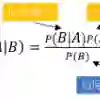
We study supervised classification for datasets with a very large number of input variables. The na\"ive Bayes classifier is attractive for its simplicity, scalability and effectiveness in many real data applications. When the strong na\"ive Bayes assumption of conditional independence of the input variables given the target variable is not valid, variable selection and model averaging are two common ways to improve the performance. In the case of the na\"ive Bayes classifier, the resulting weighting scheme on the models reduces to a weighting scheme on the variables. Here we focus on direct estimation of variable weights in such a weighted na\"ive Bayes classifier. We propose a sparse regularization of the model log-likelihood, which takes into account prior penalization costs related to each input variable. Compared to averaging based classifiers used up until now, our main goal is to obtain parsimonious robust models with less variables and equivalent performance. The direct estimation of the variable weights amounts to a non-convex optimization problem for which we propose and compare several two-stage algorithms. First, the criterion obtained by convex relaxation is minimized using several variants of standard gradient methods. Then, the initial non-convex optimization problem is solved using local optimization methods initialized with the result of the first stage. The various proposed algorithms result in optimization-based weighted na\"ive Bayes classifiers, that are evaluated on benchmark datasets and positioned w.r.t. to a reference averaging-based classifier.
翻译:本研究针对输入变量数量极多的数据集开展监督分类研究。朴素贝叶斯分类器因其简洁性、可扩展性及在实际数据应用中的有效性而备受关注。当给定目标变量时输入变量条件独立这一强朴素贝叶斯假设不成立时,变量选择与模型平均是两种常见的性能改进方法。对于朴素贝叶斯分类器,由此产生的模型加权方案可简化为变量加权方案。本文重点研究在此类加权朴素贝叶斯分类器中直接估计变量权重的方法。我们提出模型对数似然的稀疏正则化方案,该方案综合考虑了与各输入变量相关的先验惩罚成本。相较于现有基于平均的分类器,我们的主要目标是获得具有更少变量且性能相当的简约鲁棒模型。变量权重的直接估计可归结为非凸优化问题,为此我们提出并比较了多种两阶段算法:首先采用标准梯度法的多种变体最小化通过凸松弛获得的准则;随后以第一阶段结果为初始值,运用局部优化方法求解原始非凸优化问题。所提出的多种算法最终形成基于优化的加权朴素贝叶斯分类器,这些分类器在基准数据集上进行了性能评估,并与基于平均的参考分类器进行了对比定位。