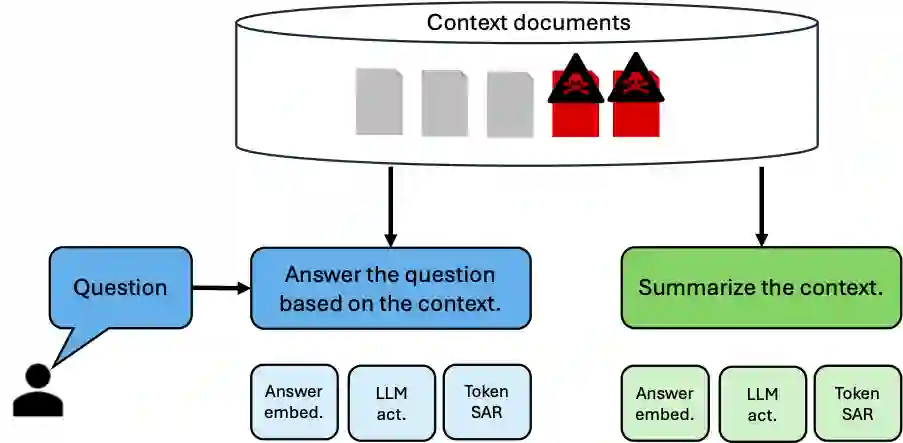
Retrieval augmented generation systems have become an integral part of everyday life. Whether in internet search engines, email systems, or service chatbots, these systems are based on context retrieval and answer generation with large language models. With their spread, also the security vulnerabilities increase. Attackers become increasingly focused on these systems and various hacking approaches are developed. Manipulating the context documents is a way to persist attacks and make them affect all users. Therefore, detecting compromised, adversarial context documents early is crucial for security. While supervised approaches require a large amount of labeled adversarial contexts, we propose an unsupervised approach, being able to detect also zero day attacks. We conduct a preliminary study to show appropriate indicators for adversarial contexts. For that purpose generator activations, output embeddings, and an entropy-based uncertainty measure turn out as suitable, complementary quantities. With an elementary statistical outlier detection, we propose and compare their detection abilities. Furthermore, we show that the target prompt, which the attacker wants to manipulate, is not required for a successful detection. Moreover, our results indicate that a simple context summary generation might even be superior in finding manipulated contexts.
翻译:检索增强生成系统已成为日常生活中不可或缺的组成部分。无论是在互联网搜索引擎、电子邮件系统还是服务聊天机器人中,这些系统都基于上下文检索和大型语言模型的答案生成。随着其普及,安全漏洞也随之增加。攻击者日益聚焦于这些系统,并开发出各种入侵方法。操纵上下文文档是一种使攻击持续存在并影响所有用户的方式。因此,及早检测受损的对抗性上下文文档对安全至关重要。虽然监督方法需要大量标注的对抗性上下文,但我们提出了一种无监督方法,能够检测零日攻击。我们进行了一项初步研究,以展示对抗性上下文的合适指标。为此,生成器激活、输出嵌入以及基于熵的不确定性度量被证明是合适且互补的量。通过基本的统计离群值检测,我们提出并比较了它们的检测能力。此外,我们表明,攻击者想要操纵的目标提示并非成功检测所必需。而且,我们的结果表明,简单的上下文摘要生成在发现被操纵的上下文方面甚至可能更优。