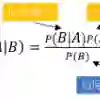
This study evaluates the effectiveness of different feature extraction techniques and classification algorithms in detecting spam messages within SMS data. We analyzed six classifiers Naive Bayes, K-Nearest Neighbors, Support Vector Machines, Linear Discriminant Analysis, Decision Trees, and Deep Neural Networks using two feature extraction methods: bag-of-words and TF-IDF. The primary objective was to determine the most effective classifier-feature combination for SMS spam detection. Our research offers two main contributions: first, by systematically examining various classifier and feature extraction pairings, and second, by empirically evaluating their ability to distinguish spam messages. Our results demonstrate that the TF-IDF method consistently outperforms the bag-of-words approach across all six classifiers. Specifically, Naive Bayes with TF-IDF achieved the highest accuracy of 96.2%, with a precision of 0.976 for non-spam and 0.754 for spam messages. Similarly, Support Vector Machines with TF-IDF exhibited an accuracy of 94.5%, with a precision of 0.926 for non-spam and 0.891 for spam. Deep Neural Networks using TF-IDF yielded an accuracy of 91.0%, with a recall of 0.991 for non-spam and 0.415 for spam messages. In contrast, classifiers such as K-Nearest Neighbors, Linear Discriminant Analysis, and Decision Trees showed weaker performance, regardless of the feature extraction method employed. Furthermore, we observed substantial variability in classifier effectiveness depending on the chosen feature extraction technique. Our findings emphasize the significance of feature selection in SMS spam detection and suggest that TF-IDF, when paired with Naive Bayes, Support Vector Machines, or Deep Neural Networks, provides the most reliable performance. These insights provide a foundation for improving SMS spam detection through optimized feature extraction and classification methods.
翻译:本研究评估了不同特征提取技术与分类算法在检测短信数据中垃圾信息方面的有效性。我们分析了六种分类器——朴素贝叶斯、K近邻、支持向量机、线性判别分析、决策树和深度神经网络,并采用两种特征提取方法:词袋模型和TF-IDF。主要目标是确定用于短信垃圾信息检测的最有效分类器-特征组合。我们的研究提供了两项主要贡献:首先,通过系统检验各种分类器与特征提取方法的配对;其次,通过实证评估它们区分垃圾信息的能力。结果表明,在所有六种分类器中,TF-IDF方法的表现始终优于词袋模型。具体而言,结合TF-IDF的朴素贝叶斯取得了96.2%的最高准确率,其中非垃圾信息的精确率为0.976,垃圾信息的精确率为0.754。同样,结合TF-IDF的支持向量机表现出94.5%的准确率,非垃圾信息精确率为0.926,垃圾信息精确率为0.891。使用TF-IDF的深度神经网络获得了91.0%的准确率,非垃圾信息的召回率为0.991,垃圾信息的召回率为0.415。相比之下,无论采用何种特征提取方法,K近邻、线性判别分析和决策树等分类器均表现出较弱的性能。此外,我们观察到分类器的有效性根据所选特征提取技术存在显著差异。我们的发现强调了特征选择在短信垃圾信息检测中的重要性,并表明TF-IDF与朴素贝叶斯、支持向量机或深度神经网络结合时能提供最可靠的性能。这些见解为通过优化特征提取和分类方法改进短信垃圾信息检测奠定了基础。