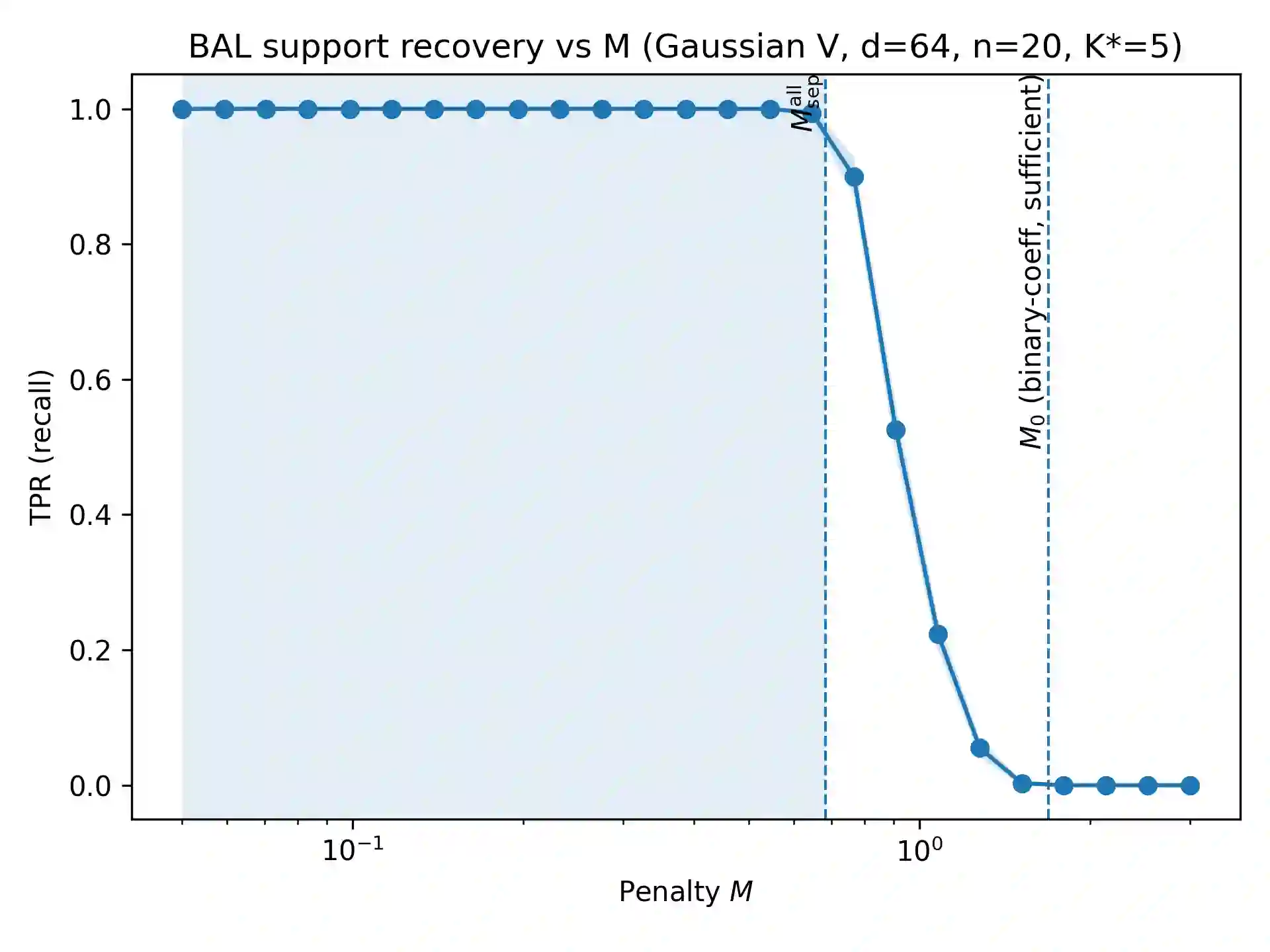
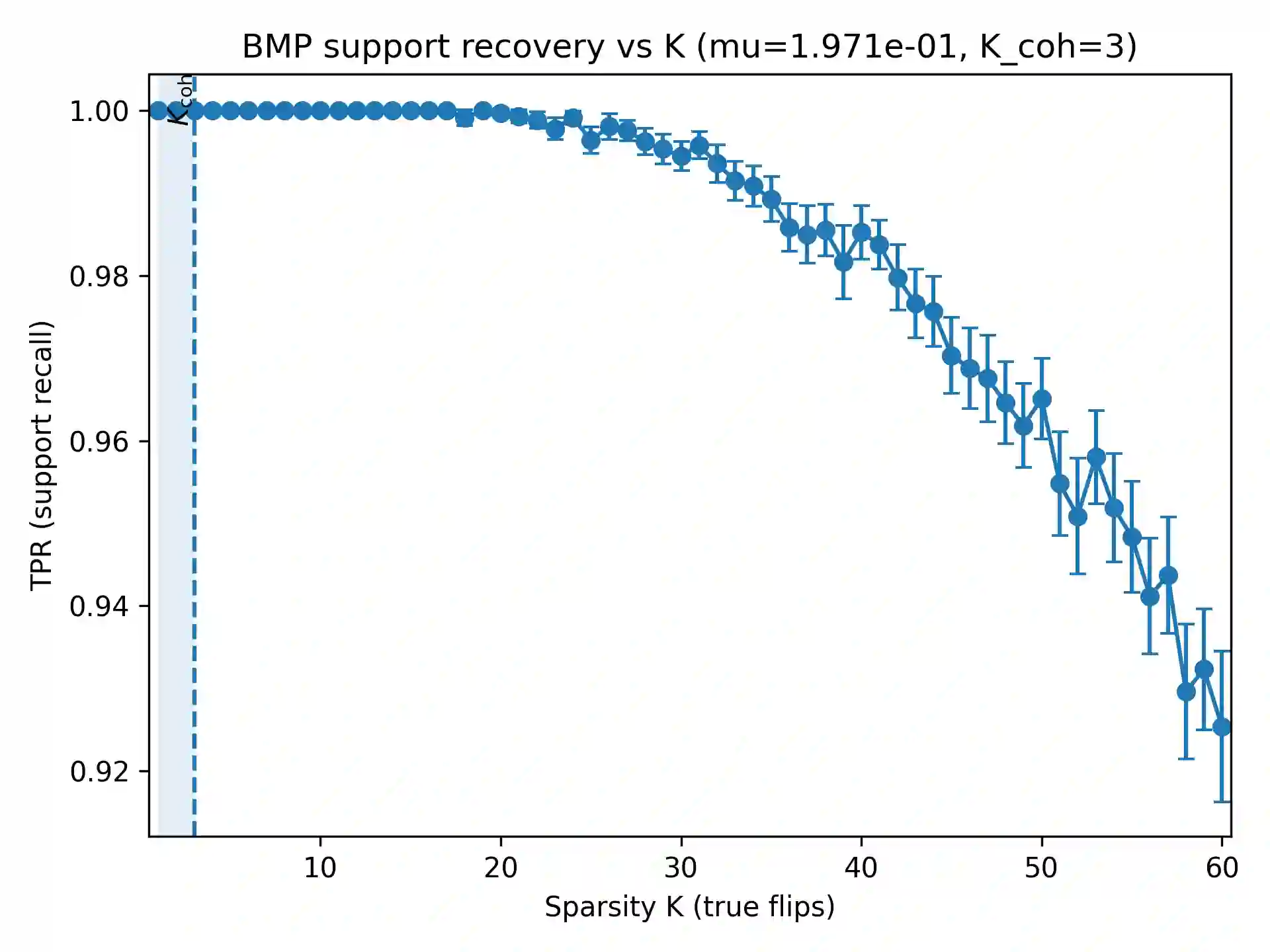
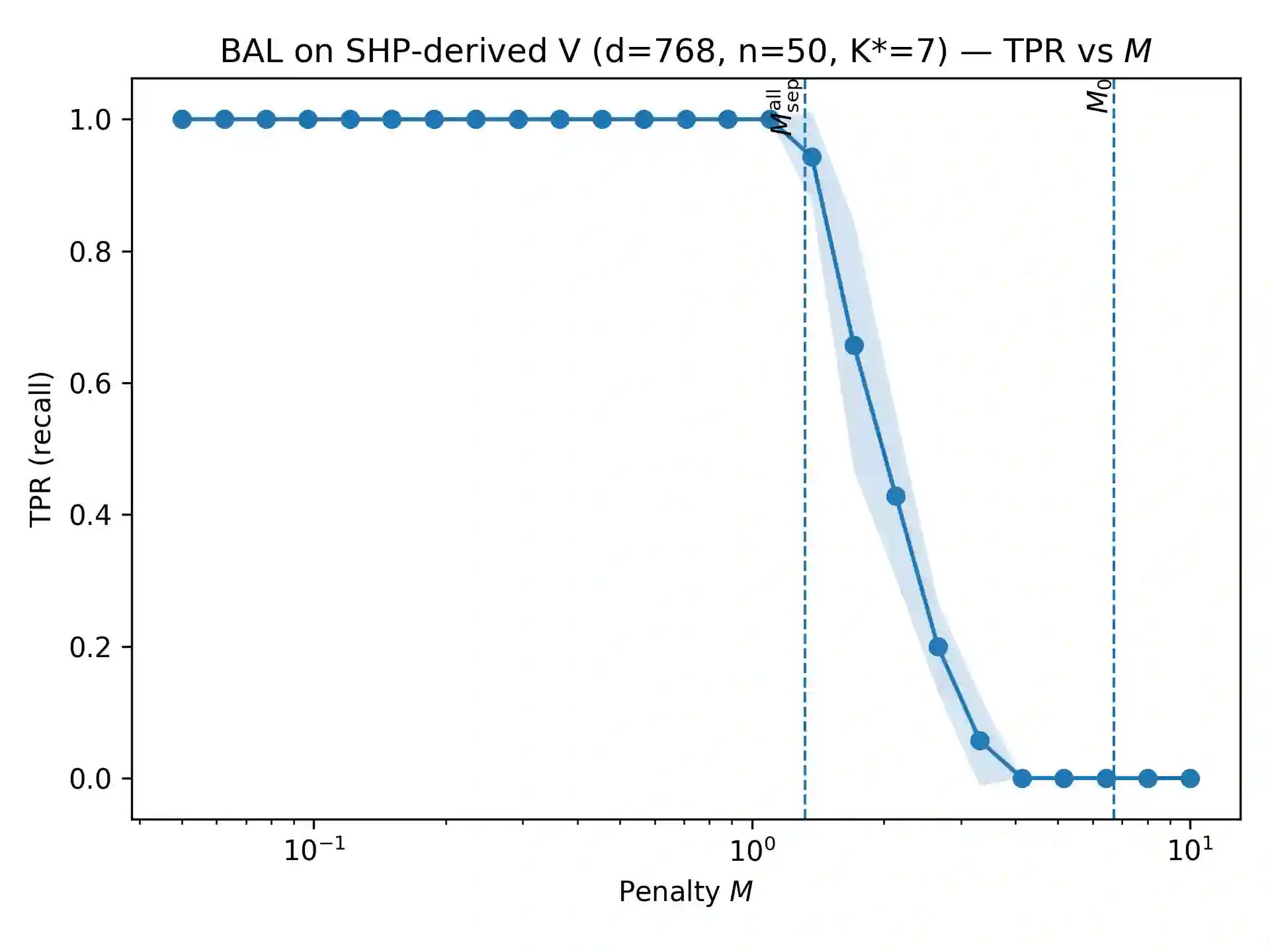
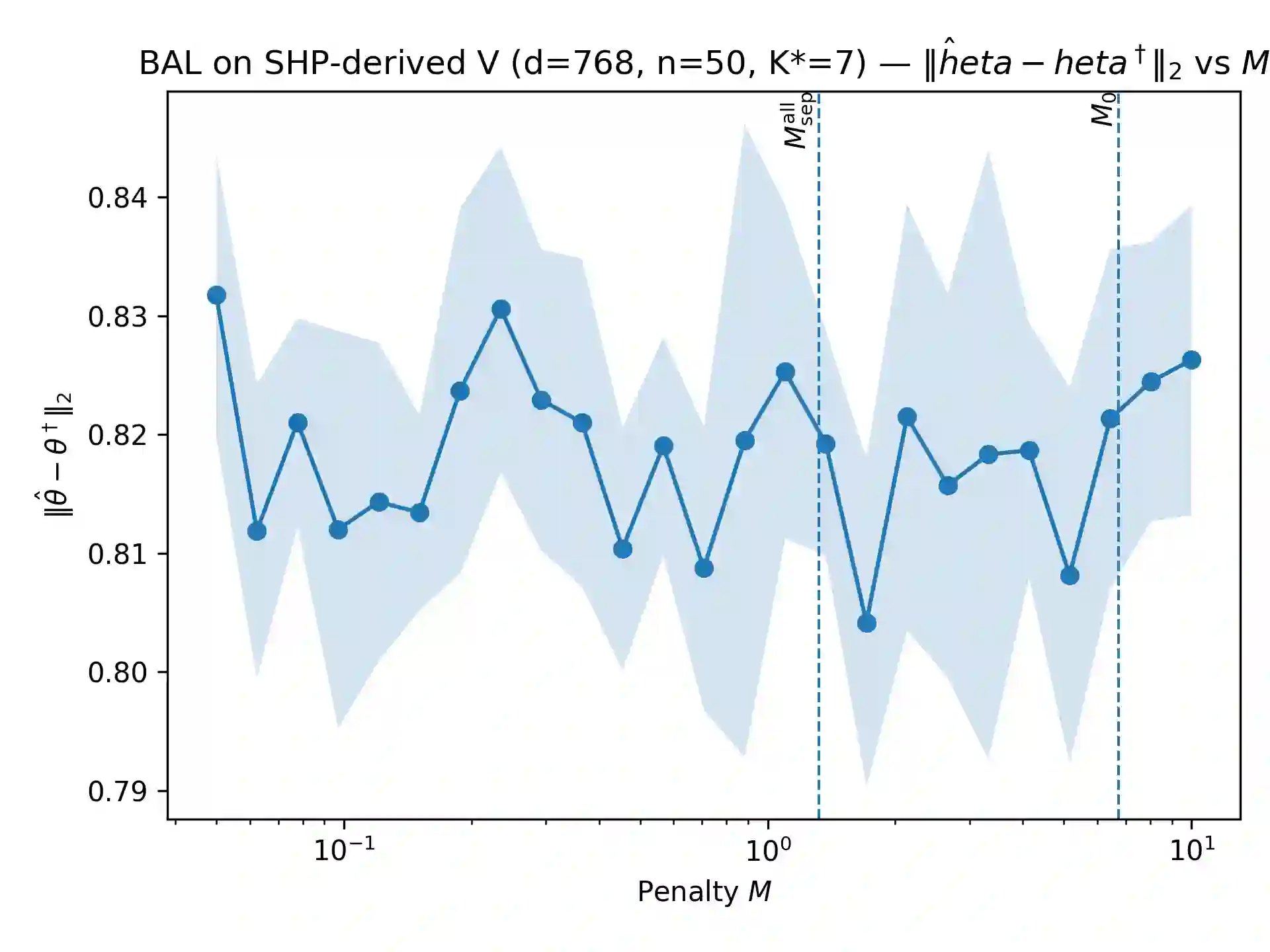
Offline Reinforcement Learning from Human Feedback (RLHF) pipelines such as Direct Preference Optimization (DPO) train on a pre-collected preference dataset, which makes them vulnerable to preference poisoning attack. We study label flip attacks against log-linear DPO. We first illustrate that flipping one preference label induces a parameter-independent shift in the DPO gradient. Using this key property, we can then convert the targeted poisoning problem into a structured binary sparse approximation problem. To solve this problem, we develop two attack methods: Binary-Aware Lattice Attack (BAL-A) and Binary Matching Pursuit Attack (BMP-A). BAL-A embeds the binary flip selection problem into a binary-aware lattice and applies Lenstra-Lenstra-Lovász reduction and Babai's nearest plane algorithm; we provide sufficient conditions that enforce binary coefficients and recover the minimum-flip objective. BMP-A adapts binary matching pursuit to our non-normalized gradient dictionary and yields coherence-based recovery guarantees and robustness (impossibility) certificates for $K$-flip budgets. Experiments on synthetic dictionaries and the Stanford Human Preferences dataset validate the theory and highlight how dictionary geometry governs attack success.
翻译:离线人类反馈强化学习(RLHF)流水线(如直接偏好优化,DPO)依赖预先收集的偏好数据集进行训练,因此容易遭受偏好投毒攻击。本文研究了对数线性DPO的标签翻转攻击。我们首先证明,翻转一个偏好标签会导致DPO梯度产生与参数无关的偏移。基于这一关键特性,可将目标定向投毒问题转化为结构化二元稀疏逼近问题。为解决该问题,我们提出两种攻击方法:二元感知格点攻击(BAL-A)和二元匹配追踪攻击(BMP-A)。BAL-A将二元翻转选择问题嵌入二元感知格点,并运用Lenstra-Lenstra-Lovász归约与Babai最近平面算法;我们给出了强制二元系数并还原最小翻转目标的充分条件。BMP-A将二元匹配追踪适配至非归一化梯度字典,为$K$翻转预算提供基于相干性的恢复保证和鲁棒性(不可行性)认证。在合成字典与斯坦福人类偏好数据集上的实验验证了理论分析,并揭示了字典几何特性如何决定攻击成功率。