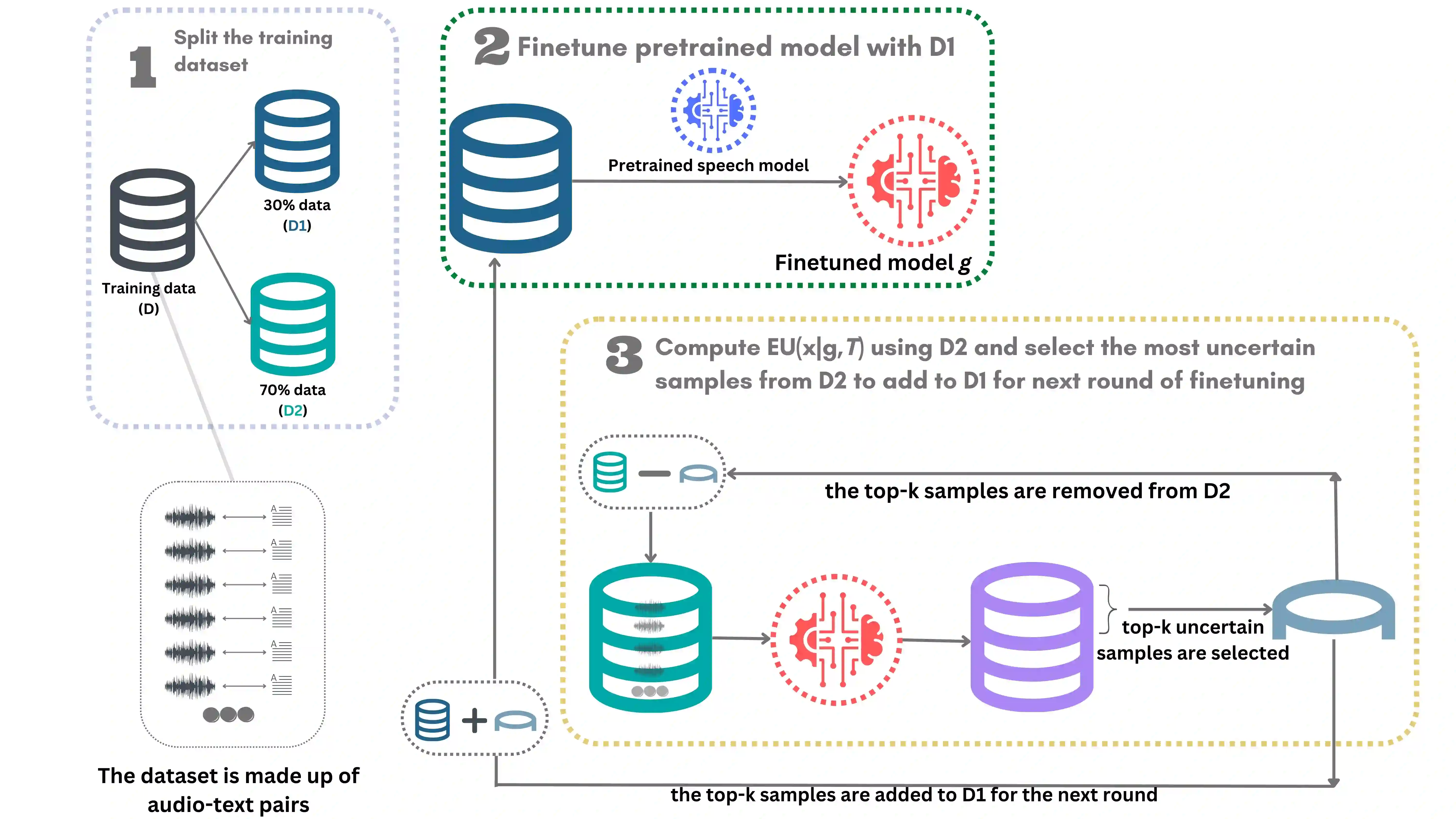
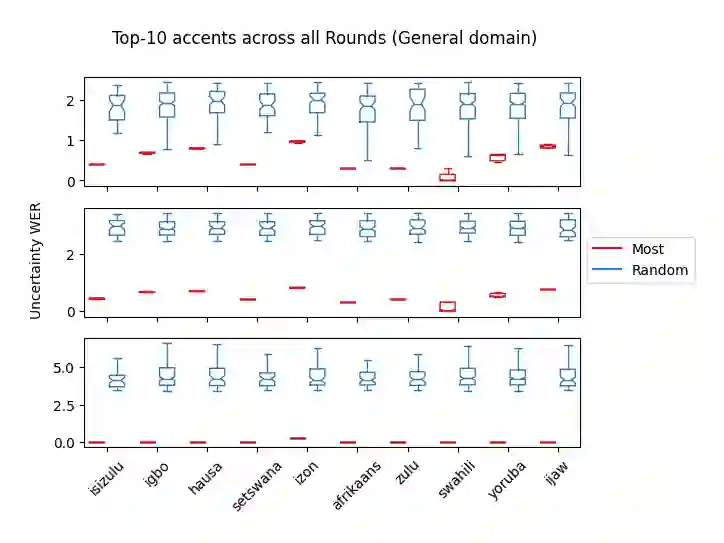
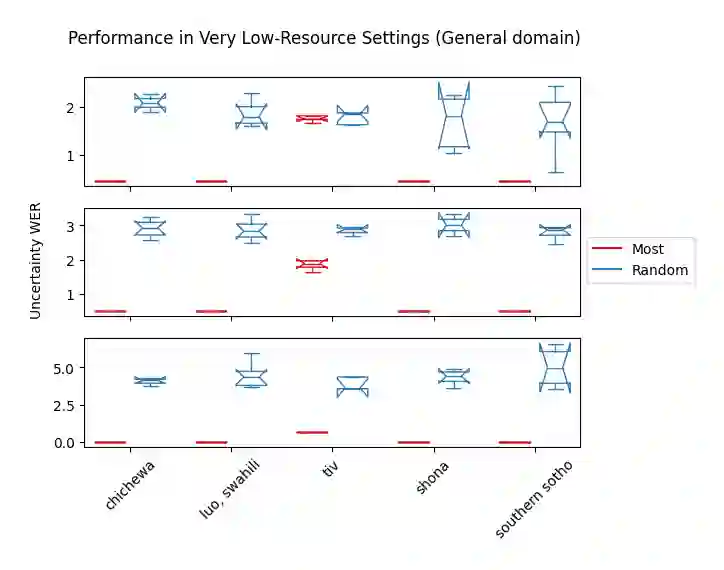
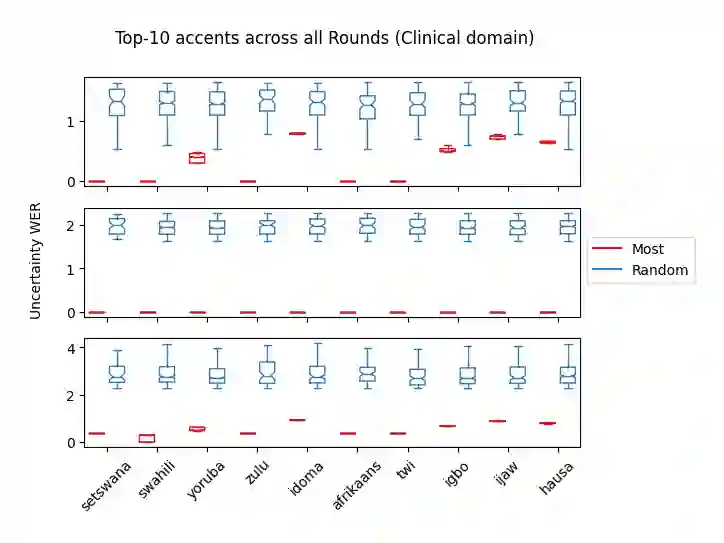
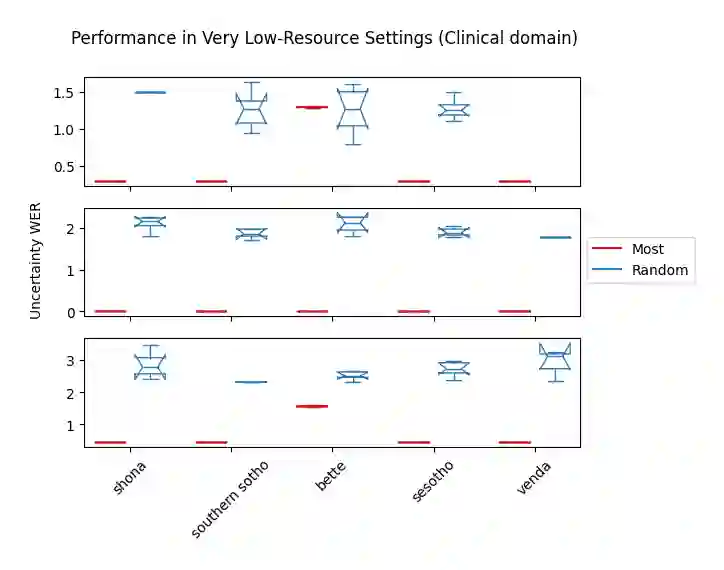
Accents play a pivotal role in shaping human communication, enhancing our ability to convey and comprehend messages with clarity and cultural nuance. While there has been significant progress in Automatic Speech Recognition (ASR), African-accented English ASR has been understudied due to a lack of training datasets, which are often expensive to create and demand colossal human labor. Combining several active learning paradigms and the core-set approach, we propose a new multi-rounds adaptation process that uses epistemic uncertainty to automate the annotation process, significantly reducing the associated costs and human labor. This novel method streamlines data annotation and strategically selects data samples that contribute most to model uncertainty, thereby enhancing training efficiency. We define a new metric called U-WER to track model adaptation to hard accents. We evaluate our approach across several domains, datasets, and high-performing speech models. Our results show that our approach leads to a 69.44\% WER improvement while requiring on average 45\% less data than established baselines. Our approach also improves out-of-distribution generalization for very low-resource accents, demonstrating its viability for building generalizable ASR models in the context of accented African ASR. We open-source the code here: https://github.com/bonaventuredossou/active_learning_african_asr
翻译:口音在塑造人类交流中起着关键作用,它增强了我们清晰传达和理解信息的能力,并承载着文化细微差别。尽管自动语音识别(ASR)领域已取得显著进展,但由于缺乏训练数据集,非洲口音英语的ASR研究仍显不足,而创建这些数据集通常成本高昂且需要大量人力。结合多种主动学习范式和核心集方法,我们提出了一种新的多轮自适应过程,利用认知不确定性来自动化标注流程,显著降低了相关成本和人力需求。这种新颖方法不仅简化了数据标注,还策略性地选择了对模型不确定性贡献最大的数据样本,从而提高了训练效率。我们定义了一种名为U-WER的新指标,用于追踪模型对困难口音的自适应过程。我们在多个领域、数据集和高性能语音模型上评估了我们的方法。结果表明,与现有基线相比,我们的方法在平均仅需45%数据量的情况下,实现了69.44%的词错误率(WER)提升。该方法还改善了极低资源口音的分布外泛化能力,证明了其在构建非洲口音ASR可泛化模型方面的可行性。我们在以下地址开源了代码:https://github.com/bonaventuredossou/active_learning_african_asr