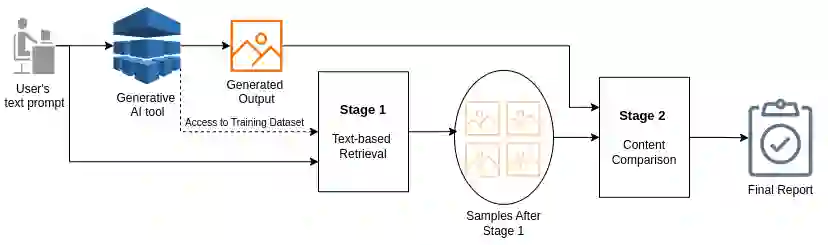
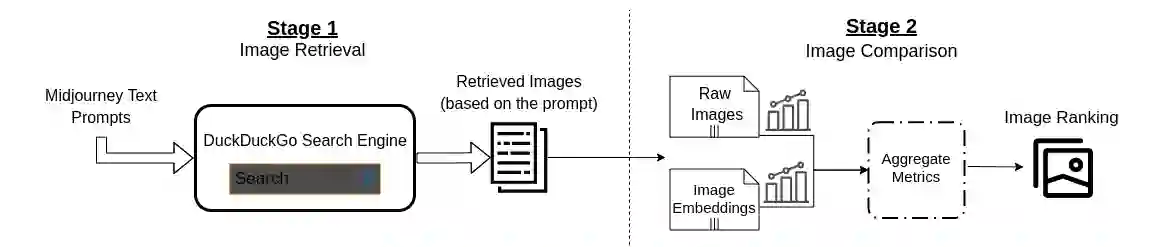
Generative AI models offer powerful capabilities but often lack transparency, making it difficult to interpret their output. This is critical in cases involving artistic or copyrighted content. This work introduces a search-inspired approach to improve the interpretability of these models by analysing the influence of training data on their outputs. Our method provides observational interpretability by focusing on a model's output rather than on its internal state. We consider both raw data and latent-space embeddings when searching for the influence of data items in generated content. We evaluate our method by retraining models locally and by demonstrating the method's ability to uncover influential subsets in the training data. This work lays the groundwork for future extensions, including user-based evaluations with domain experts, which is expected to improve observational interpretability further.
翻译:生成式人工智能模型具备强大的能力,但通常缺乏透明度,导致其输出难以解释。这在涉及艺术或受版权保护内容的情况下至关重要。本研究提出一种受搜索启发的分析方法,通过考察训练数据对模型输出的影响来提升此类模型的可解释性。我们的方法聚焦于模型输出而非其内部状态,从而提供观测层面的可解释性。在搜索生成内容中数据项的影响时,我们同时考虑原始数据与潜在空间嵌入表示。我们通过局部重训练模型,并展示该方法发现训练数据中有影响力子集的能力,对本方法进行了评估。这项工作为未来扩展奠定了基础,包括与领域专家开展基于用户的评估,预计将进一步提升观测可解释性。