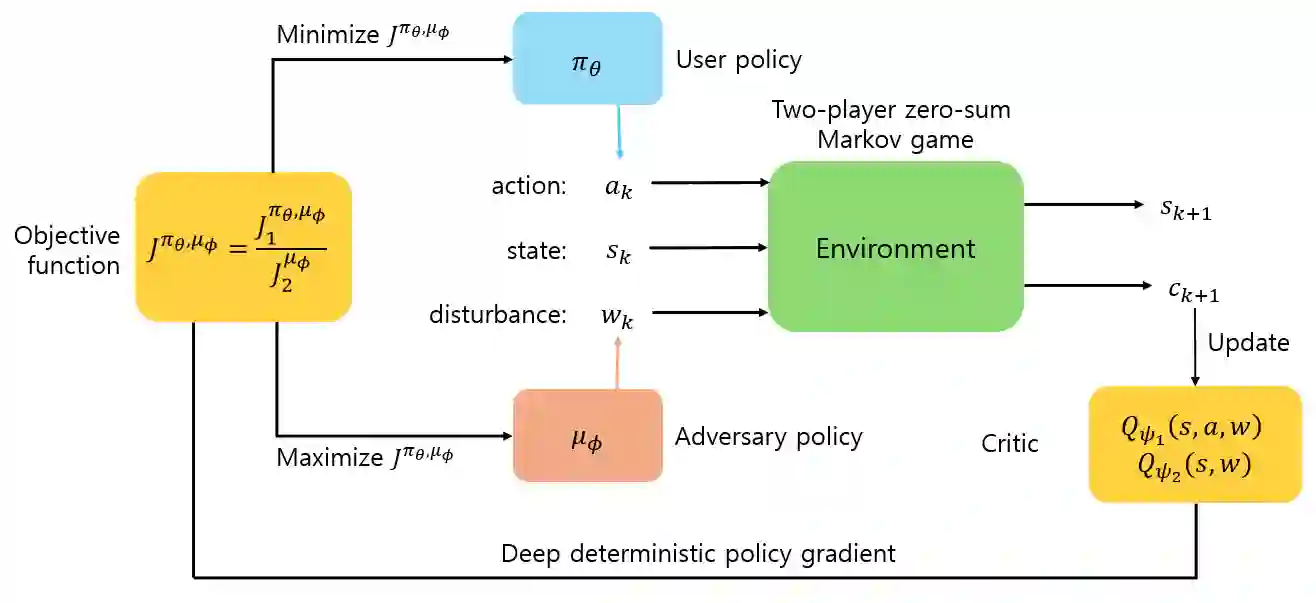
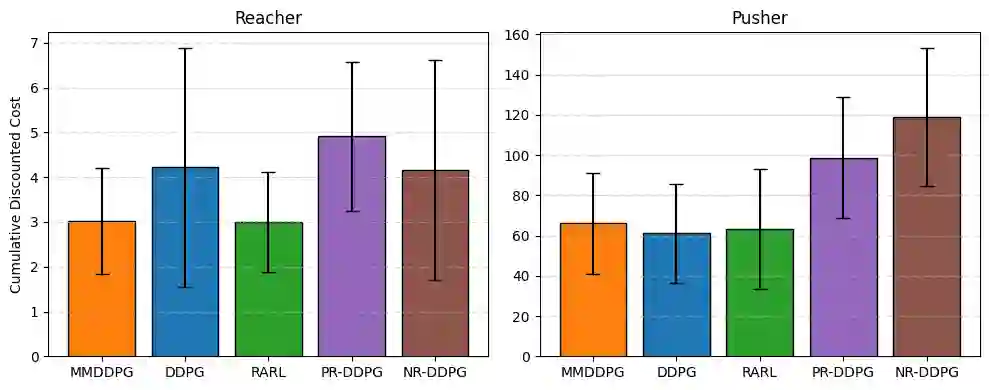
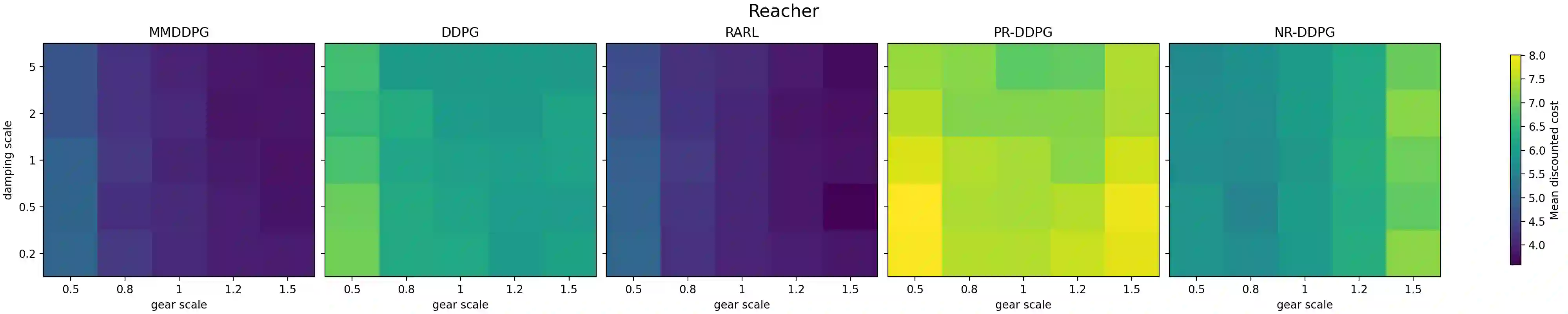
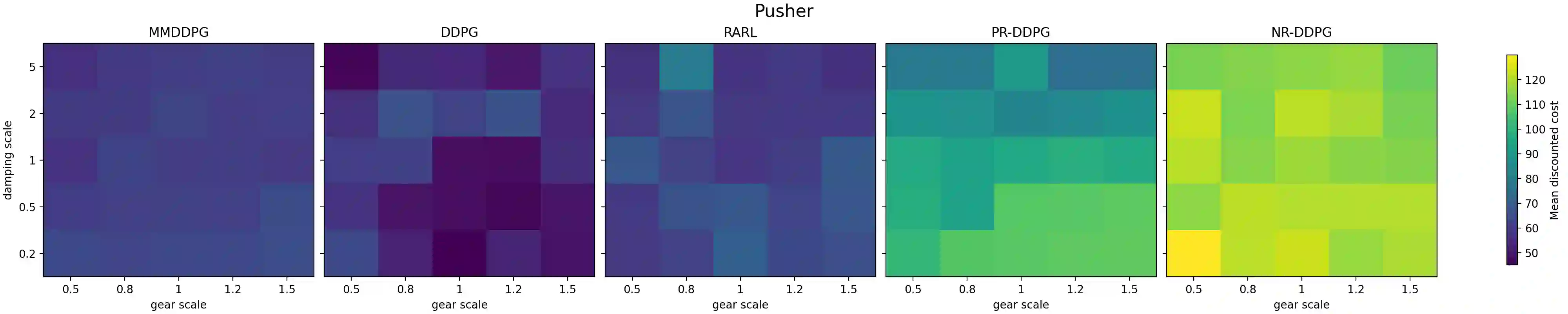
Reinforcement learning (RL) has achieved remarkable success in a wide range of control and decision-making tasks. However, RL agents often exhibit unstable or degraded performance when deployed in environments subject to unexpected external disturbances and model uncertainties. Consequently, ensuring reliable performance under such conditions remains a critical challenge. In this paper, we propose minimax deep deterministic policy gradient (MMDDPG), a framework for learning disturbance-resilient policies in continuous control tasks. The training process is formulated as a minimax optimization problem between a user policy and an adversarial disturbance policy. In this problem, the user learns a robust policy that minimizes the objective function, while the adversary generates disturbances that maximize it. To stabilize this interaction, we introduce a fractional objective that balances task performance and disturbance magnitude. This objective prevents excessively aggressive disturbances and promotes robust learning. Experimental evaluations in MuJoCo environments demonstrate that the proposed MMDDPG achieves significantly improved robustness against both external force perturbations and model parameter variations.
翻译:强化学习(RL)在广泛的控制与决策任务中取得了显著成功。然而,当RL智能体部署于存在意外外部干扰和模型不确定性的环境中时,其性能常表现出不稳定或退化。因此,确保在此类条件下的可靠性能仍是一个关键挑战。本文提出极小极大深度确定性策略梯度(MMDDPG),这是一个用于在连续控制任务中学习抗干扰策略的框架。训练过程被表述为用户策略与对抗性干扰策略之间的极小极大优化问题。在此问题中,用户学习一个最小化目标函数的鲁棒策略,而对抗者则生成最大化该目标函数的干扰。为稳定此交互过程,我们引入了一个平衡任务性能与干扰强度的分数目标。该目标可防止产生过度激进的干扰,并促进鲁棒学习。在MuJoCo环境中的实验评估表明,所提出的MMDDPG在面对外部力扰动和模型参数变化时,均实现了显著提升的鲁棒性。