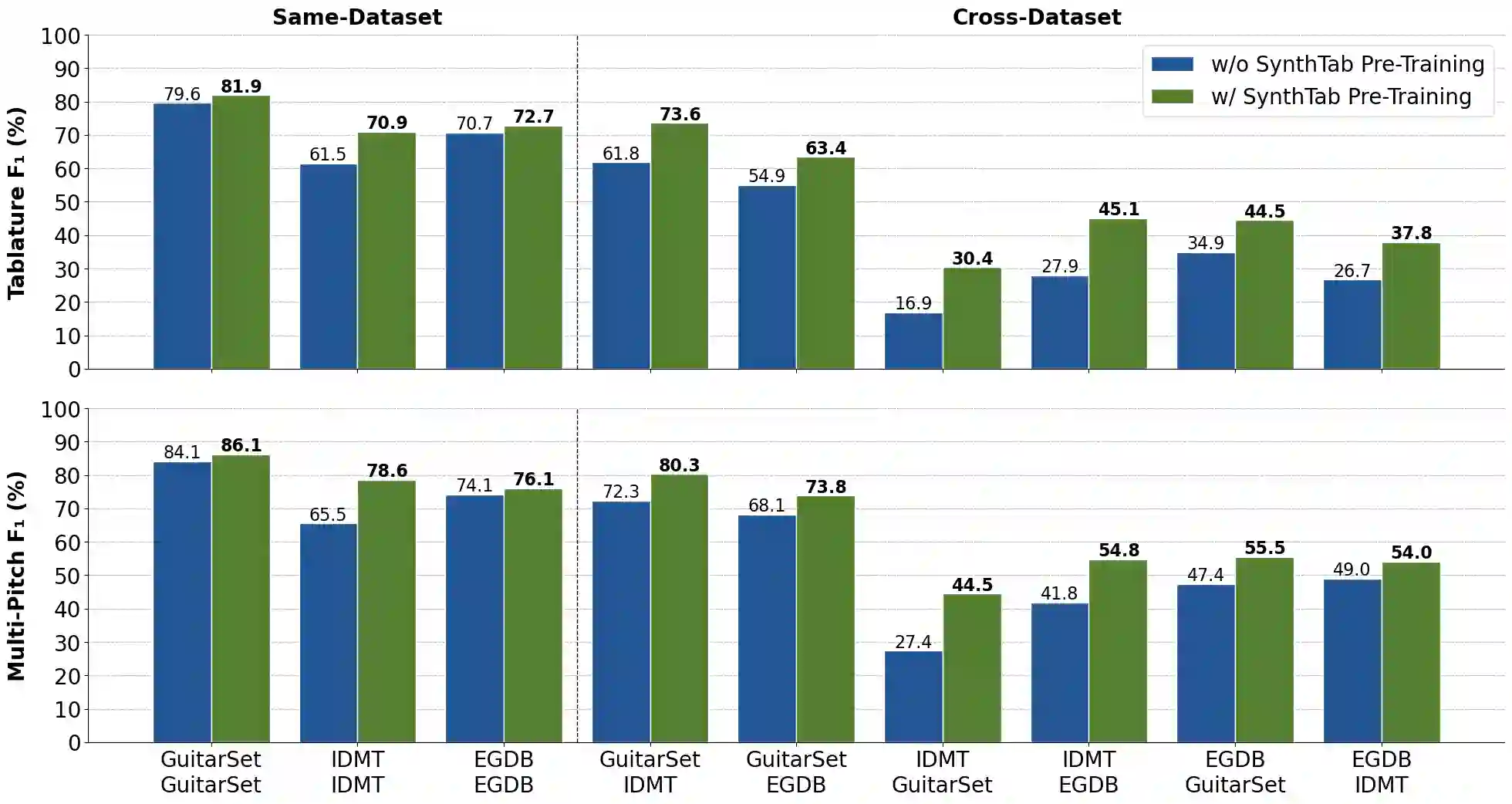
Guitar tablature is a form of music notation widely used among guitarists. It captures not only the musical content of a piece, but also its implementation and ornamentation on the instrument. Guitar Tablature Transcription (GTT) is an important task with broad applications in music education, composition, and entertainment. Existing GTT datasets are quite limited in size and scope, rendering models trained on them prone to overfitting and incapable of generalizing to out-of-domain data. In order to address this issue, we present a methodology for synthesizing large-scale GTT audio using commercial acoustic and electric guitar plugins. We procure SynthTab, a dataset derived from DadaGP, which is a vast and diverse collection of richly annotated symbolic tablature. The proposed synthesis pipeline produces audio which faithfully adheres to the original fingerings and a subset of techniques specified in the tablature, and covers multiple guitars and styles for each track. Experiments show that pre-training a baseline GTT model on SynthTab can improve transcription performance when fine-tuning and testing on an individual dataset. More importantly, cross-dataset experiments show that pre-training significantly mitigates issues with overfitting.
翻译:吉他指法谱是一种在吉他手中广泛使用的音乐记谱形式。它不仅记录了乐曲的音乐内容,还包含了在乐器上的演奏手法与装饰音细节。吉他指法谱转写(GTT)是一项具有重要意义的任务,广泛应用于音乐教育、作曲和娱乐领域。现有GTT数据集在规模和范围上都非常有限,导致在此类数据上训练的模型容易过拟合,且无法泛化到域外数据。为解决这一问题,我们提出了一种利用商用原声吉他及电吉他插件合成大规模GTT音频的方法。我们构建了SynthTab数据集,该数据集源于DadaGP——一个包含大量丰富标注符号指法谱的多样化集合。所提出的合成流水线能生成忠实遵循原始指法及指法谱中指定部分技法的音频,并覆盖每首曲目的多种吉他类型与演奏风格。实验表明,在SynthTab上预训练基线GTT模型后,在单独数据集上进行微调与测试时,转写性能得到提升。更重要的是,跨数据集实验证明,预训练能显著缓解过拟合问题。