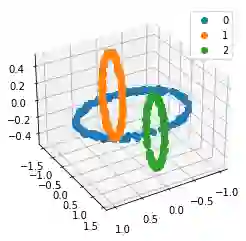
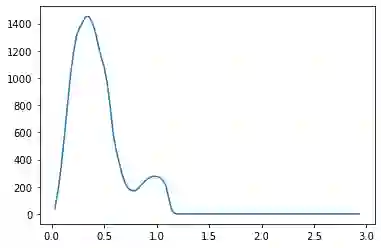
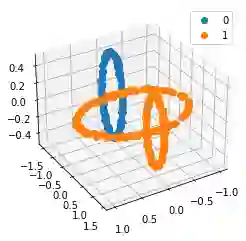
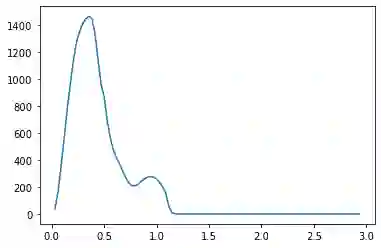
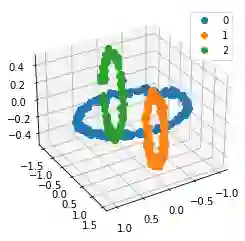
We propose a pair of completely data-driven algorithms for unsupervised classification and dimension reduction, and we empirically study their performance on a number of data sets, both simulated data in three-dimensions and images from the COIL-20 data set. The algorithms take as input a set of points sampled from a uniform distribution supported on a metric space, the latter embedded in an ambient metric space, and they output a clustering or reduction of dimension of the data. They work by constructing a natural family of graphs from the data and selecting the graph which maximizes the relative von Neumann entropy of certain normalized heat operators constructed from the graphs. Once the appropriate graph is selected, the eigenvectors of the graph Laplacian may be used to reduce the dimension of the data, and clusters in the data may be identified with the kernel of the associated graph Laplacian. Notably, these algorithms do not require information about the size of a neighborhood or the desired number of clusters as input, in contrast to popular algorithms such as $k$-means, and even more modern spectral methods such as Laplacian eigenmaps, among others. In our computational experiments, our clustering algorithm outperforms $k$-means clustering on data sets with non-trivial geometry and topology, in particular data whose clusters are not concentrated around a specific point, and our dimension reduction algorithm is shown to work well in several simple examples.
翻译:本文提出了一对完全数据驱动的无监督分类与降维算法,并通过模拟三维数据及COIL-20数据集图像进行了实证性能研究。该算法以从度量空间支撑的均匀分布中采样的点集作为输入(该度量空间嵌入于环境度量空间中),输出数据的聚类或降维结果。其核心机制是通过数据构建自然图族,并选择能使基于这些图构造的归一化热算子的相对冯·诺依曼熵最大化的图。选定合适图结构后,可利用图拉普拉斯算子的特征向量实现数据降维,而数据中的聚类可通过对应图拉普拉斯算子的核空间进行识别。值得注意的是,与$k$-均值等传统算法乃至拉普拉斯特征映射等更现代的谱方法相比,本算法无需预先设定邻域大小或期望聚类数量作为输入参数。计算实验表明:在具有非平凡几何与拓扑结构(特别是聚类不围绕特定中心点分布)的数据集上,我们的聚类算法性能优于$k$-均值聚类;同时,降维算法在多个简单示例中亦表现出良好效果。