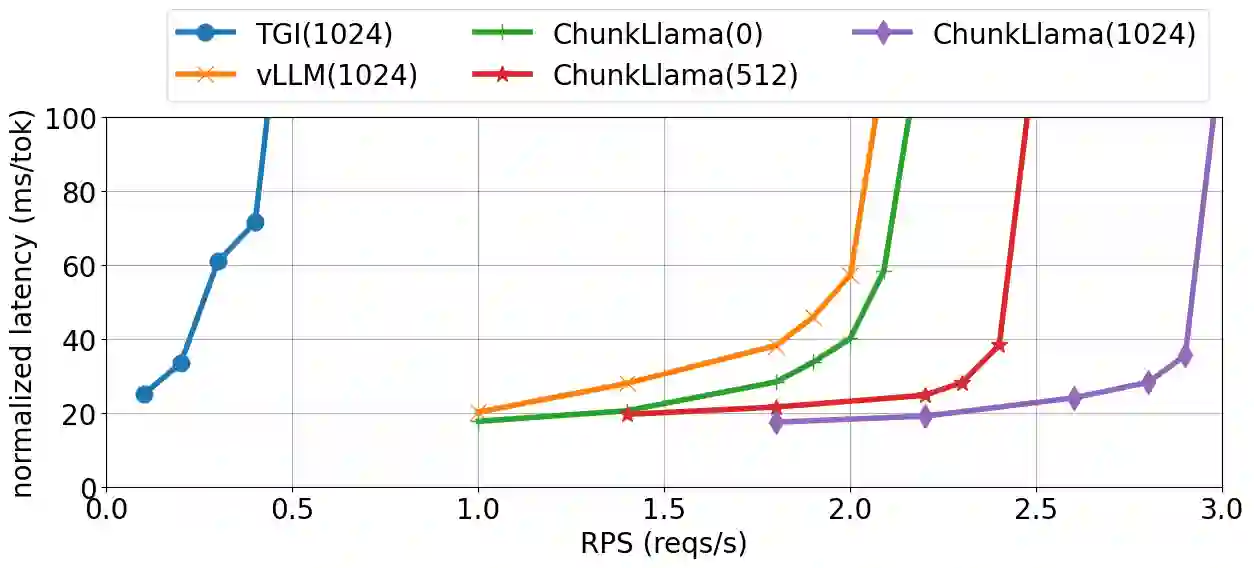
Self-attention is an essential component of large language models (LLM) but a significant source of inference latency for long sequences. In multi-tenant LLM serving scenarios, the compute and memory operation cost of self-attention can be optimized by using the probability that multiple LLM requests have shared system prompts in prefixes. In this paper, we introduce ChunkAttention, a prefix-aware self-attention module that can detect matching prompt prefixes across multiple requests and share their key/value tensors in memory at runtime to improve the memory utilization of KV cache. This is achieved by breaking monolithic key/value tensors into smaller chunks and structuring them into the auxiliary prefix tree. Consequently, on top of the prefix-tree based KV cache, we design an efficient self-attention kernel, where a two-phase partition algorithm is implemented to improve the data locality during self-attention computation in the presence of shared system prompts. Experiments show that ChunkAttention can speed up the self-attention kernel by 3.2-4.8$\times$ compared to the state-of-the-art implementation, with the length of the system prompt ranging from 1024 to 4096.
翻译:自注意力是大语言模型(LLM)的核心组件,但也是长序列推理延迟的主要来源。在多租户LLM服务场景中,可利用多个LLM请求在前缀部分共享系统提示的概率特性,优化自注意力的计算与内存操作开销。本文提出ChunkAttention——一种前缀感知的自注意力模块,能够在运行时检测多个请求间匹配的提示前缀,并在内存中共享其键/值张量,从而提升KV缓存的内存利用率。该模块通过将整体式键/值张量拆分为更小的块,并将其组织为辅助前缀树结构来实现这一目标。在此基础上,我们设计了一种基于前缀树KV缓存的高效自注意力计算内核,其中采用两阶段分区算法以改善存在共享系统提示时自注意力计算过程中的数据局部性。实验表明,当系统提示长度在1024至4096范围内时,ChunkAttention可将自注意力内核的计算速度较现有最优实现提升3.2-4.8$\times$。