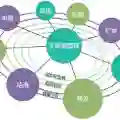
Since FineWeb-Edu, data curation for LLM pretraining has predominantly relied on single scalar quality scores produced by small classifiers. A single score conflates multiple quality dimensions, prevents flexible filtering, and offers no interpretability. We introduce propella-1, a family of small multilingual LLMs (0.6B, 1.7B, 4B parameters) that annotate text documents across 18 properties organized into six categories: core content, classification, quality and value, audience and purpose, safety and compliance, and geographic relevance. The models support 57 languages and produce structured JSON annotations conforming to a predefined schema. Evaluated against a frontier commercial LLM as a reference annotator, the 4B model achieves higher agreement than much larger general-purpose models. We release propella-annotations, a dataset of over three billion document annotations covering major pretraining corpora including data from FineWeb-2, FinePDFs, HPLT 3.0, and Nemotron-CC. Using these annotations, we present a multi-dimensional compositional analysis of widely used pretraining datasets, revealing substantial differences in quality, reasoning depth, and content composition that single-score approaches cannot capture. All model weights and annotations are released under permissive, commercial-use licenses.
翻译:自FineWeb-Edu以来,大型语言模型(LLM)预训练的数据治理主要依赖于小型分类器生成的单一标量质量分数。单一分数混淆了多个质量维度,阻碍了灵活筛选,且缺乏可解释性。本文介绍propella-1系列——一组小型多语言LLM(参数规模分别为0.6B、1.7B和4B),能够对文本文档进行涵盖六大类别(核心内容、分类、质量与价值、受众与目的、安全合规、地理相关性)共18项属性的标注。该系列模型支持57种语言,并生成符合预定义模式的结构化JSON标注。以前沿商业LLM作为参考标注器进行评估,4B参数模型比参数规模大得多的通用模型取得了更高的一致性。我们开源了propella-annotations数据集,其中包含超过30亿份文档标注,覆盖了包括FineWeb-2、FinePDFs、HPLT 3.0和Nemotron-CC在内的主要预训练语料库。利用这些标注,我们对广泛使用的预训练数据集进行了多维度组合分析,揭示了单一分数方法无法捕捉的质量、推理深度和内容构成方面的显著差异。所有模型权重与标注数据均以允许商业使用的宽松许可证发布。