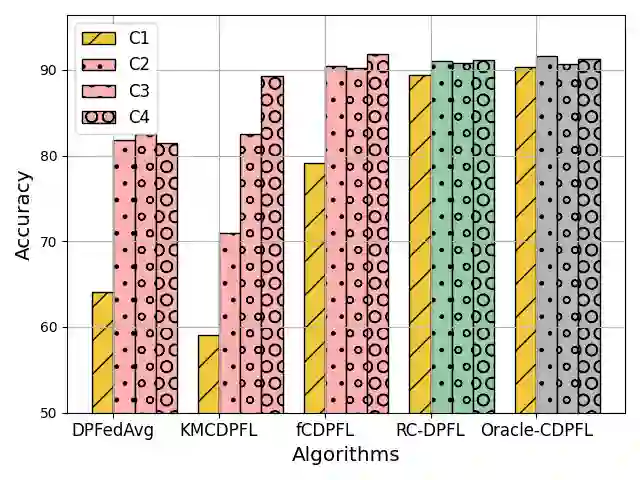
Federated Learning (FL) is a decentralized machine learning (ML) approach that keeps data localized and often incorporates Differential Privacy (DP) to enhance privacy guarantees. Similar to previous work on DP in ML, we observed that differentially private federated learning (DPFL) introduces performance disparities, particularly affecting minority groups. Recent work has attempted to address performance fairness in vanilla FL through clustering, but this method remains sensitive and prone to errors, which are further exacerbated by the DP noise in DPFL. To fill this gap, in this paper, we propose a novel clustered DPFL algorithm designed to effectively identify clients' clusters in highly heterogeneous settings while maintaining high accuracy with DP guarantees. To this end, we propose to cluster clients based on both their model updates and training loss values. Our proposed approach also addresses the server's uncertainties in clustering clients' model updates by employing larger batch sizes along with Gaussian Mixture Model (GMM) to alleviate the impact of noise and potential clustering errors, especially in privacy-sensitive scenarios. We provide theoretical analysis of the effectiveness of our proposed approach. We also extensively evaluate our approach across diverse data distributions and privacy budgets and show its effectiveness in mitigating the disparate impact of DP in FL settings with a small computational cost.
翻译:联邦学习(FL)是一种去中心化的机器学习(ML)方法,它将数据保留在本地,并通常结合差分隐私(DP)以增强隐私保护。与先前关于ML中DP的研究类似,我们观察到差分隐私联邦学习(DPFL)会引入性能差异,尤其影响少数群体。最近的研究尝试通过聚类方法解决普通FL中的性能公平性问题,但该方法仍然敏感且容易出错,而DPFL中的DP噪声进一步加剧了这些问题。为填补这一空白,本文提出了一种新颖的聚类DPFL算法,旨在高度异构环境中有效识别客户端聚类,同时在DP保证下保持高精度。为此,我们提出基于客户端的模型更新和训练损失值进行聚类。我们提出的方法还通过采用更大的批量大小结合高斯混合模型(GMM)来缓解噪声和潜在聚类错误的影响,从而解决服务器在聚类客户端模型更新时的不确定性问题,尤其是在隐私敏感场景中。我们对所提方法的有效性进行了理论分析。此外,我们在多种数据分布和隐私预算下广泛评估了该方法,结果表明其能以较小的计算成本有效缓解DP在FL环境中的差异性影响。