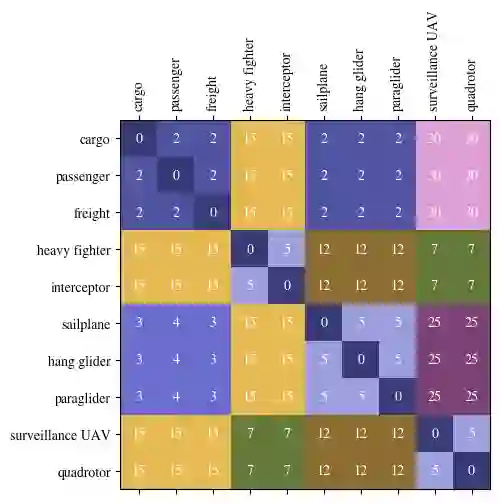
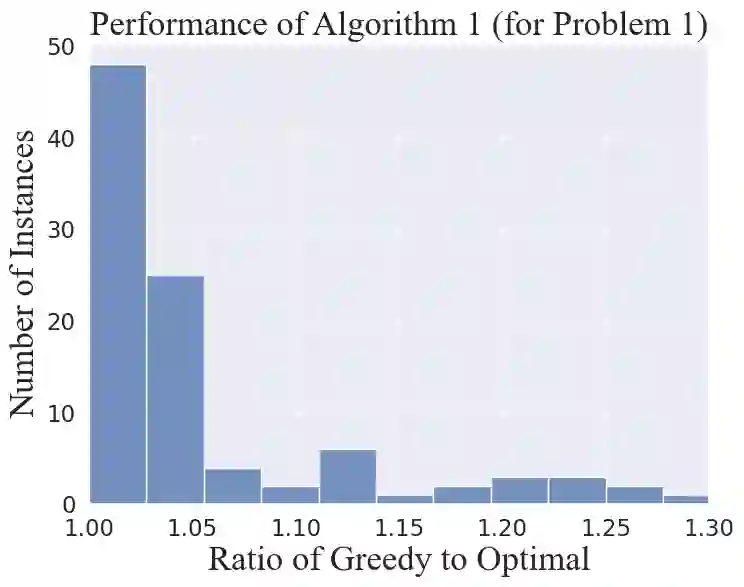
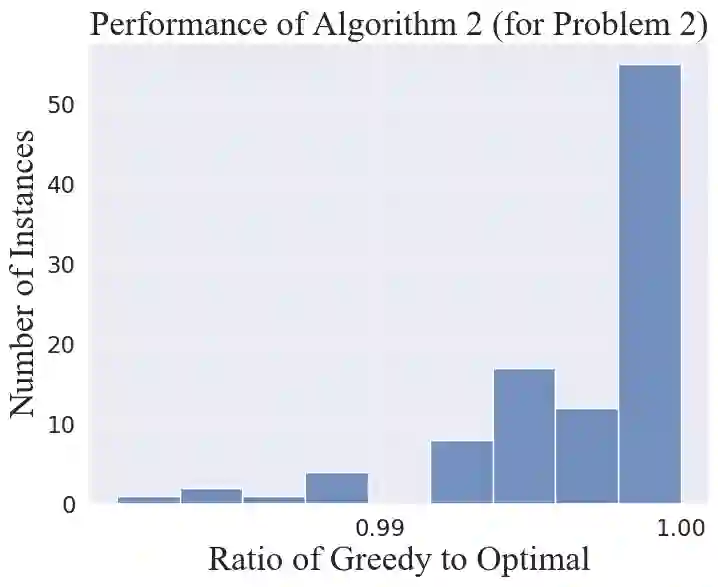
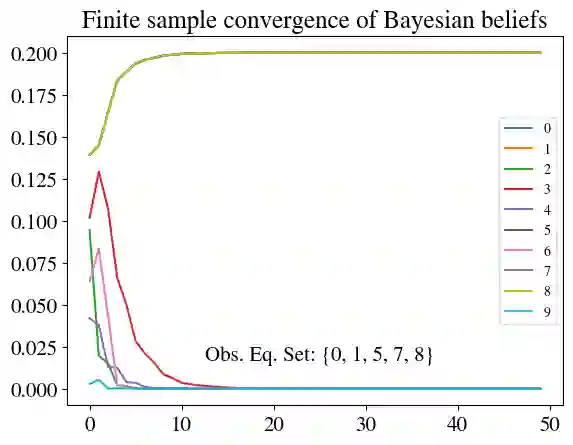
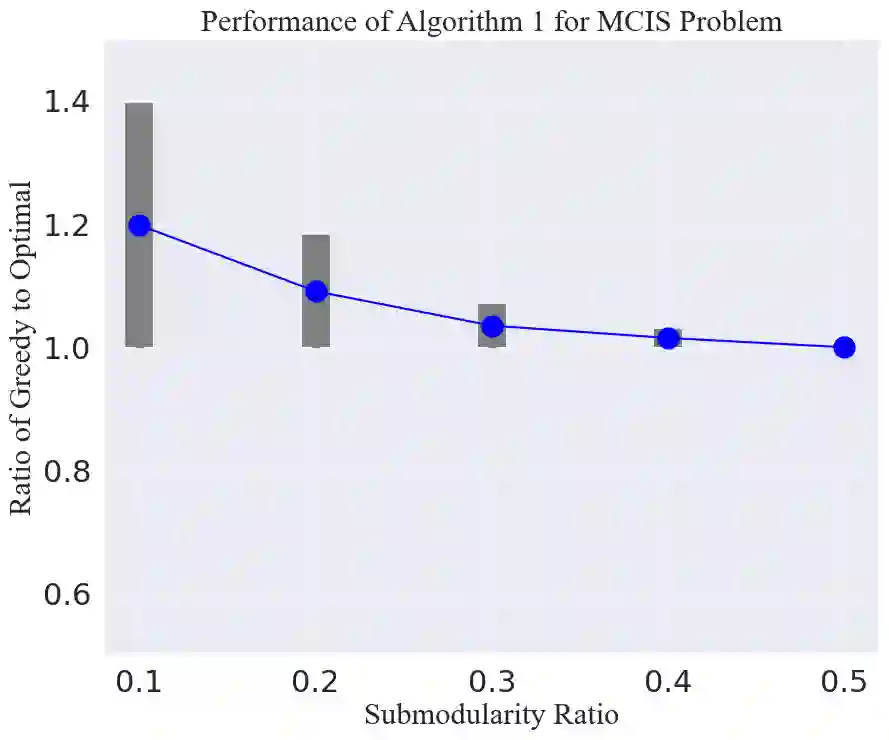
We consider the problem of selecting an optimal subset of information sources for a hypothesis testing/classification task where the goal is to identify the true state of the world from a finite set of hypotheses, based on finite observation samples from the sources. In order to characterize the learning performance, we propose a misclassification penalty framework, which enables non-uniform treatment of different misclassification errors. In a centralized Bayesian learning setting, we study two variants of the subset selection problem: (i) selecting a minimum cost information set to ensure that the maximum penalty of misclassifying the true hypothesis remains bounded and (ii) selecting an optimal information set under a limited budget to minimize the maximum penalty of misclassifying the true hypothesis. Under mild assumptions, we prove that the objective (or constraints) of these combinatorial optimization problems are weak (or approximate) submodular, and establish high-probability performance guarantees for greedy algorithms. Further, we propose an alternate metric for information set selection which is based on the total penalty of misclassification. We prove that this metric is submodular and establish near-optimal guarantees for the greedy algorithms for both the information set selection problems. Finally, we present numerical simulations to validate our theoretical results over several randomly generated instances.
翻译:我们研究了假设检验/分类任务中信息源最优子集的选择问题,其目标是通过有限观测样本从有限假设集合中识别世界真实状态。为刻画学习性能,我们提出了一个误分类惩罚框架,该框架能够对不同误分类错误进行非均匀处理。在集中式贝叶斯学习场景下,我们研究了子集选择问题的两个变体:(i)选择最小代价信息集,确保真实假设误分类的最大惩罚有界;(ii)在有限预算下选择最优信息集,以最小化真实假设误分类的最大惩罚。在温和假设下,我们证明这些组合优化问题的目标函数(或约束条件)具有弱(或近似)子模性,并为贪心算法建立了高概率性能保证。此外,我们提出了一种基于总误分类惩罚的替代信息集选择度量,证明该度量具有子模性,并针对两类信息集选择问题建立了贪心算法的近最优保证。最后,通过多个随机生成实例上的数值仿真验证了理论结果。