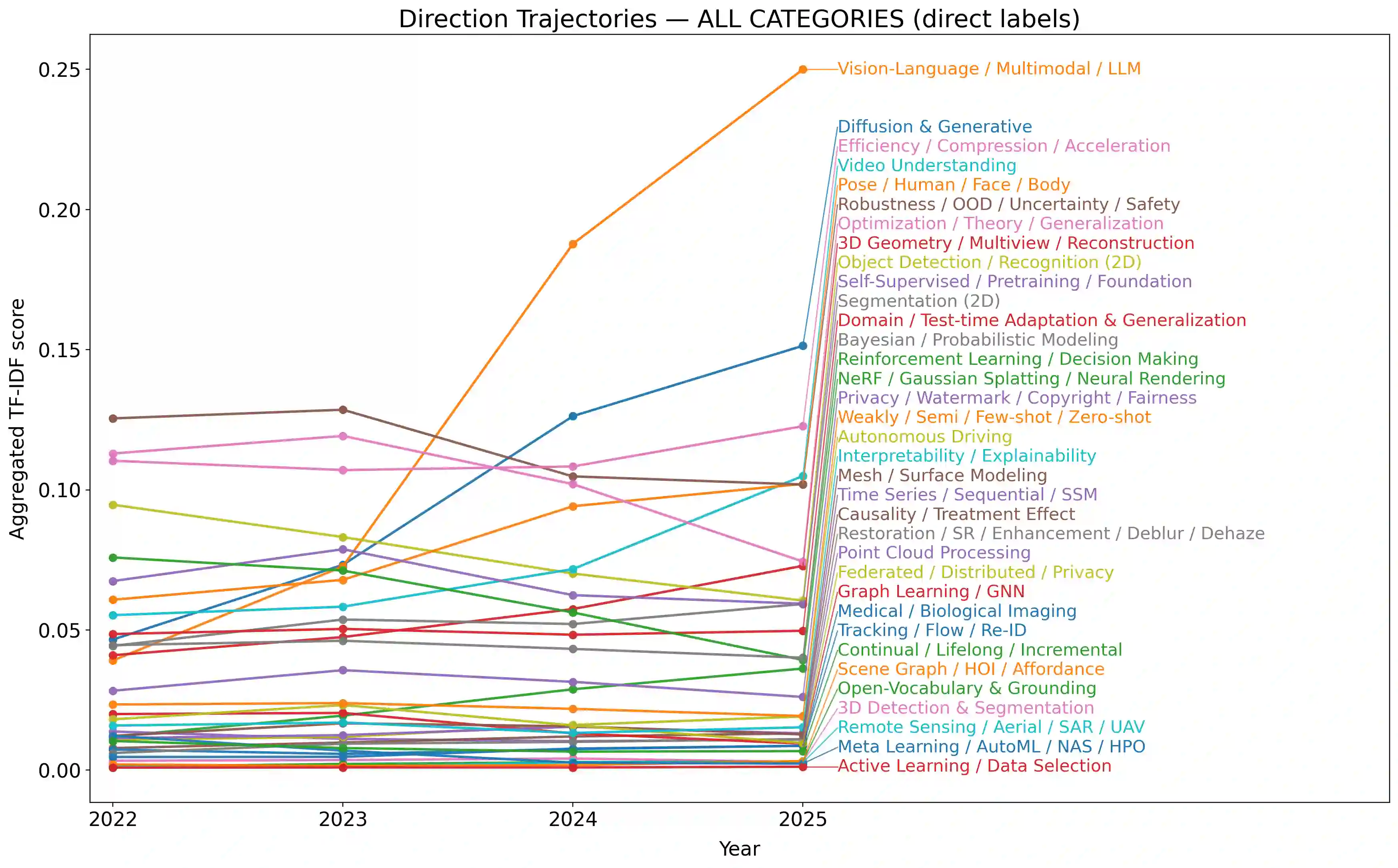
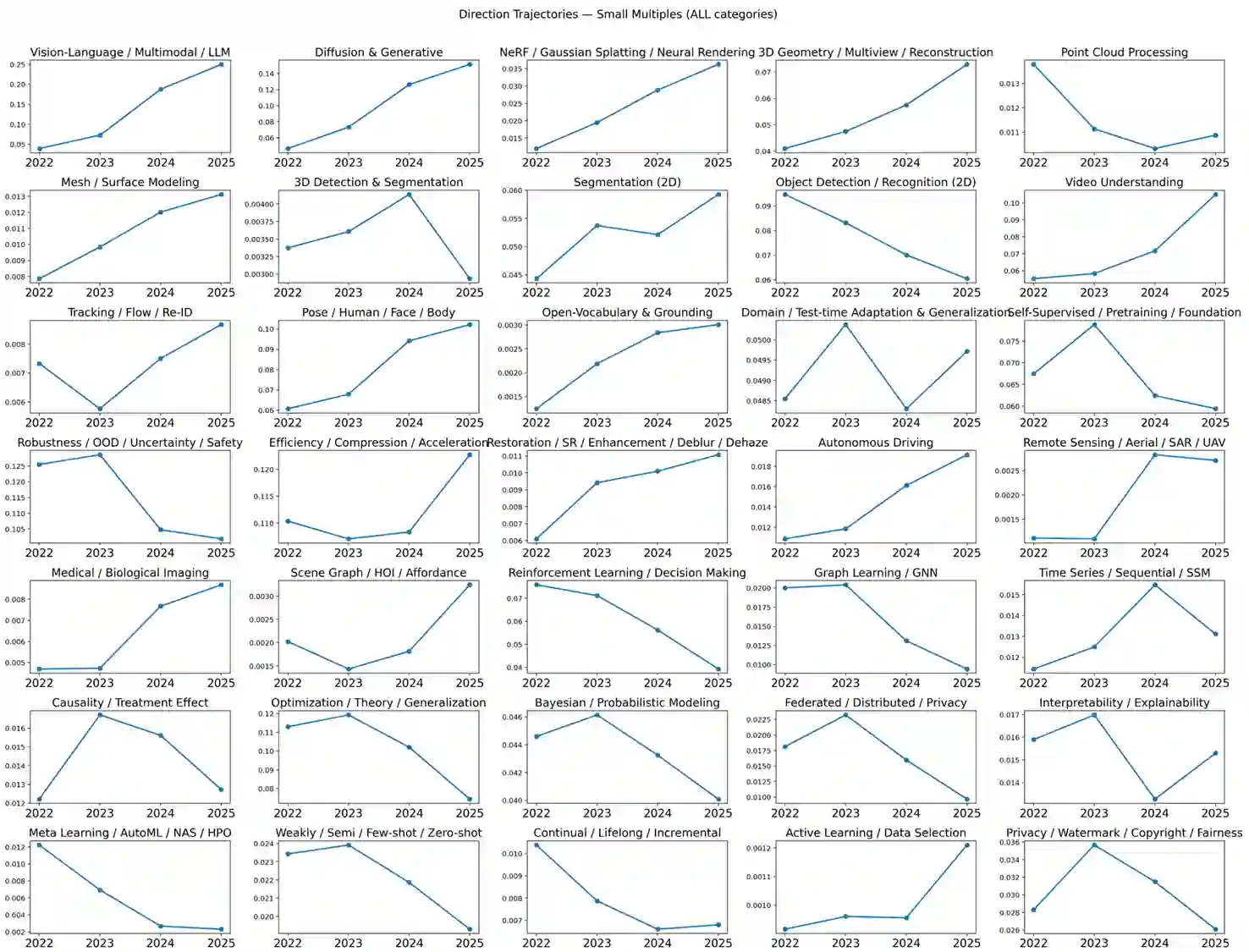
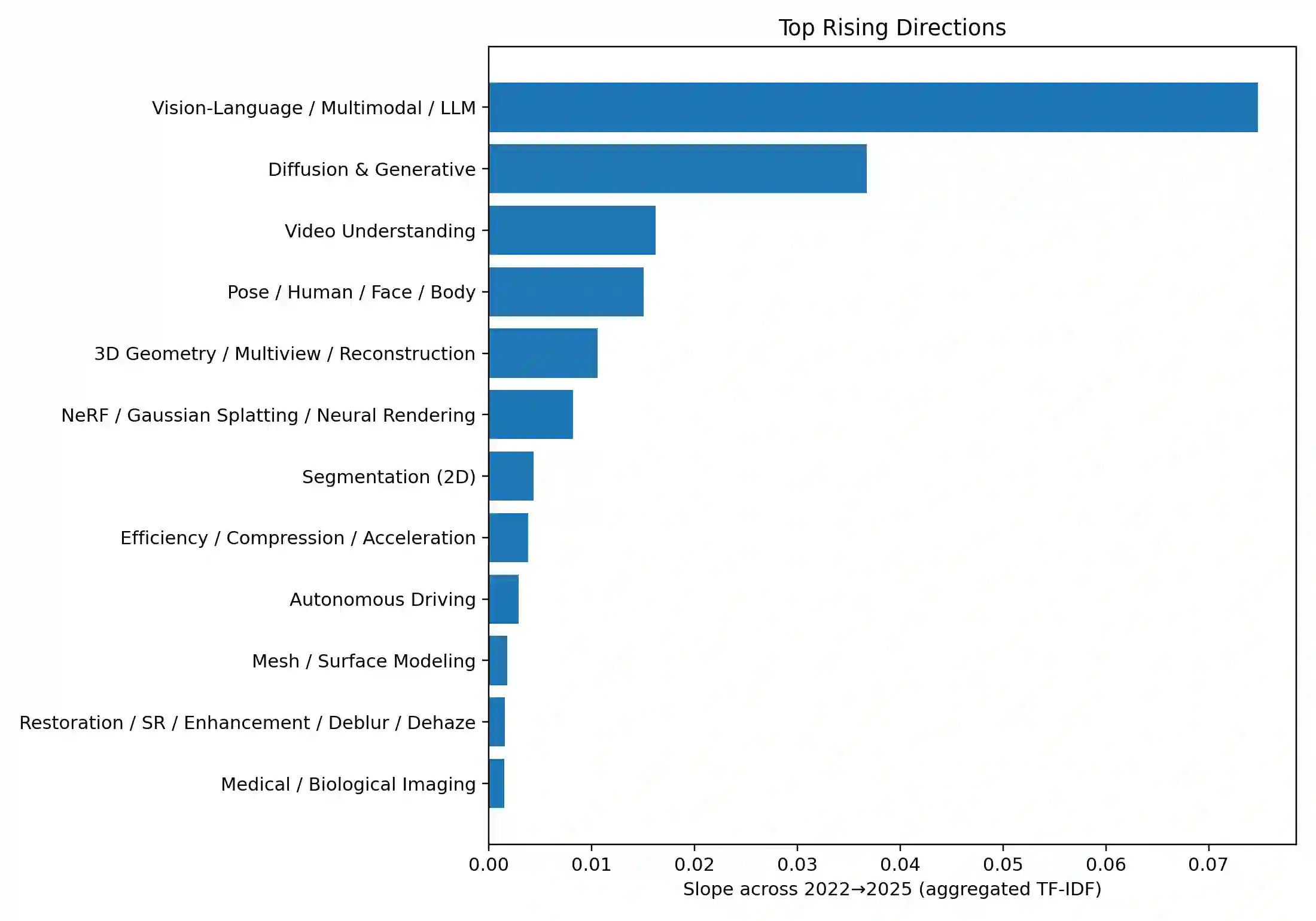
We present a transparent, reproducible measurement of research trends across 26,104 accepted papers from CVPR, ICLR, and NeurIPS spanning 2023-2025. Titles and abstracts are normalized, phrase-protected, and matched against a hand-crafted lexicon to assign up to 35 topical labels and mine fine-grained cues about tasks, architectures, training regimes, objectives, datasets, and co-mentioned modalities. The analysis quantifies three macro shifts: (1) a sharp rise of multimodal vision-language-LLM work, which increasingly reframes classic perception as instruction following and multi-step reasoning; (2) steady expansion of generative methods, with diffusion research consolidating around controllability, distillation, and speed; and (3) resilient 3D and video activity, with composition moving from NeRFs to Gaussian splatting and a growing emphasis on human- and agent-centric understanding. Within VLMs, parameter-efficient adaptation like prompting/adapters/LoRA and lightweight vision-language bridges dominate; training practice shifts from building encoders from scratch to instruction tuning and finetuning strong backbones; contrastive objectives recede relative to cross-entropy/ranking and distillation. Cross-venue comparisons show CVPR has a stronger 3D footprint and ICLR the highest VLM share, while reliability themes such as efficiency or robustness diffuse across areas. We release the lexicon and methodology to enable auditing and extension. Limitations include lexicon recall and abstract-only scope, but the longitudinal signals are consistent across venues and years.
翻译:我们对2023年至2025年间CVPR、ICLR和NeurIPS会议收录的26,104篇论文进行了透明、可复现的研究趋势测量。通过对标题和摘要进行规范化、短语保护处理,并依据手工构建的词典进行匹配,我们为每篇论文分配了最多35个主题标签,并挖掘了关于任务、架构、训练策略、目标函数、数据集以及共同提及的模态的细粒度线索。分析量化了三大宏观趋势:(1) 多模态视觉-语言-大语言模型研究的急剧增长,其日益将经典感知任务重新定义为指令跟随和多步推理;(2) 生成式方法的稳步扩展,其中扩散模型研究围绕可控性、蒸馏和速度进行整合;(3) 3D与视频研究的持续活跃,场景表示从NeRFs转向高斯溅射,并且越来越强调以人和智能体为中心的理解。在视觉语言模型内部,参数高效适应方法(如提示/适配器/LoRA)和轻量级视觉-语言桥梁占据主导地位;训练实践从从头构建编码器转向对强大骨干网络进行指令微调和微调;对比学习目标相对于交叉熵/排序损失以及蒸馏方法的重要性有所下降。跨会议比较显示,CVPR在3D领域有更强的研究基础,而ICLR的视觉语言模型研究占比最高,同时效率或鲁棒性等可靠性主题在各个领域广泛渗透。我们公开了词典与方法论,以便进行审计和扩展。本研究的局限性包括词典召回率以及仅基于摘要的分析范围,但所揭示的纵向趋势在不同会议和年份间保持一致。