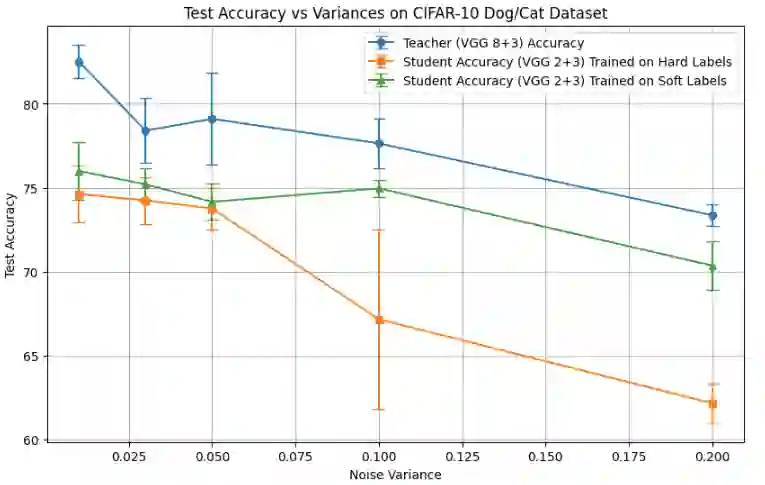
Knowledge distillation, where a small student model learns from a pre-trained large teacher model, has achieved substantial empirical success since the seminal work of \citep{hinton2015distilling}. Despite prior theoretical studies exploring the benefits of knowledge distillation, an important question remains unanswered: why does soft-label training from the teacher require significantly fewer neurons than directly training a small neural network with hard labels? To address this, we first present motivating experimental results using simple neural network models on a binary classification problem. These results demonstrate that soft-label training consistently outperforms hard-label training in accuracy, with the performance gap becoming more pronounced as the dataset becomes increasingly difficult to classify. We then substantiate these observations with a theoretical contribution based on two-layer neural network models. Specifically, we show that soft-label training using gradient descent requires only $O\left(\frac{1}{\gamma^2 \epsilon}\right)$ neurons to achieve a classification loss averaged over epochs smaller than some $\epsilon > 0$, where $\gamma$ is the separation margin of the limiting kernel. In contrast, hard-label training requires $O\left(\frac{1}{\gamma^4} \cdot \ln\left(\frac{1}{\epsilon}\right)\right)$ neurons, as derived from an adapted version of the gradient descent analysis in \citep{ji2020polylogarithmic}. This implies that when $\gamma \leq \epsilon$, i.e., when the dataset is challenging to classify, the neuron requirement for soft-label training can be significantly lower than that for hard-label training. Finally, we present experimental results on deep neural networks, further validating these theoretical findings.
翻译:知识蒸馏,即小型学生模型从预训练的大型教师模型学习,自\citep{hinton2015distilling}的开创性工作以来已取得显著的实证成功。尽管先前的理论研究探讨了知识蒸馏的优势,一个重要问题仍未得到解答:为何来自教师的软标签训练所需的神经元数量远少于直接用硬标签训练小型神经网络?为此,我们首先在二元分类问题上使用简单的神经网络模型展示激励性的实验结果。这些结果表明,软标签训练在准确率上始终优于硬标签训练,且随着数据集分类难度增加,性能差距愈发显著。随后,我们基于两层神经网络模型提出理论贡献以证实这些观察。具体而言,我们证明使用梯度下降的软标签训练仅需 $O\left(\frac{1}{\gamma^2 \epsilon}\right)$ 个神经元即可实现历元平均分类损失小于某个 $\epsilon > 0$,其中 $\gamma$ 是极限核的分离间隔。相比之下,硬标签训练需要 $O\left(\frac{1}{\gamma^4} \cdot \ln\left(\frac{1}{\epsilon}\right)\right)$ 个神经元,此结论源自对\citep{ji2020polylogarithmic}中梯度下降分析的改编版本。这意味着当 $\gamma \leq \epsilon$ 时,即当数据集难以分类时,软标签训练所需的神经元数量可显著低于硬标签训练。最后,我们在深度神经网络上展示实验结果,进一步验证了这些理论发现。