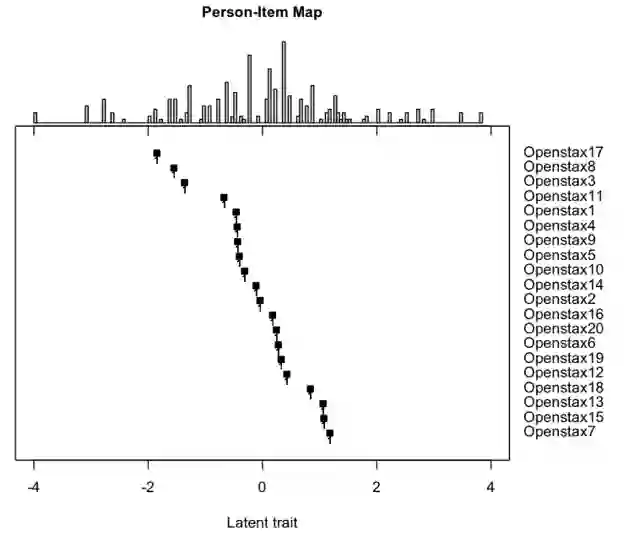
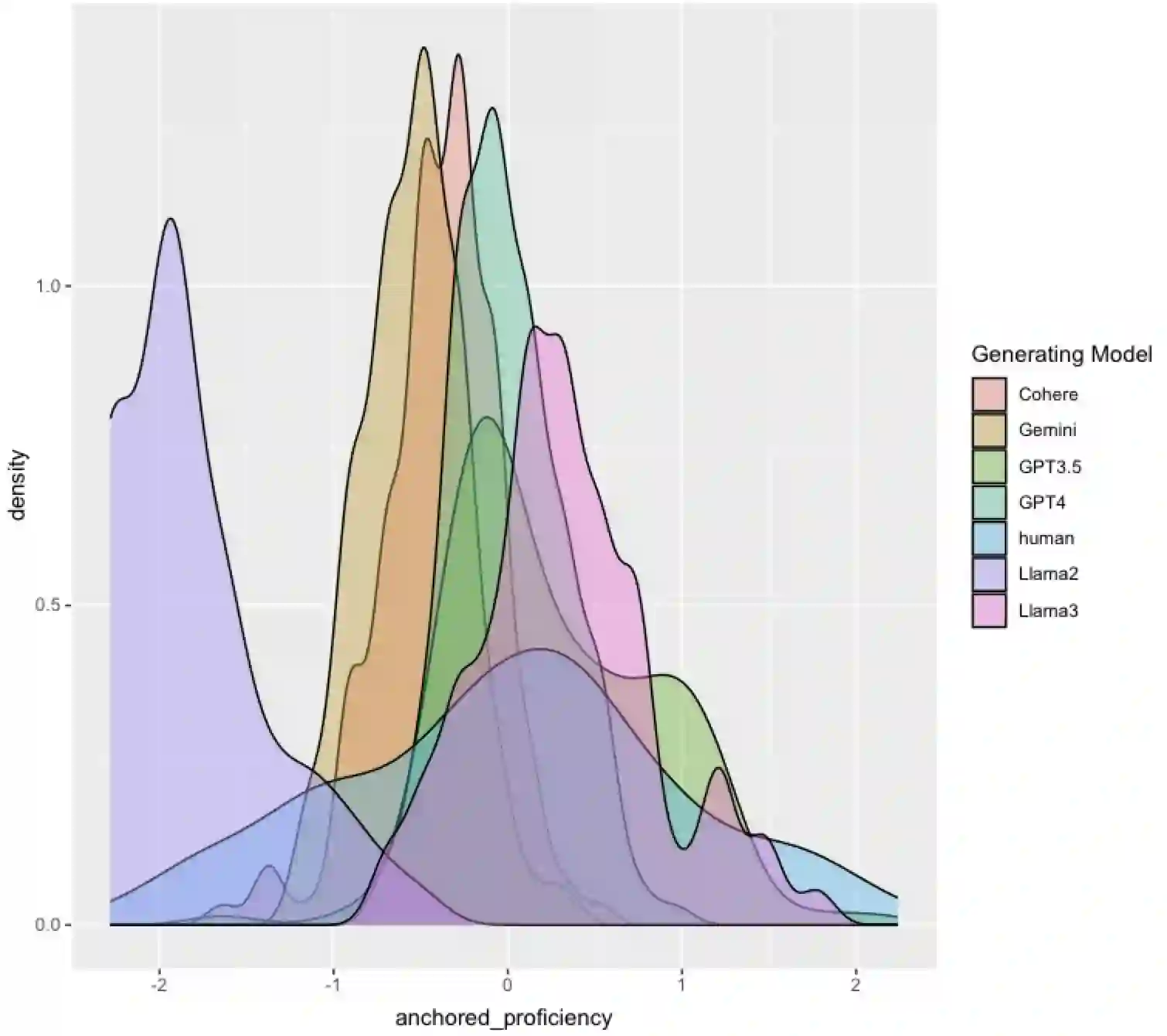
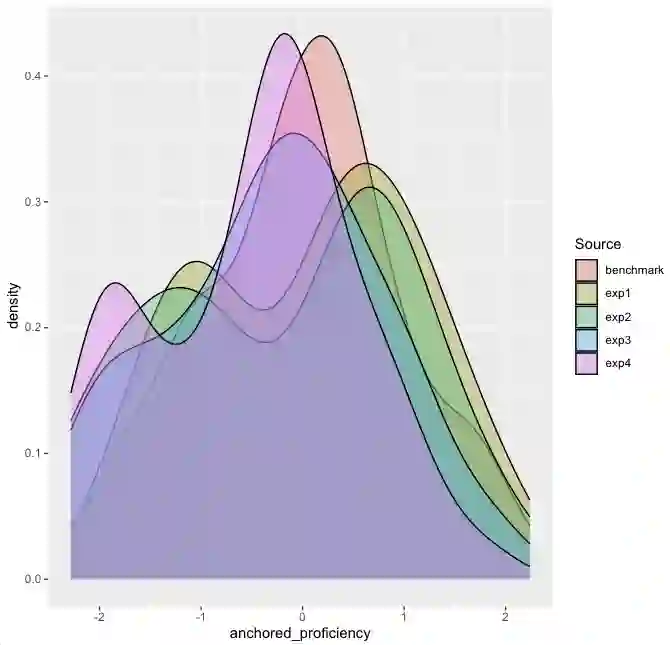
Effective educational measurement relies heavily on the curation of well-designed item pools (i.e., possessing the right psychometric properties). However, item calibration is time-consuming and costly, requiring a sufficient number of respondents for the response process. We explore using six different LLMs (GPT-3.5, GPT-4, Llama 2, Llama 3, Gemini-Pro, and Cohere Command R Plus) and various combinations of them using sampling methods to produce responses with psychometric properties similar to human answers. Results show that some LLMs have comparable or higher proficiency in College Algebra than college students. No single LLM mimics human respondents due to narrow proficiency distributions, but an ensemble of LLMs can better resemble college students' ability distribution. The item parameters calibrated by LLM-Respondents have high correlations (e.g. > 0.8 for GPT-3.5) compared to their human calibrated counterparts, and closely resemble the parameters of the human subset (e.g. 0.02 Spearman correlation difference). Several augmentation strategies are evaluated for their relative performance, with resampling methods proving most effective, enhancing the Spearman correlation from 0.89 (human only) to 0.93 (augmented human).
翻译:有效的教育测量在很大程度上依赖于精心设计的项目池(即具备恰当的心理测量特性)。然而,项目校准过程耗时且成本高昂,需要足够数量的受访者参与作答过程。本研究探索使用六种不同的大型语言模型(GPT-3.5、GPT-4、Llama 2、Llama 3、Gemini-Pro和Cohere Command R Plus)以及通过抽样方法构建的多种模型组合,以生成具有与人类答案相似心理测量特性的作答。结果表明,部分LLM在大学代数领域的熟练程度与大学生相当甚至更高。由于熟练度分布范围较窄,单个LLM无法完全模拟人类受访者,但LLM组合能够更好地拟合大学生的能力分布。通过LLM-受访者校准得到的项目参数与人类校准参数具有高度相关性(例如GPT-3.5的相关系数>0.8),且与人类子集的参数高度接近(例如斯皮尔曼相关系数差异仅为0.02)。研究评估了多种增强策略的相对性能,其中重采样方法被证明最为有效,能将斯皮尔曼相关系数从0.89(仅人类数据)提升至0.93(增强后的人类数据)。