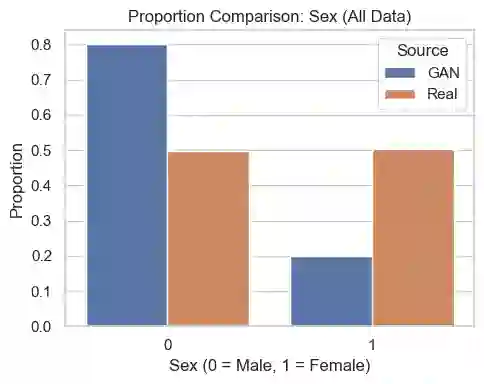
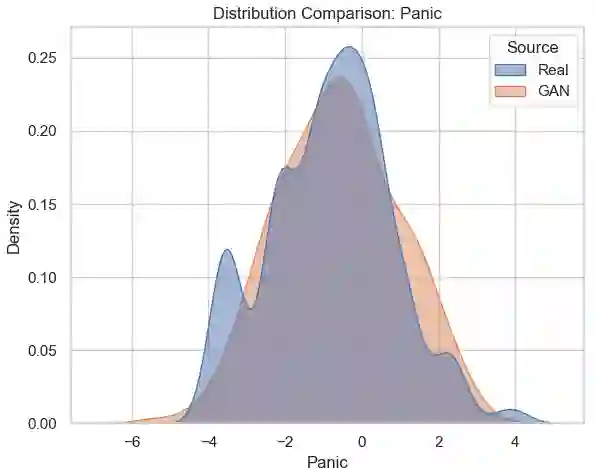
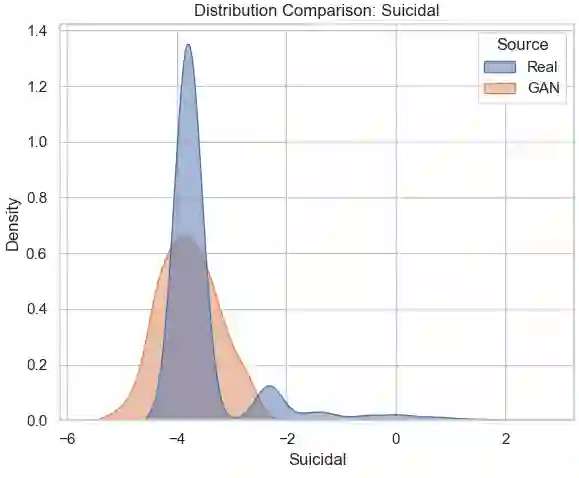
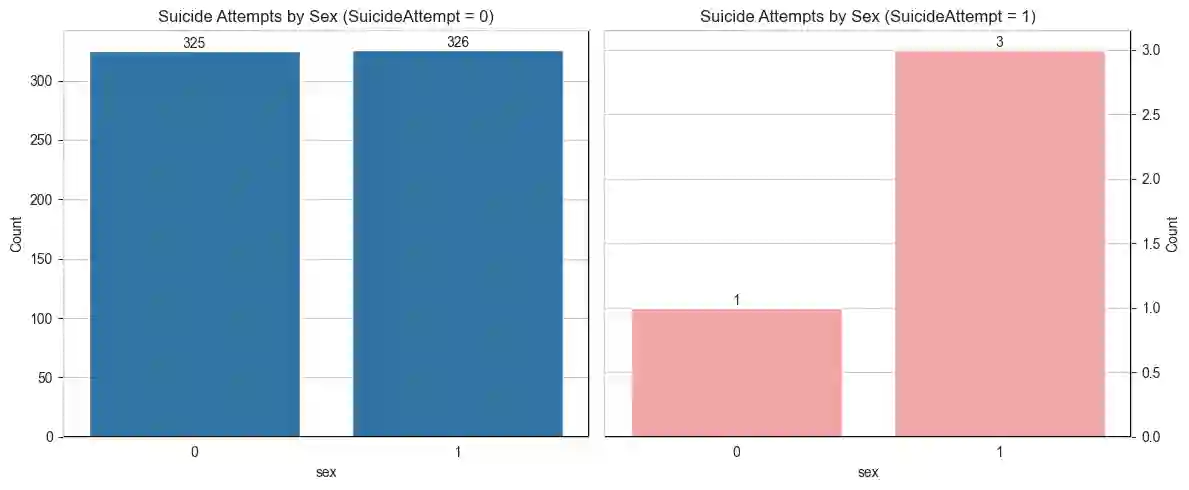
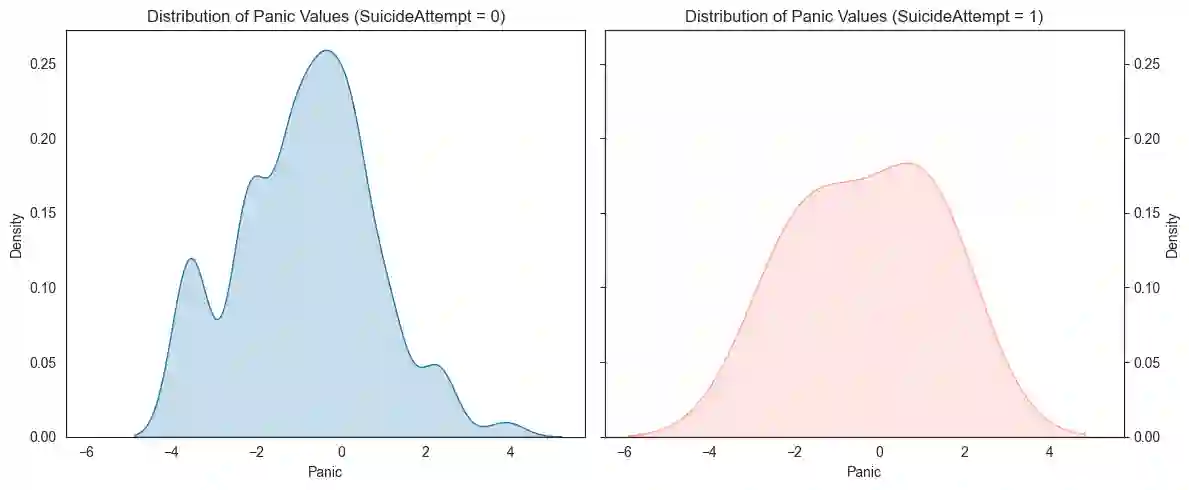
Suicide prediction is the key for prevention, but real data with sufficient positive samples is rare and causes extreme class imbalance. We utilized machine learning (ML) to build the model and deep learning (DL) techniques, like Generative Adversarial Networks (GAN), to generate synthetic data samples to enhance the dataset. The initial dataset contained 656 samples, with only four positive cases, prompting the need for data augmentation. A variety of machine learning models, ranging from interpretable data models to black box algorithmic models, were used. On real test data, Logistic Regression (LR) achieved a weighted precision of 0.99, a weighted recall of 0.85, and a weighted F1 score of 0.91; Random Forest (RF) showed 0.98, 0.99, and 0.99, respectively; and Support Vector Machine (SVM) achieved 0.99, 0.76, and 0.86. LR and SVM correctly identified one suicide attempt case (sensitivity:1.0) and misclassified LR(20) and SVM (31) non-attempts as attempts (specificity: 0.85 & 0.76, respectively). RF identified 0 suicide attempt cases (sensitivity: 0.0) with 0 false positives (specificity: 1.0). These results highlight the models' effectiveness, with GAN playing a key role in generating synthetic data to support suicide prevention modeling efforts.
翻译:自杀预测是预防的关键,但包含足够阳性样本的真实数据稀缺,导致极端类别不平衡。我们利用机器学习(ML)构建模型,并采用深度学习(DL)技术(如生成对抗网络(GAN))生成合成数据样本来增强数据集。初始数据集包含656个样本,其中仅有4个阳性案例,凸显了数据增强的必要性。研究使用了多种机器学习模型,涵盖从可解释的数据模型到黑盒算法模型。在真实测试数据上,逻辑回归(LR)的加权精确率达到0.99,加权召回率为0.85,加权F1分数为0.91;随机森林(RF)的相应指标分别为0.98、0.99和0.99;支持向量机(SVM)则达到0.99、0.76和0.86。LR和SVM正确识别了一例自杀尝试案例(敏感度:1.0),但分别将20例(LR)和31例(SVM)非尝试案例误判为尝试(特异度:0.85和0.76)。RF未能识别出自杀尝试案例(敏感度:0.0),但未产生误报(特异度:1.0)。这些结果证明了模型的有效性,其中GAN在生成合成数据以支持自杀预防建模工作中发挥了关键作用。