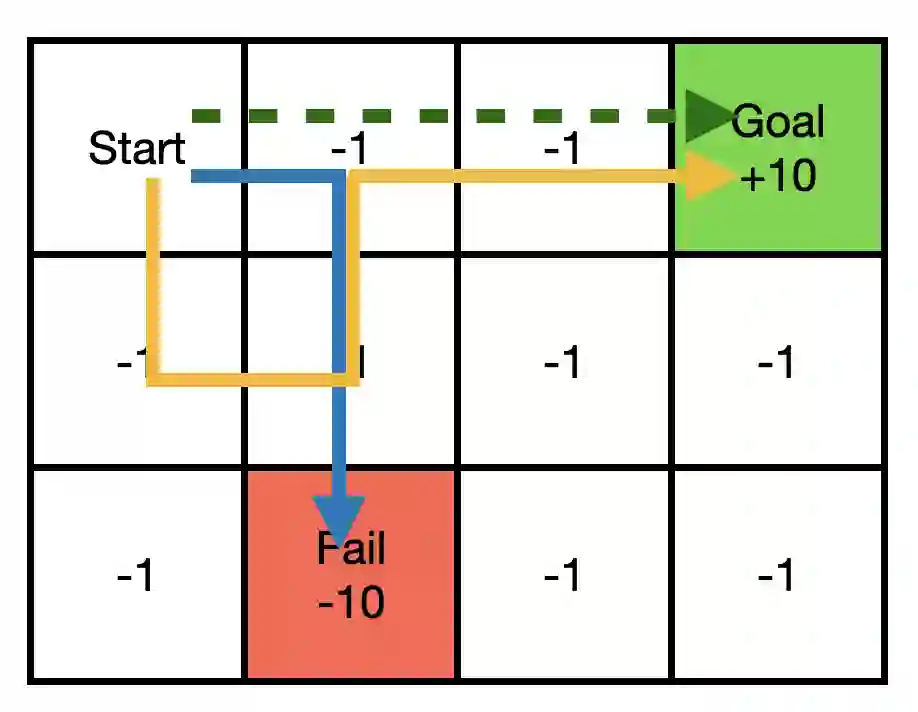
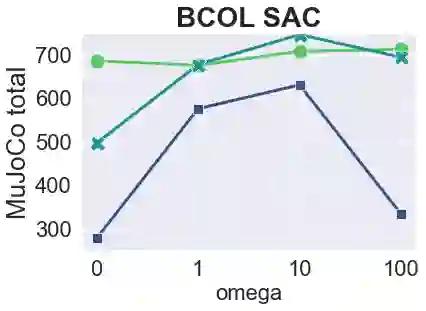
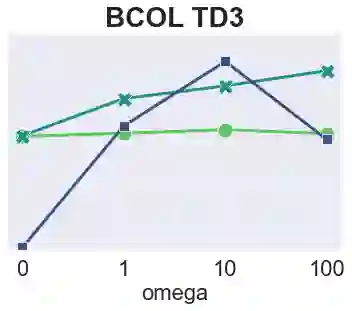
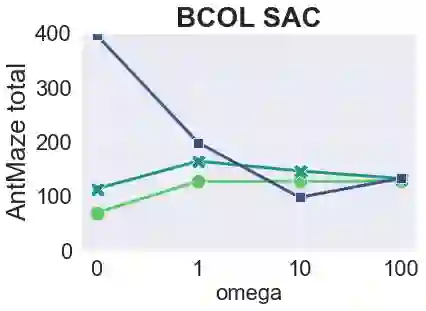
The main challenge of offline reinforcement learning, where data is limited, arises from a sequence of counterfactual reasoning dilemmas within the realm of potential actions: What if we were to choose a different course of action? These circumstances frequently give rise to extrapolation errors, which tend to accumulate exponentially with the problem horizon. Hence, it becomes crucial to acknowledge that not all decision steps are equally important to the final outcome, and to budget the number of counterfactual decisions a policy make in order to control the extrapolation. Contrary to existing approaches that use regularization on either the policy or value function, we propose an approach to explicitly bound the amount of out-of-distribution actions during training. Specifically, our method utilizes dynamic programming to decide where to extrapolate and where not to, with an upper bound on the decisions different from behavior policy. It balances between the potential for improvement from taking out-of-distribution actions and the risk of making errors due to extrapolation. Theoretically, we justify our method by the constrained optimality of the fixed point solution to our $Q$ updating rules. Empirically, we show that the overall performance of our method is better than the state-of-the-art offline RL methods on tasks in the widely-used D4RL benchmarks.
翻译:离线强化学习的主要挑战源于数据有限性,其本质是在潜在行动空间中面临一系列反事实推理困境:若选择另一行动路径将产生何种后果?此类情形常引发外推误差,且该误差会随问题维度呈指数级累积。因此,关键要认识到并非所有决策步骤对最终结果具有同等重要性,并应通过预算约束策略所采纳的反事实决策数量来控制外推误差。不同于现有方法对策略或价值函数施加正则化约束,我们提出一种在训练过程中显式限制分布外行动数量的方法。具体而言,该方法利用动态规划技术决定何时进行外推、何时避免外推,同时对偏离行为策略的决策设置上限。该方法在采纳分布外行动带来的改进潜力与外推误差风险之间取得平衡。理论层面,我们通过证明$Q$值更新规则不动点解的约束最优性来验证方法有效性。实验层面,在广泛使用的D4RL基准测试任务中,我们的方法整体表现优于当前最优的离线强化学习方法。