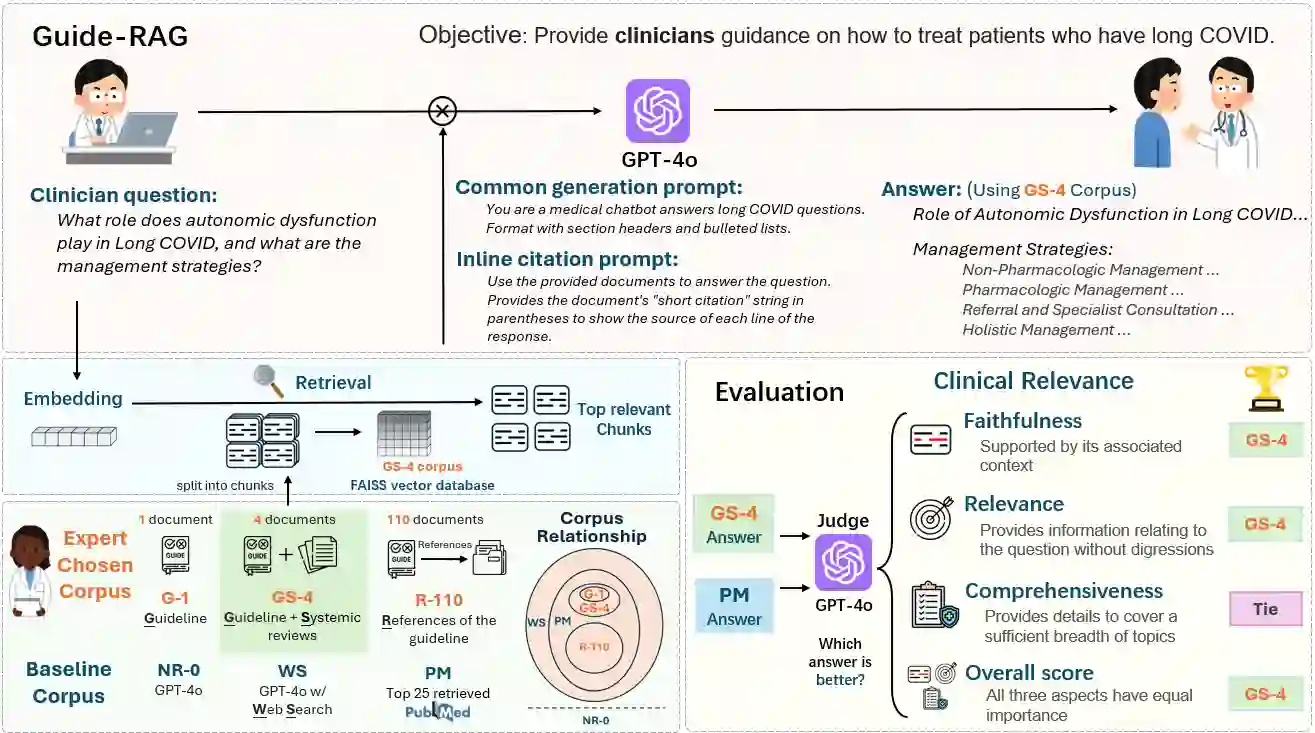
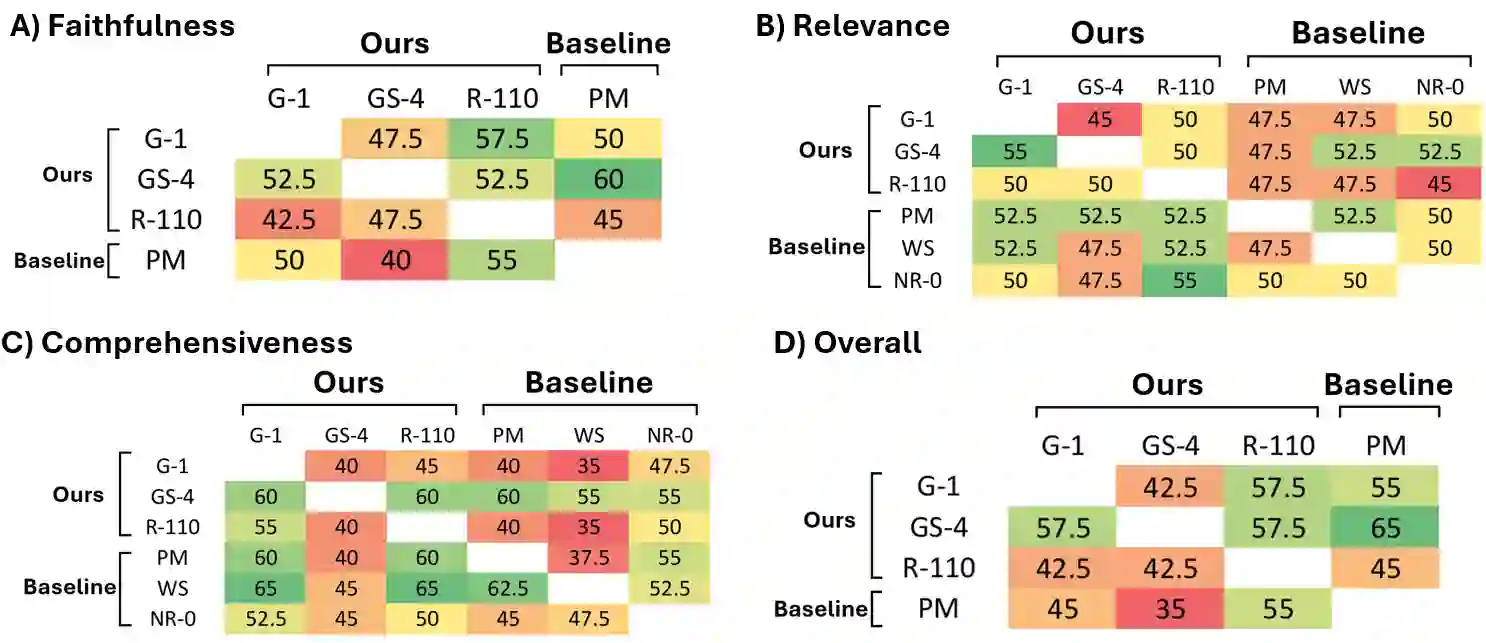
As AI chatbots gain adoption in clinical medicine, developing effective frameworks for complex, emerging diseases presents significant challenges. We developed and evaluated six Retrieval-Augmented Generation (RAG) corpus configurations for Long COVID (LC) clinical question answering, ranging from expert-curated sources to large-scale literature databases. Our evaluation employed an LLM-as-a-judge framework across faithfulness, relevance, and comprehensiveness metrics using LongCOVID-CQ, a novel dataset of expert-generated clinical questions. Our RAG corpus configuration combining clinical guidelines with high-quality systematic reviews consistently outperformed both narrow single-guideline approaches and large-scale literature databases. Our findings suggest that for emerging diseases, retrieval grounded in curated secondary reviews provides an optimal balance between narrow consensus documents and unfiltered primary literature, supporting clinical decision-making while avoiding information overload and oversimplified guidance. We propose Guide-RAG, a chatbot system and accompanying evaluation framework that integrates both curated expert knowledge and comprehensive literature databases to effectively answer LC clinical questions.
翻译:随着AI聊天机器人在临床医学中得到应用,为复杂的新发疾病开发有效框架带来了重大挑战。我们针对长新冠(LC)临床问答,开发并评估了六种检索增强生成(RAG)语料库配置,范围从专家精选来源到大规模文献数据库。我们的评估采用LLM-as-a-judge框架,在忠实性、相关性和全面性指标上,使用由专家生成的新型临床问题数据集LongCOVID-CQ进行测评。我们结合临床指南与高质量系统综述的RAG语料库配置,在各项指标上均持续优于单一狭窄指南方法和大规模文献数据库。我们的研究结果表明,对于新发疾病,基于精选二次综述的检索在狭窄共识文档和未经筛选的一手文献之间提供了最佳平衡,在支持临床决策的同时避免了信息过载和过度简化的指导。我们提出了Guide-RAG,这是一个聊天机器人系统及配套评估框架,它整合了精选的专家知识和全面的文献数据库,以有效回答长新冠临床问题。