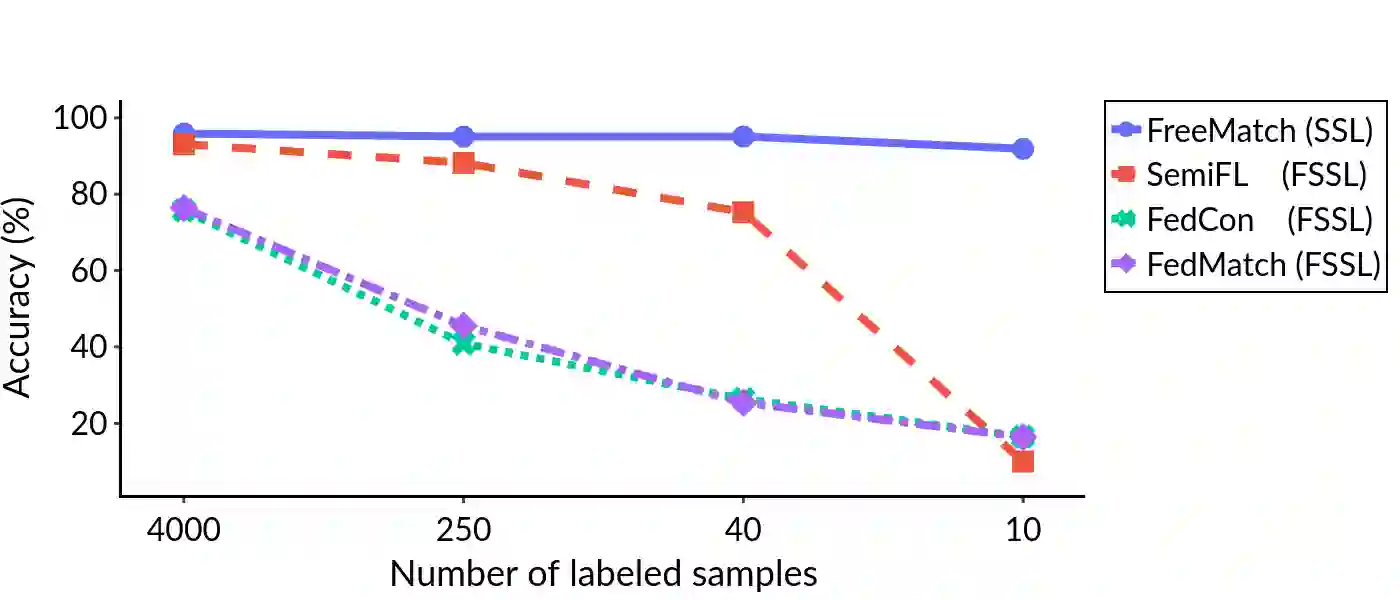
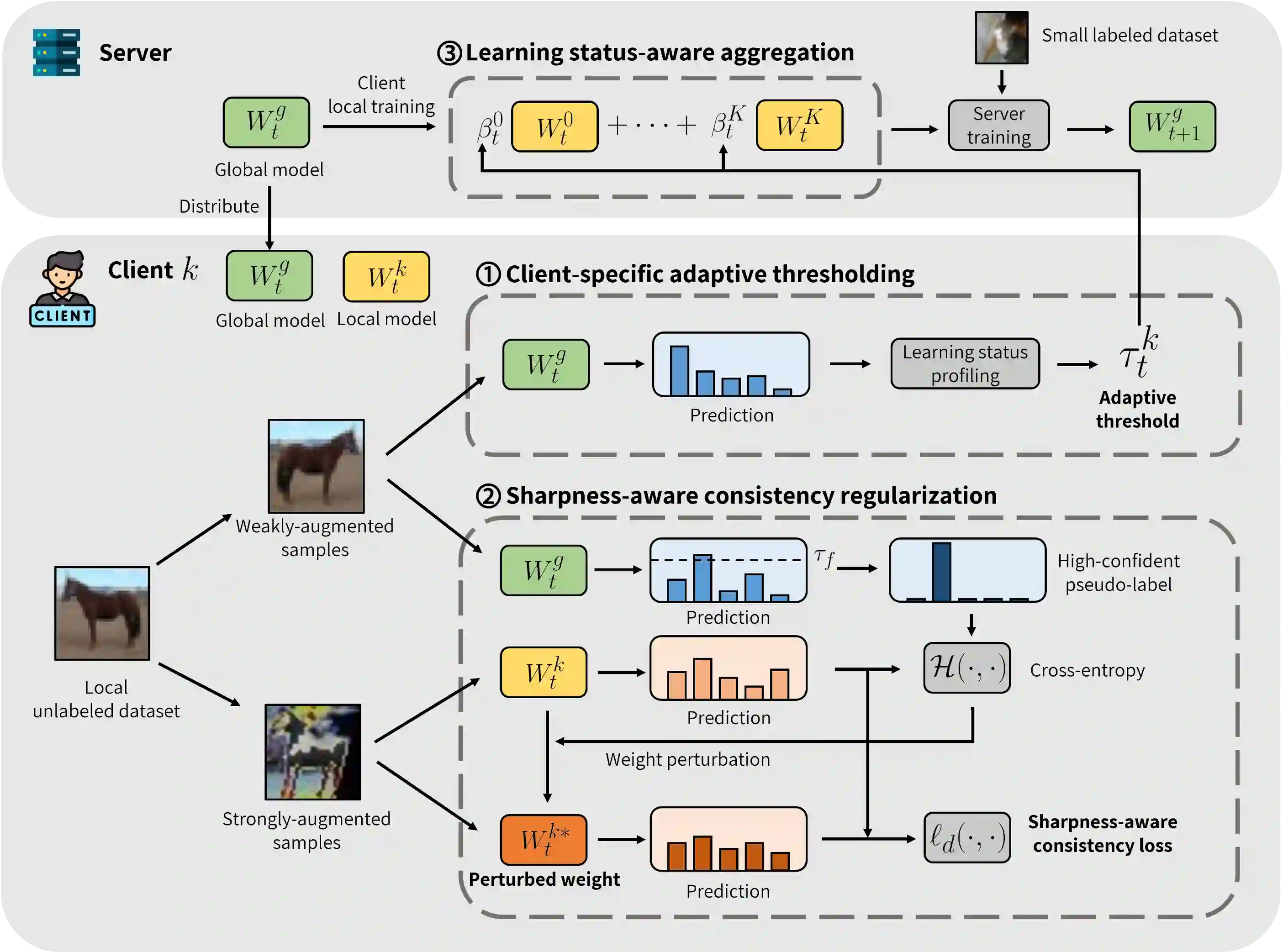
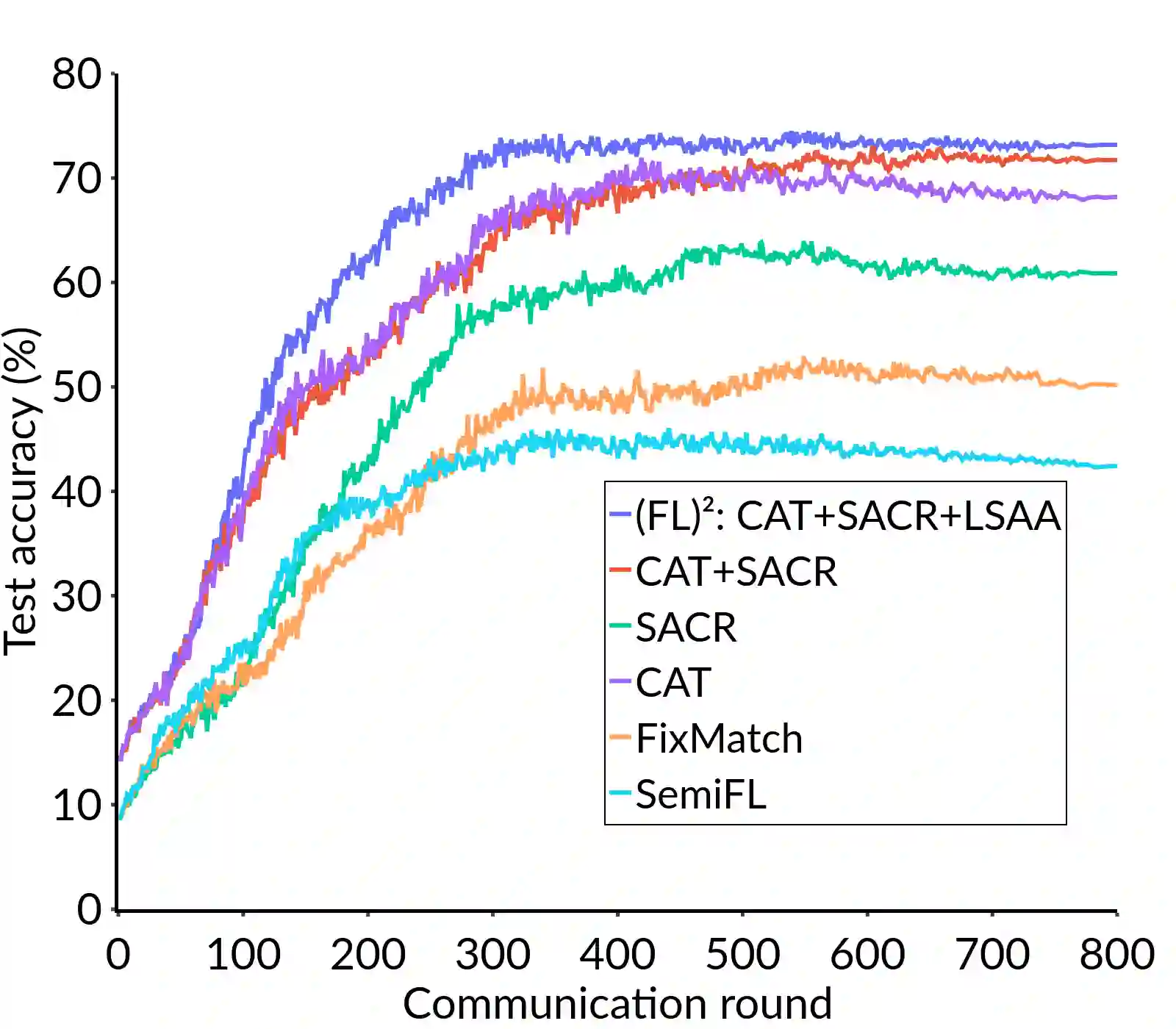
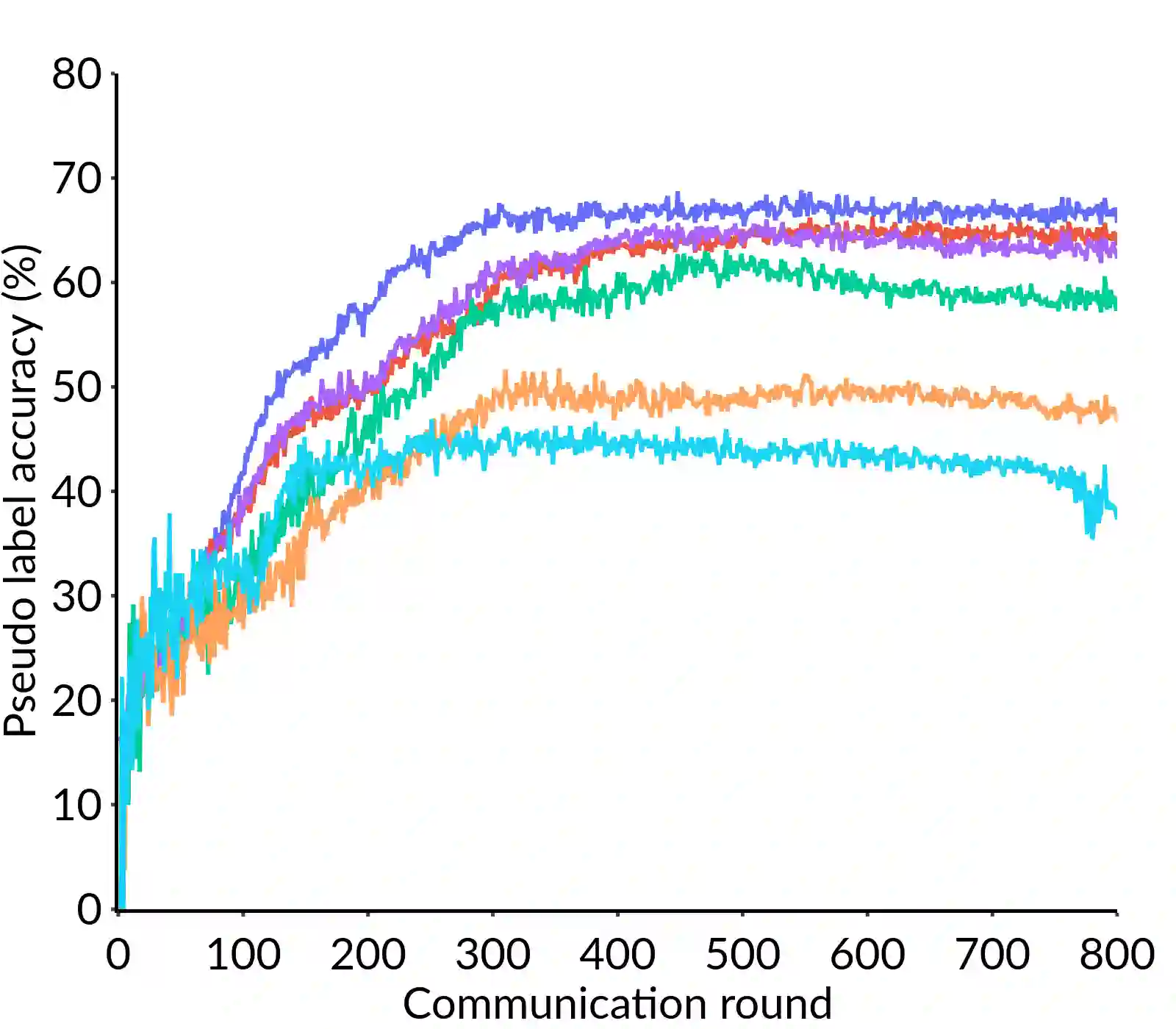
Federated Learning (FL) is a distributed machine learning framework that trains accurate global models while preserving clients' privacy-sensitive data. However, most FL approaches assume that clients possess labeled data, which is often not the case in practice. Federated Semi-Supervised Learning (FSSL) addresses this label deficiency problem, targeting situations where only the server has a small amount of labeled data while clients do not. However, a significant performance gap exists between Centralized Semi-Supervised Learning (SSL) and FSSL. This gap arises from confirmation bias, which is more pronounced in FSSL due to multiple local training epochs and the separation of labeled and unlabeled data. We propose $(FL)^2$, a robust training method for unlabeled clients using sharpness-aware consistency regularization. We show that regularizing the original pseudo-labeling loss is suboptimal, and hence we carefully select unlabeled samples for regularization. We further introduce client-specific adaptive thresholding and learning status-aware aggregation to adjust the training process based on the learning progress of each client. Our experiments on three benchmark datasets demonstrate that our approach significantly improves performance and bridges the gap with SSL, particularly in scenarios with scarce labeled data.
翻译:联邦学习是一种分布式机器学习框架,能够在保护客户端隐私敏感数据的同时训练出准确的全局模型。然而,大多数联邦学习方法假设客户端拥有标注数据,而这在实践中往往不成立。联邦半监督学习旨在解决这一标签稀缺问题,其针对的场景是仅服务器拥有少量标注数据而客户端没有。然而,集中式半监督学习与联邦半监督学习之间存在显著的性能差距。这一差距源于确认偏差,由于多轮本地训练以及标注数据与未标注数据的分离,该偏差在联邦半监督学习中更为突出。我们提出了(FL)$^2$,一种利用锐度感知一致性正则化的鲁棒训练方法,用于未标注客户端。我们证明了直接对原始伪标签损失进行正则化是次优的,因此我们精心选择未标注样本进行正则化。我们进一步引入了客户端特定的自适应阈值和学习状态感知聚合,以根据每个客户端的学习进度调整训练过程。我们在三个基准数据集上的实验表明,我们的方法显著提升了性能,并缩小了与集中式半监督学习的差距,尤其是在标注数据稀缺的场景下。