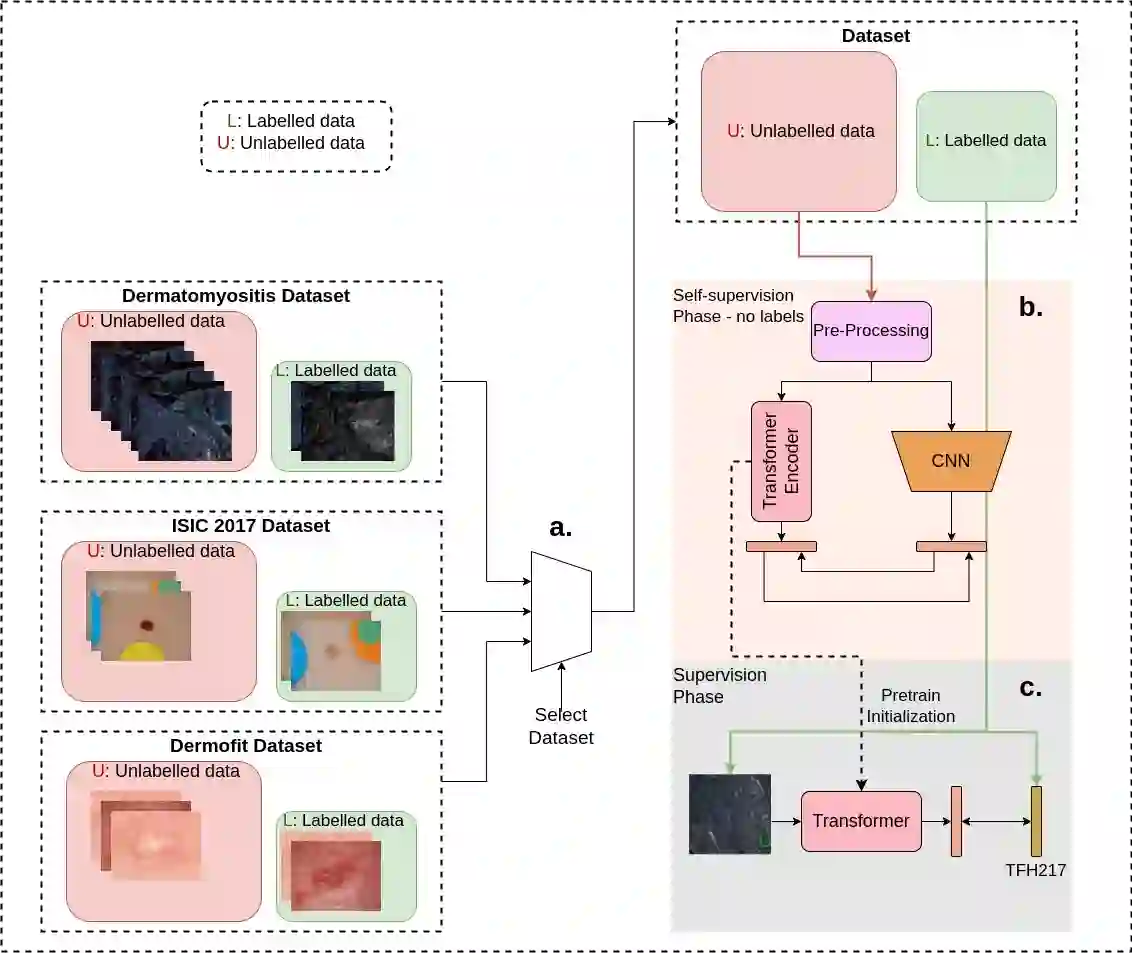
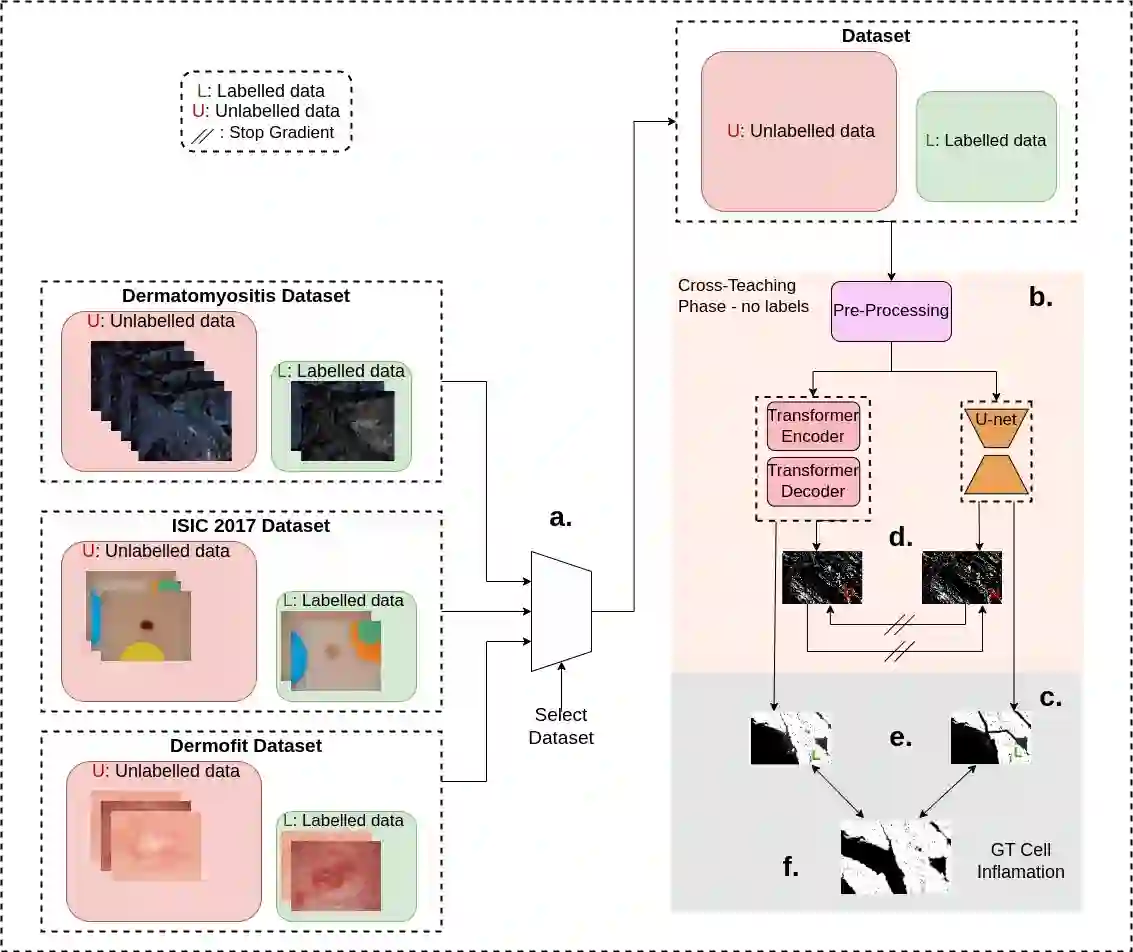
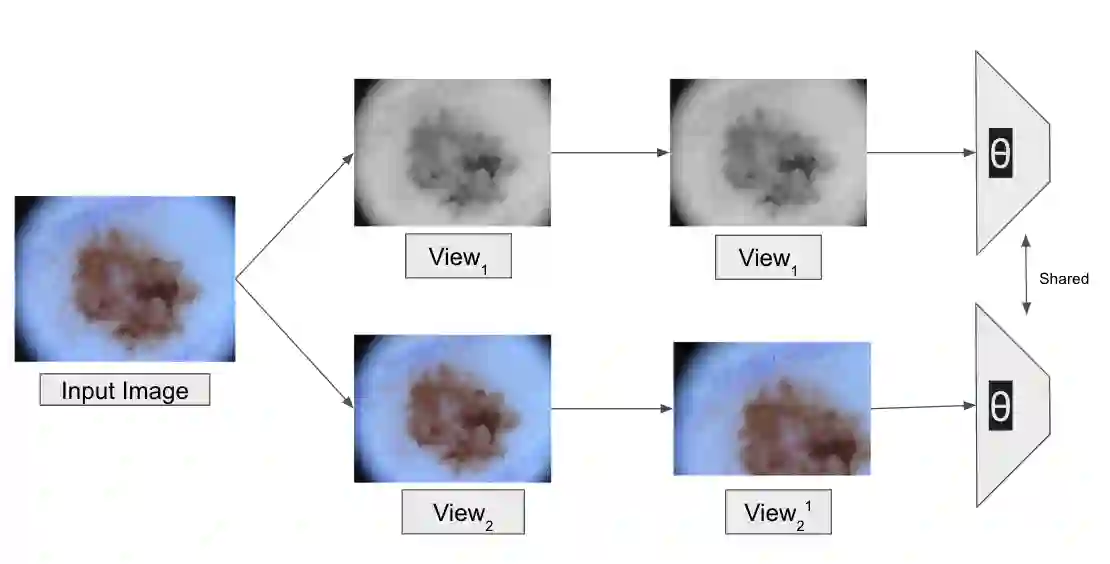
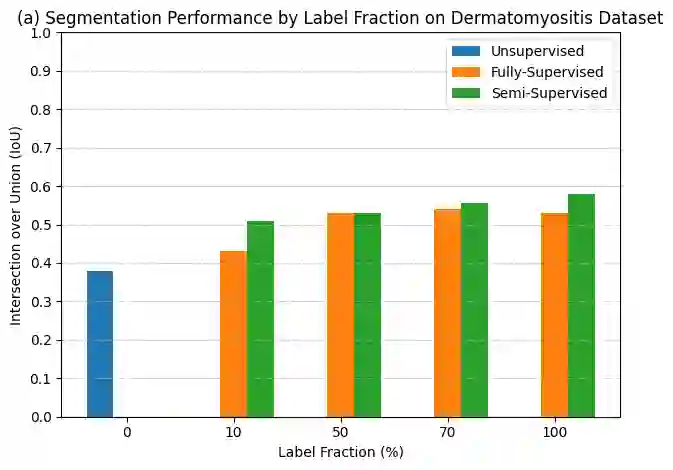
Advancements in clinical treatment are increasingly constrained by the limitations of supervised learning techniques, which depend heavily on large volumes of annotated data. The annotation process is not only costly but also demands substantial time from clinical specialists. Addressing this issue, we introduce the S4MI (Self-Supervision and Semi-Supervision for Medical Imaging) pipeline, a novel approach that leverages advancements in self-supervised and semi-supervised learning. These techniques engage in auxiliary tasks that do not require labeling, thus simplifying the scaling of machine supervision compared to fully-supervised methods. Our study benchmarks these techniques on three distinct medical imaging datasets to evaluate their effectiveness in classification and segmentation tasks. Notably, we observed that self supervised learning significantly surpassed the performance of supervised methods in the classification of all evaluated datasets. Remarkably, the semi-supervised approach demonstrated superior outcomes in segmentation, outperforming fully-supervised methods while using 50% fewer labels across all datasets. In line with our commitment to contributing to the scientific community, we have made the S4MI code openly accessible, allowing for broader application and further development of these methods.
翻译:临床治疗的进步日益受到监督学习技术局限性的制约,这类技术高度依赖大量标注数据。标注过程不仅成本高昂,还需要临床专家投入大量时间。为解决这一问题,我们提出了S4MI(医学影像自监督与半监督)流程,这是一种利用自监督和半监督学习进展的新型方法。这些技术通过执行无需标注的辅助任务,相较于全监督方法简化了机器监督的规模扩展。本研究在三个不同的医学影像数据集上对这些技术进行基准测试,评估其在分类和分割任务中的有效性。值得注意的是,我们观察到自监督学习在所有评估数据集的分类任务中显著超越了监督方法的性能。更令人瞩目的是,半监督方法在分割任务中展现出优于全监督方法的结果,且在所有数据集上使用的标注量减少了50%。秉承对科学社区的贡献承诺,我们已将S4MI代码开源,以便更广泛地应用和进一步开发这些方法。