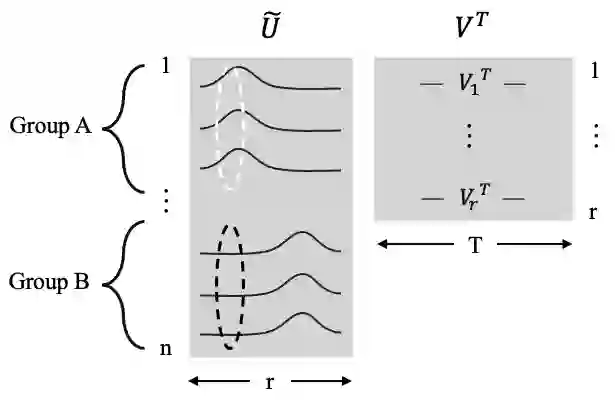
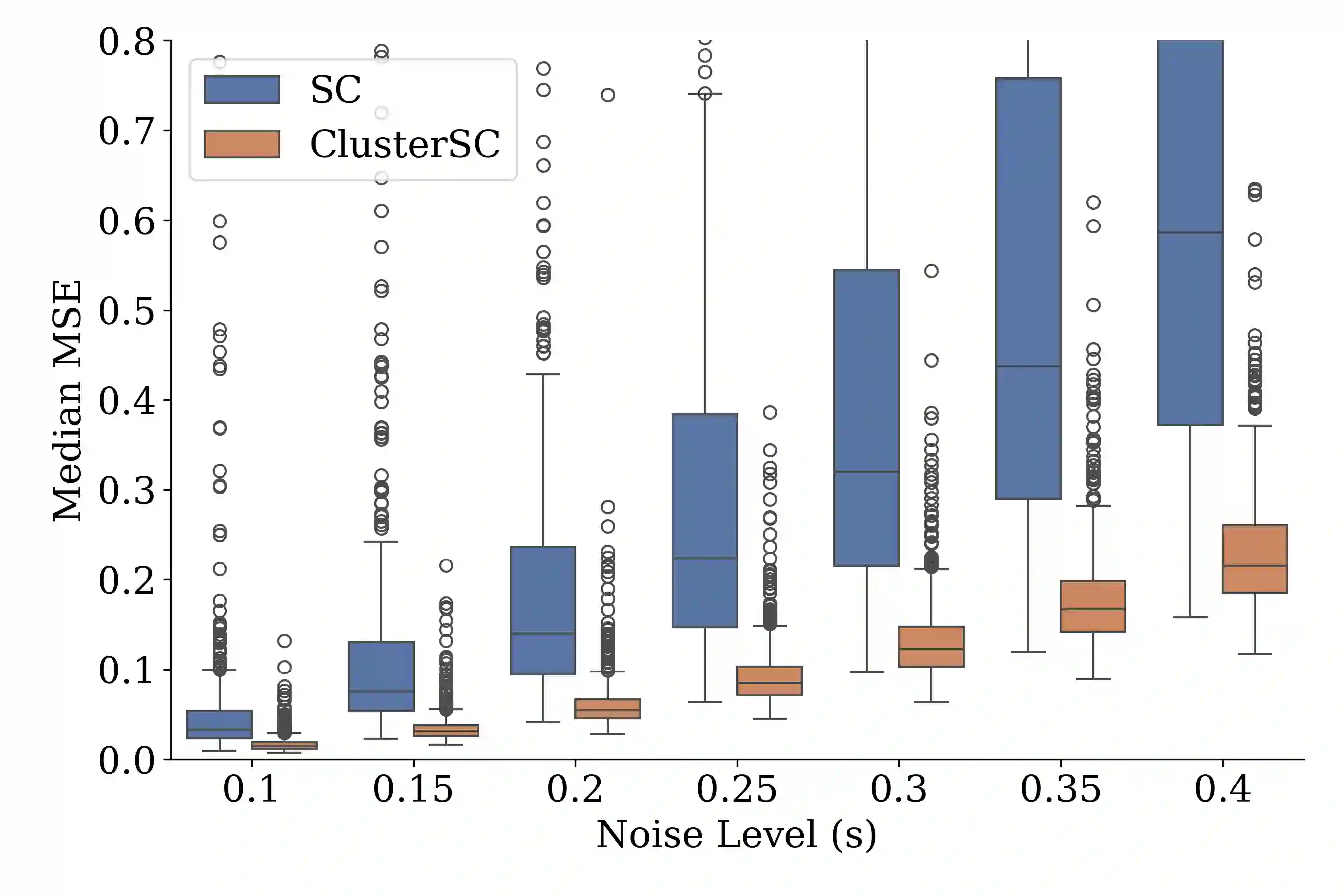
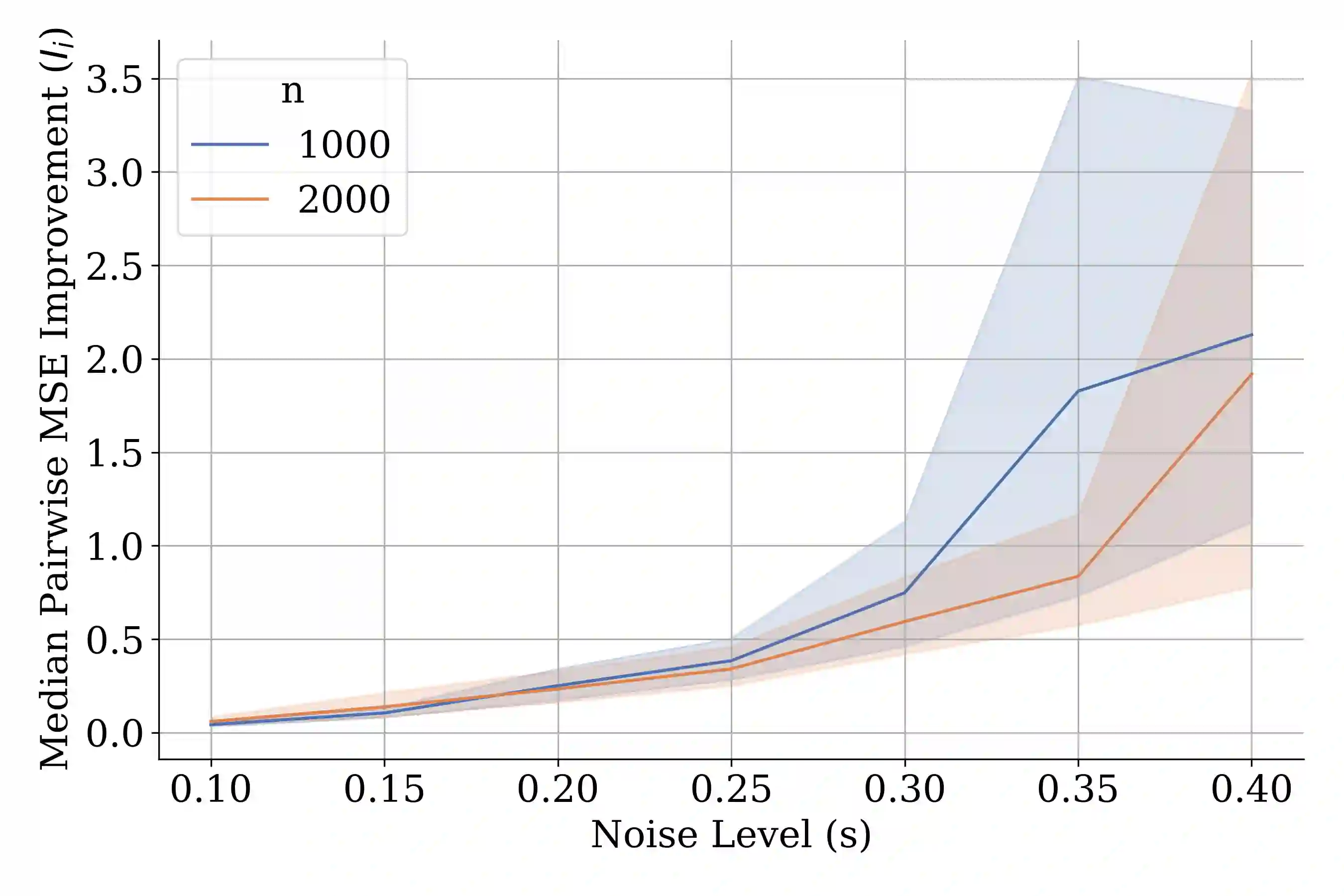
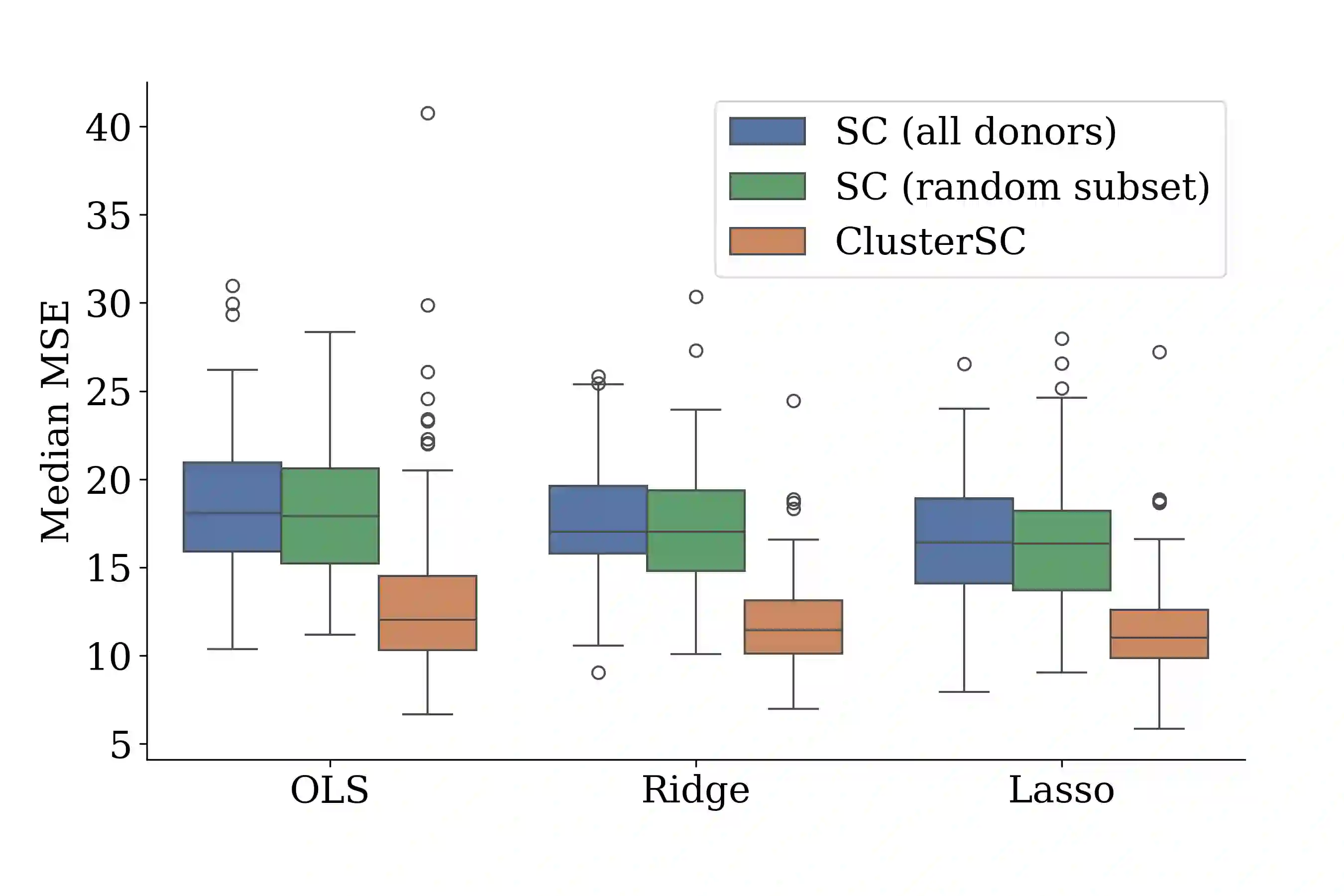
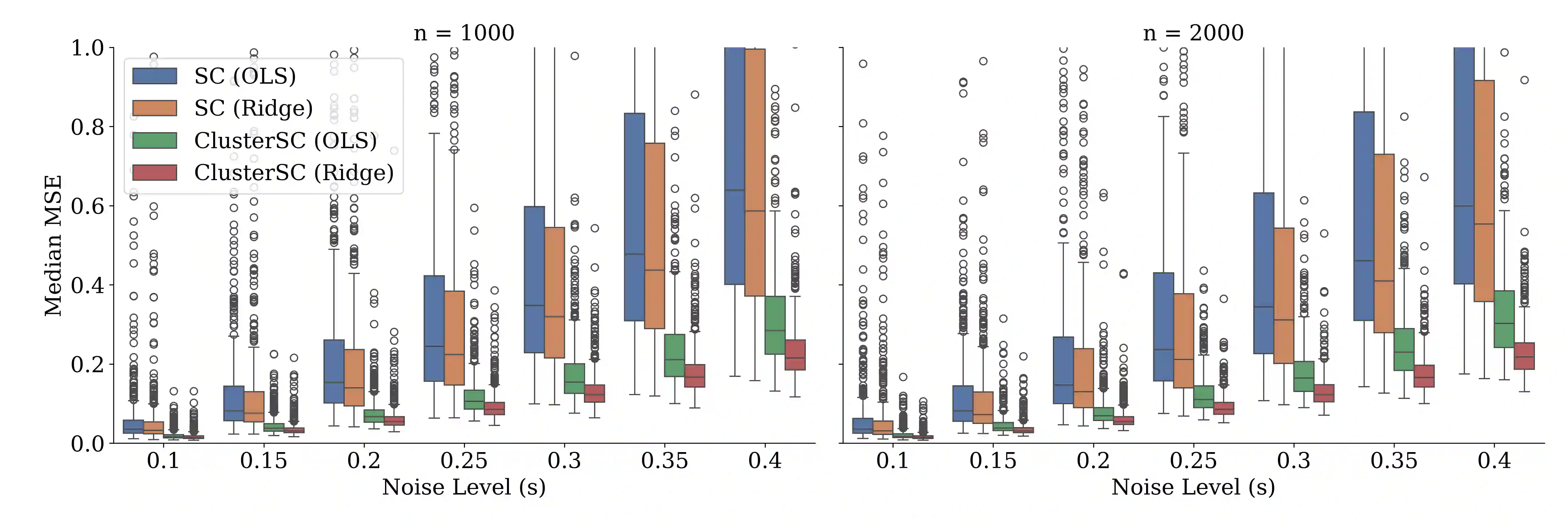
In causal inference with observational studies, synthetic control (SC) has emerged as a prominent tool. SC has traditionally been applied to aggregate-level datasets, but more recent work has extended its use to individual-level data. As they contain a greater number of observed units, this shift introduces the curse of dimensionality to SC. To address this, we propose Cluster Synthetic Control (ClusterSC), based on the idea that groups of individuals may exist where behavior aligns internally but diverges between groups. ClusterSC incorporates a clustering step to select only the relevant donors for the target. We provide theoretical guarantees on the improvements induced by ClusterSC, supported by empirical demonstrations on synthetic and real-world datasets. The results indicate that ClusterSC consistently outperforms classical SC approaches.
翻译:在基于观测研究的因果推断中,合成控制法已成为一种重要工具。传统上,合成控制法主要应用于聚合层面的数据集,但近期研究已将其扩展至个体层面的数据。由于个体数据包含更多观测单元,这一转变给合成控制法带来了维度灾难问题。为解决此问题,我们提出了聚类合成控制法,其核心思想是:可能存在某些个体群组,其内部行为一致但组间行为存在差异。ClusterSC通过引入聚类步骤,仅选择与目标相关的供体。我们为ClusterSC带来的改进提供了理论保证,并在合成数据集和真实世界数据集上进行了实证验证。结果表明,ClusterSC在性能上持续优于经典的合成控制方法。