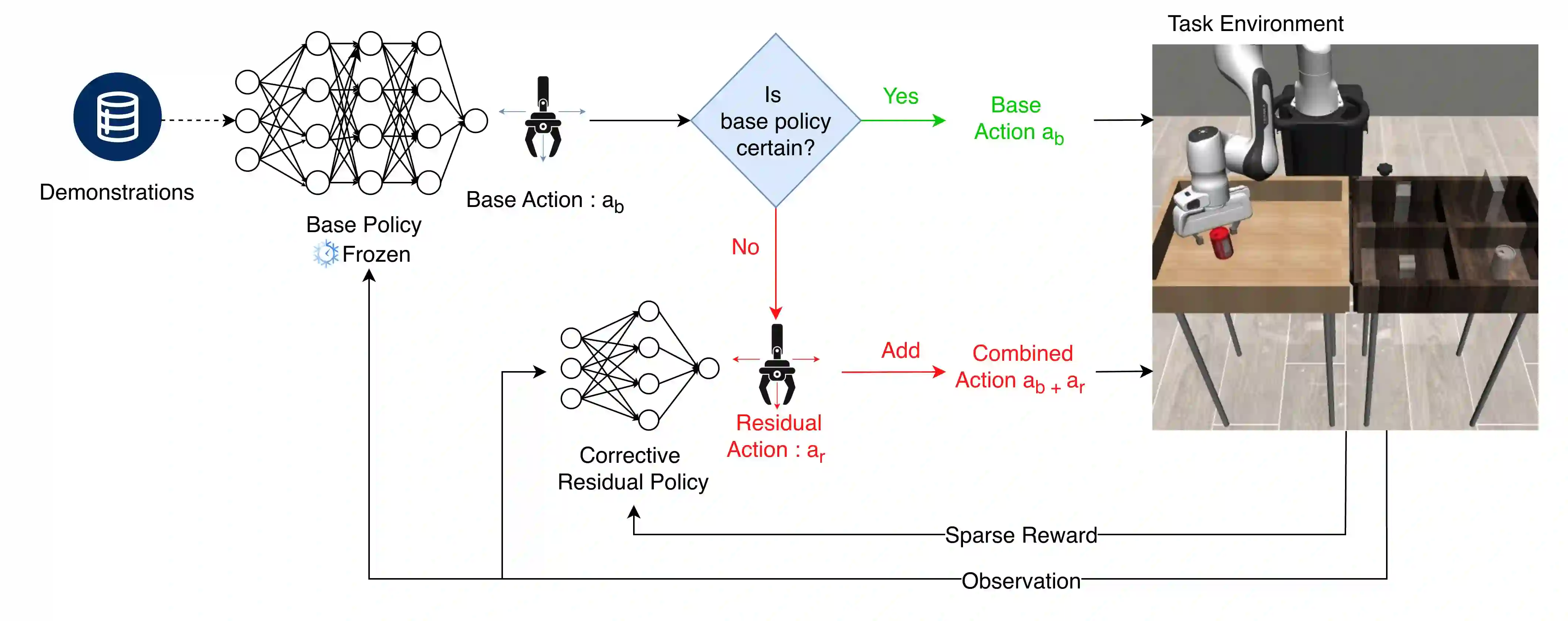
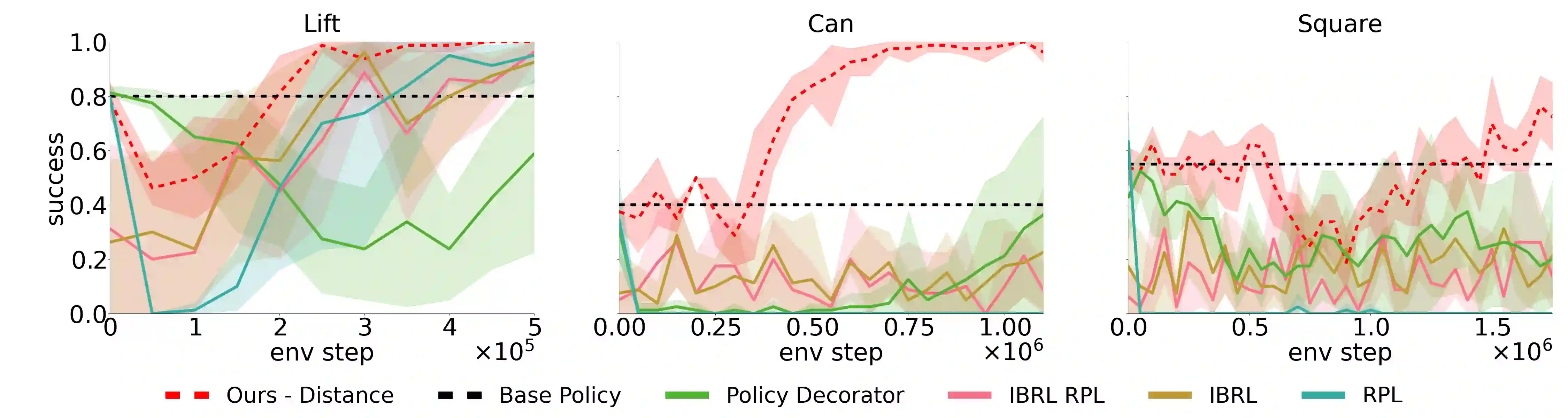
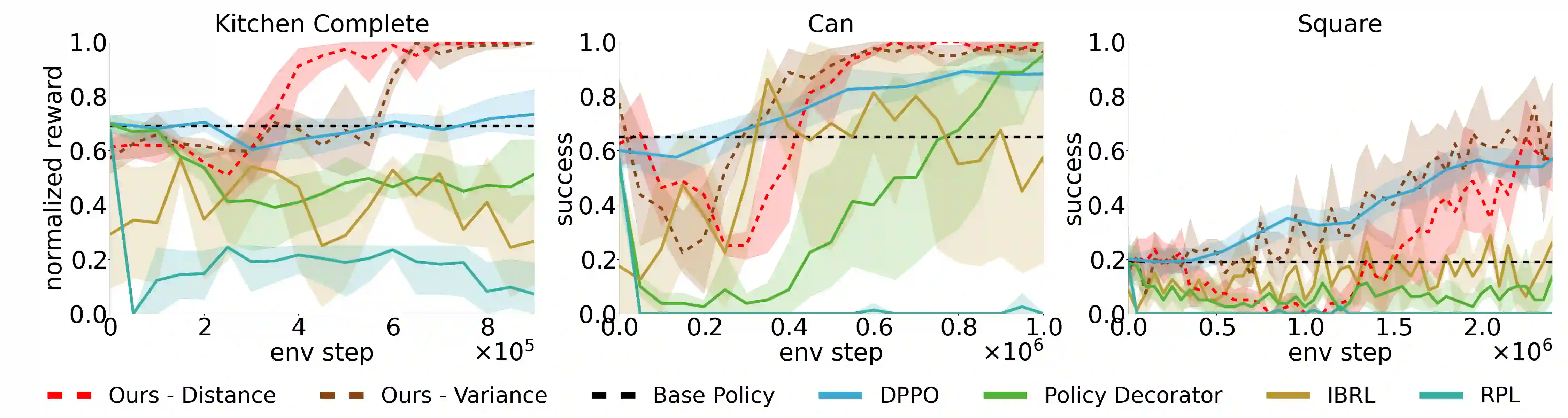
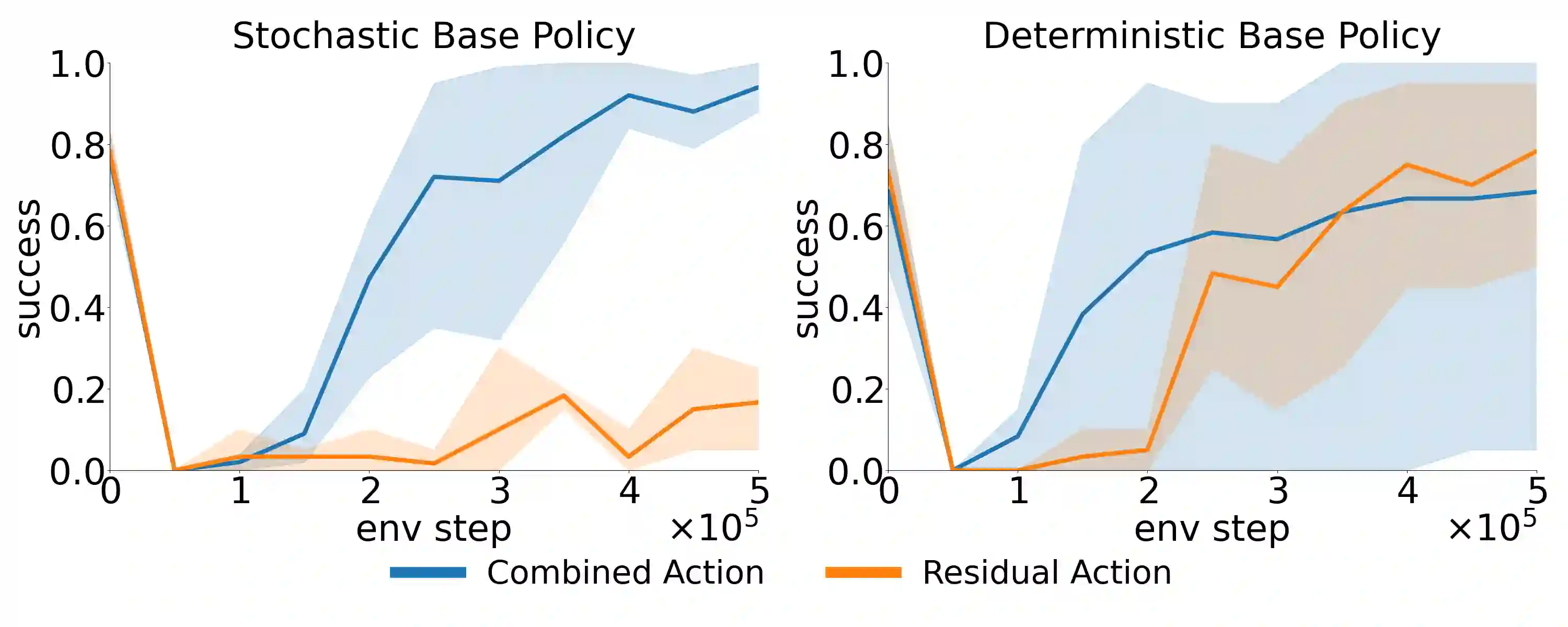
Residual Reinforcement Learning (RL) is a popular approach for adapting pretrained policies by learning a lightweight residual policy that provides corrective actions. While Residual RL is more sample-efficient than finetuning the entire base policy, existing methods struggle with sparse rewards and are designed for deterministic base policies. We propose two improvements to Residual RL that further enhance its sample efficiency and make it suitable for stochastic base policies. First, we leverage uncertainty estimates of the base policy to focus exploration on regions in which the base policy is not confident. Second, we propose a simple modification to off-policy residual learning that allows it to observe base actions and better handle stochastic base policies. We evaluate our method with both Gaussian-based and Diffusion-based stochastic base policies on tasks from Robosuite and D4RL, and compare against state-of-the-art finetuning methods, demo-augmented RL methods, and other residual RL methods. Our algorithm significantly outperforms existing baselines in a variety of simulation benchmark environments. We also deploy our learned polices in the real world to demonstrate their robustness with zero-shot sim-to-real transfer. Paper homepage : lakshitadodeja.github.io/uncertainty-aware-residual-rl/
翻译:残差强化学习是一种通过训练轻量级残差策略提供修正动作来调整预训练策略的常用方法。虽然残差强化学习比微调整个基础策略更具样本效率,但现有方法在稀疏奖励场景中存在困难,且仅适用于确定性基础策略。本文提出两项改进以进一步提升残差强化学习的样本效率,并使其适用于随机基础策略。首先,我们利用基础策略的不确定性估计,将探索重点集中在基础策略置信度较低的区域。其次,我们对离策略残差学习进行简单修改,使其能够观测基础动作并更好地处理随机基础策略。我们在Robosuite和D4RL任务中,分别采用基于高斯分布和基于扩散模型的随机基础策略评估所提方法,并与最先进的微调方法、演示增强强化学习方法及其他残差强化学习方法进行对比。实验表明,我们的算法在多种模拟基准环境中显著优于现有基线方法。我们还将训练所得策略部署于现实世界,通过零样本仿真到实物的迁移验证了其鲁棒性。论文主页:lakshitadodeja.github.io/uncertainty-aware-residual-rl/