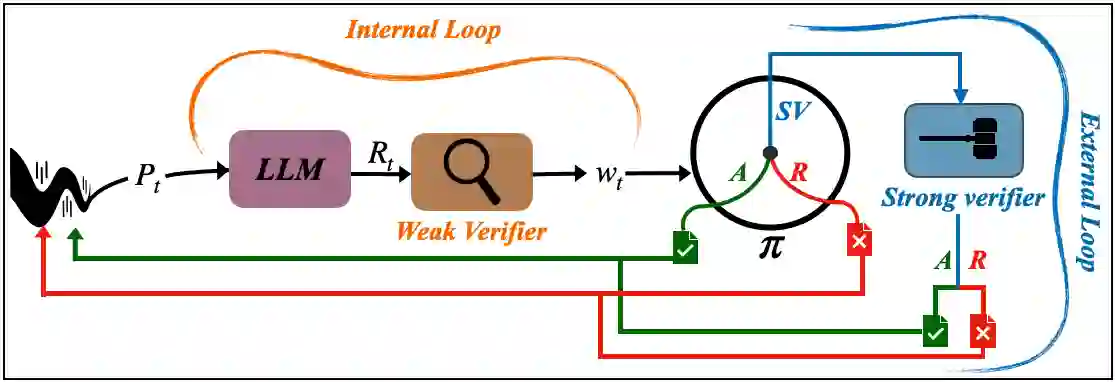
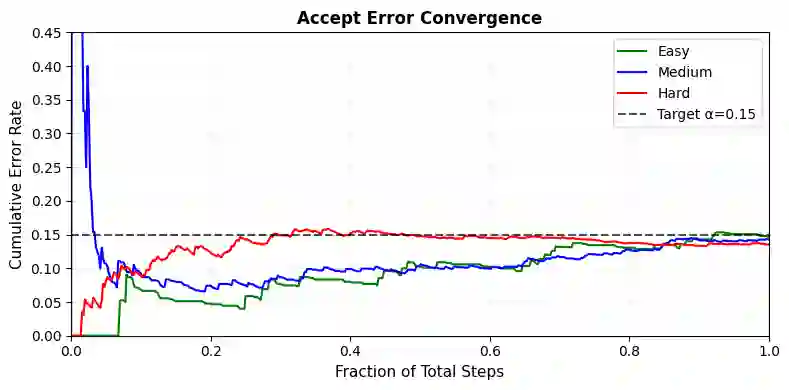
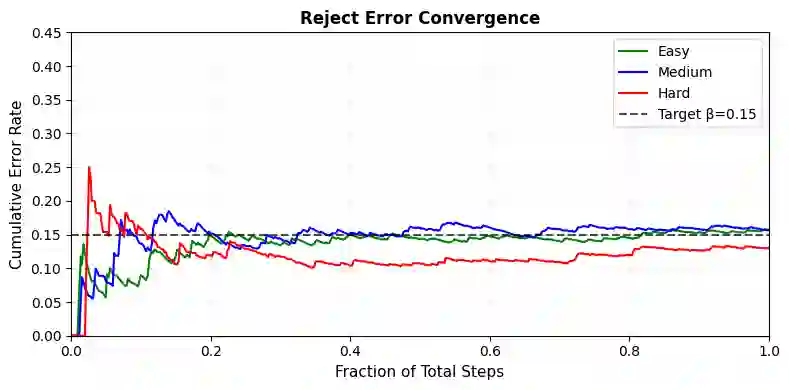
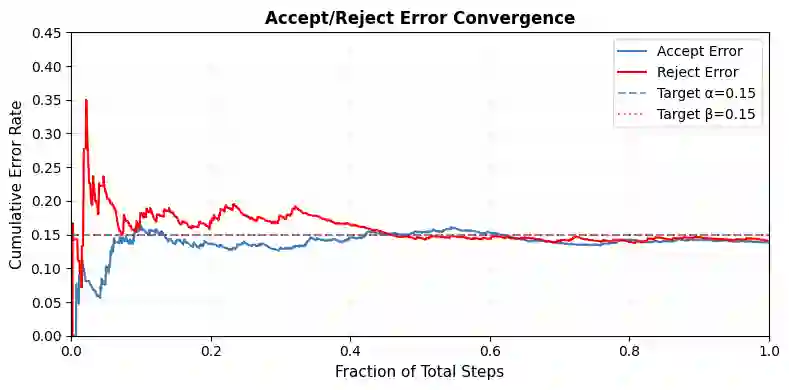
Reasoning with LLMs increasingly unfolds inside a broader verification loop. Internally, systems use cheap checks, such as self-consistency or proxy rewards, which we call weak verification. Externally, users inspect outputs and steer the model through feedback until results are trustworthy, which we call strong verification. These signals differ sharply in cost and reliability: strong verification can establish trust but is resource-intensive, while weak verification is fast and scalable but noisy and imperfect. We formalize this tension through weak--strong verification policies, which decide when to accept or reject based on weak verification and when to defer to strong verification. We introduce metrics capturing incorrect acceptance, incorrect rejection, and strong-verification frequency. Over population, we show that optimal policies admit a two-threshold structure and that calibration and sharpness govern the value of weak verifiers. Building on this, we develop an online algorithm that provably controls acceptance and rejection errors without assumptions on the query stream, the language model, or the weak verifier.
翻译:随着大型语言模型在推理中的应用日益广泛,其推理过程逐渐被置于一个更广泛的验证循环之中。系统内部采用廉价检查机制,如自洽性检验或代理奖励,我们称之为弱验证。外部用户则通过检查输出并提供反馈来引导模型,直至结果可信,这一过程我们称为强验证。这两种信号在成本与可靠性上存在显著差异:强验证能够建立信任但资源密集,而弱验证快速且可扩展,但存在噪声且不完美。我们通过弱-强验证策略来形式化这一矛盾,该策略基于弱验证结果决定何时接受或拒绝输出,以及何时需要转交强验证处理。我们引入了量化错误接受、错误拒绝以及强验证频率的指标。在总体层面上,我们证明最优策略具有双阈值结构,且校准度与锐度决定了弱验证器的价值。基于此,我们提出一种在线算法,该算法能够在不对查询流、语言模型或弱验证器做任何假设的前提下,可证明地控制接受与拒绝错误。