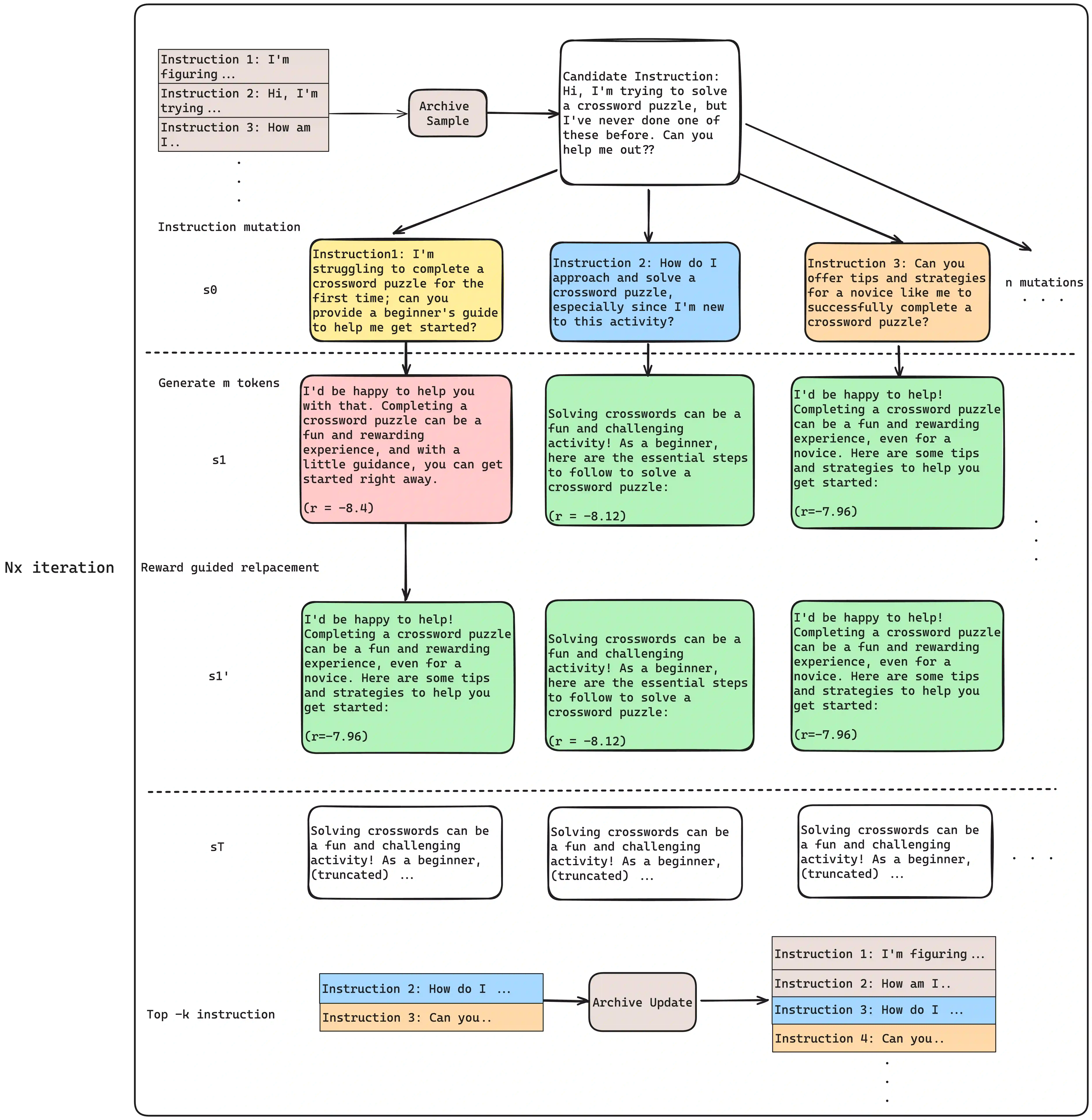
The widespread applicability and increasing omnipresence of LLMs have instigated a need to align LLM responses to user and stakeholder preferences. Many preference optimization approaches have been proposed that fine-tune LLM parameters to achieve good alignment. However, such parameter tuning is known to interfere with model performance on many tasks. Moreover, keeping up with shifting user preferences is tricky in such a situation. Decoding-time alignment with reward model guidance solves these issues at the cost of increased inference time. However, most of such methods fail to strike the right balance between exploration and exploitation of reward -- often due to the conflated formulation of these two aspects - to give well-aligned responses. To remedy this we decouple these two aspects and implement them in an evolutionary fashion: exploration is enforced by decoding from mutated instructions and exploitation is represented as the periodic replacement of poorly-rewarded generations with well-rewarded ones. Empirical evidences indicate that this strategy outperforms many preference optimization and decode-time alignment approaches on two widely accepted alignment benchmarks AlpacaEval 2 and MT-Bench. Our implementation will be available at: https://darwin-alignment.github.io.
翻译:大型语言模型(LLM)的广泛适用性和日益普及引发了对齐LLM响应与用户及利益相关者偏好的需求。目前已有许多偏好优化方法通过微调LLM参数来实现对齐,但此类参数调整已知会干扰模型在多项任务上的性能表现,且难以适应动态变化的用户偏好。基于奖励模型指导的解码时对齐方法虽能解决这些问题,却会以增加推理时间为代价。然而,现有方法大多因未能平衡奖励探索与利用的辩证关系——常源于二者概念的混淆——而难以生成充分对齐的响应。为此,我们解耦这两个维度并以进化机制实现:通过变异指令解码强制进行探索,同时将低奖励生成周期性地替换为高奖励生成以实现利用。实证研究表明,该策略在AlpacaEval 2和MT-Bench两个广泛认可的对齐基准测试中优于多种偏好优化与解码时对齐方法。实现代码将发布于:https://darwin-alignment.github.io。