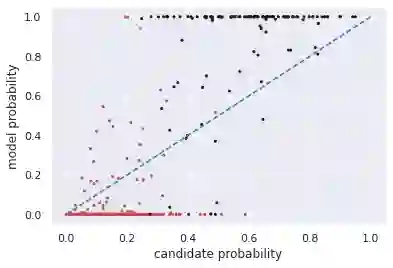
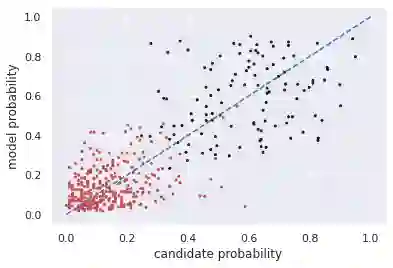
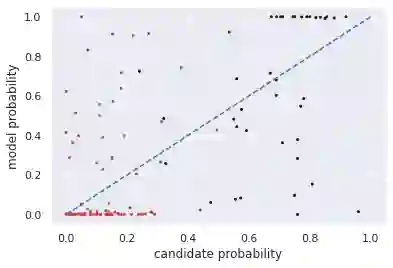
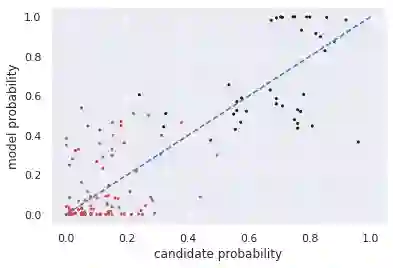
Multiple choice exams are widely used to assess candidates across a diverse range of domains and tasks. To moderate question quality, newly proposed questions often pass through pre-test evaluation stages before being deployed into real-world exams. Currently, this evaluation process is manually intensive, which can lead to time lags in the question development cycle. Streamlining this process via automation can significantly enhance efficiency, however, there's a current lack of datasets with adequate pre-test analysis information. In this paper we analyse the Cambridge Multiple-Choice Questions Reading Dataset; a multiple-choice comprehension dataset of questions at different target levels, with corresponding candidate selection distributions. We introduce the task of candidate distribution matching, propose several evaluation metrics for the task, and demonstrate that automatic systems trained on RACE++ can be leveraged as baselines for our task. We further demonstrate that these automatic systems can be used for practical pre-test evaluation tasks such as detecting underperforming distractors, where our detection systems can automatically identify poor distractors that few candidates select.
翻译:多项选择考试被广泛用于评估不同领域和任务中的考生水平。为了调控题目质量,新提出的试题在部署到实际考试前通常会经过预测试评估阶段。当前,这一评估过程高度依赖人工操作,可能导致试题开发周期出现时间延迟。通过自动化简化该流程可显著提升效率,但当前缺乏包含充分预测试分析信息的数据集。本文分析了剑桥选择题阅读数据集:该数据集包含不同目标级别的多项选择理解试题及其对应的候选选择分布。我们引入了候选分布匹配任务,提出了该任务的若干评估指标,并证明基于RACE++训练的自动化系统可作为该任务的基线模型。进一步研究表明,这些自动化系统可用于实际预测试评估任务,例如检测表现不佳的干扰项——我们的检测系统能自动识别少数考生选择的劣质干扰项。