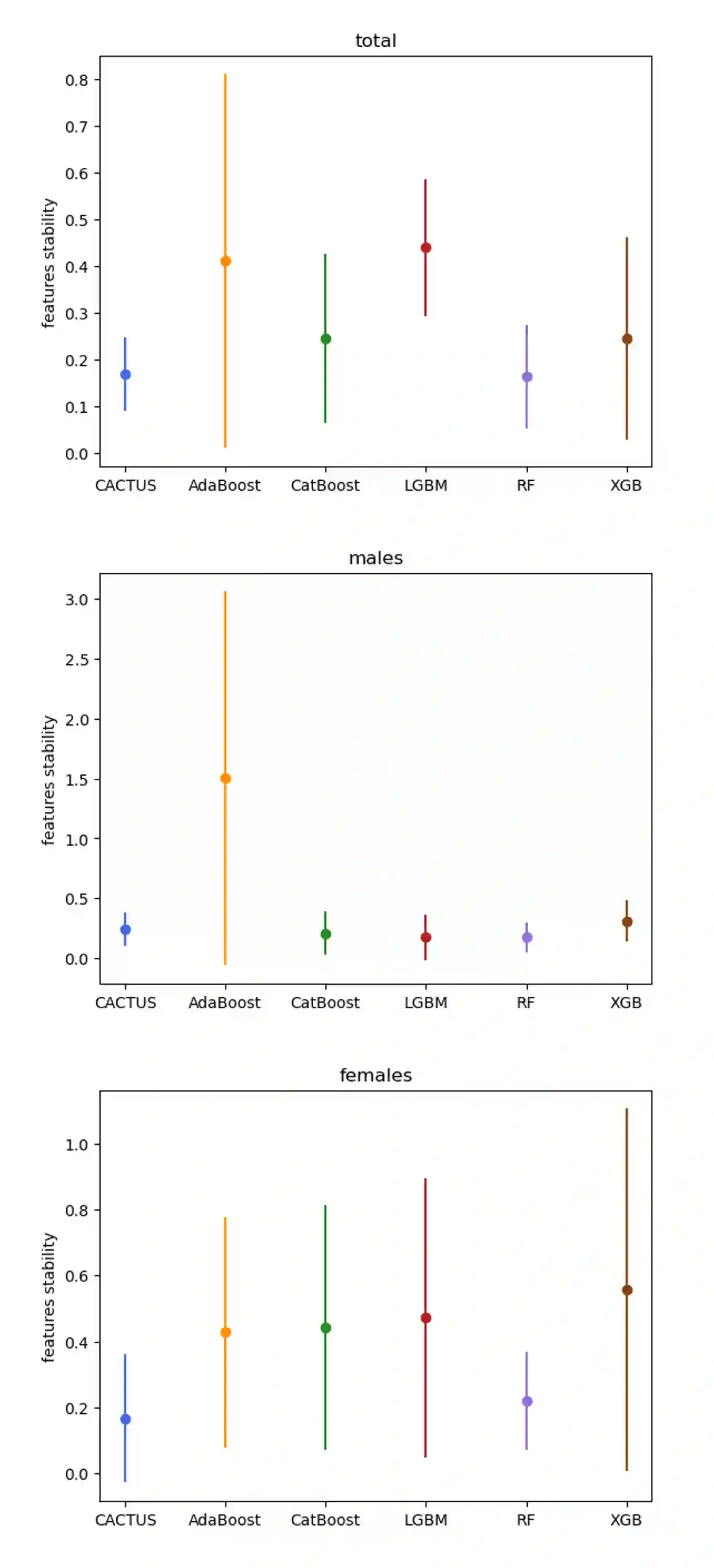
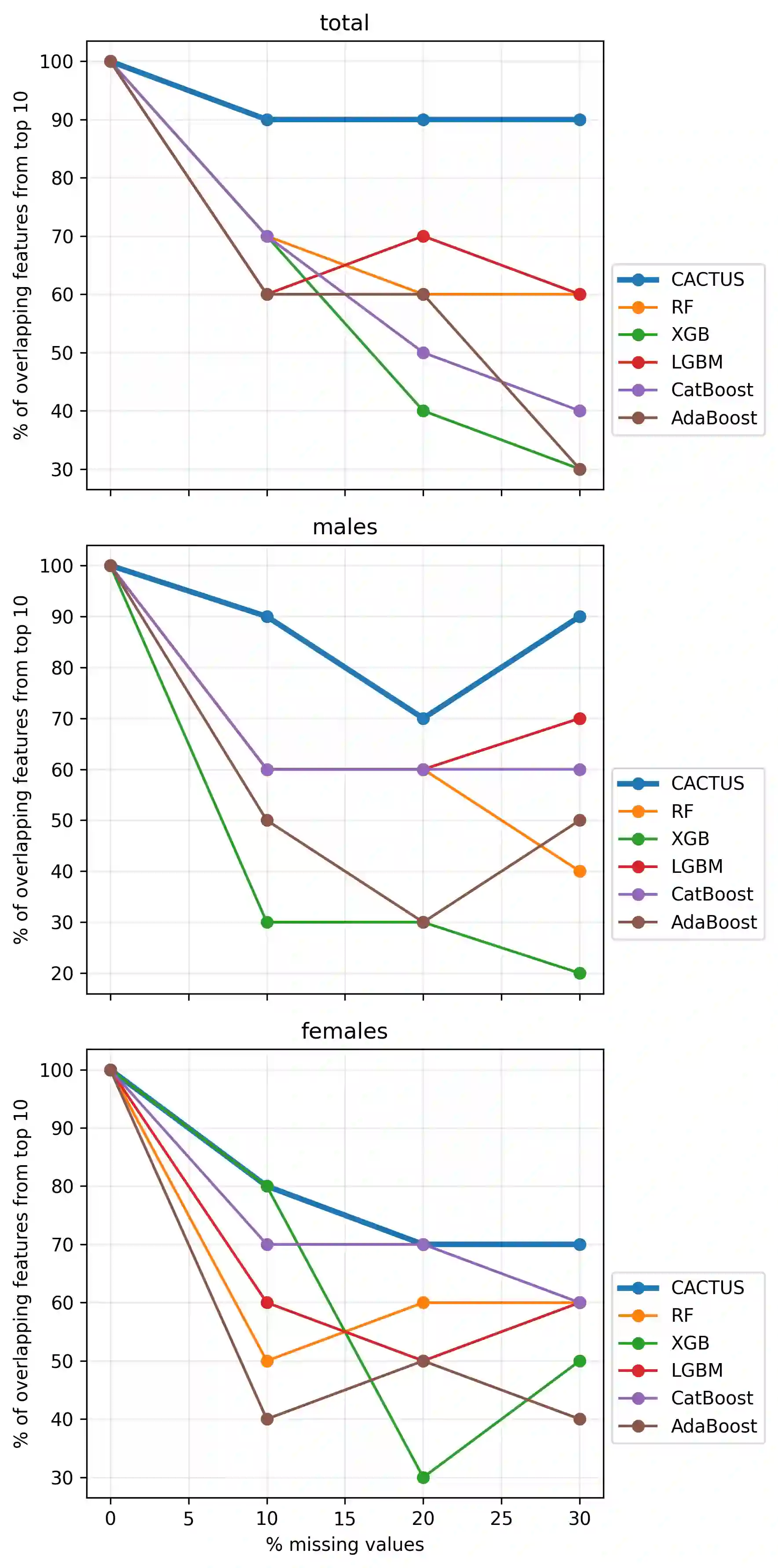
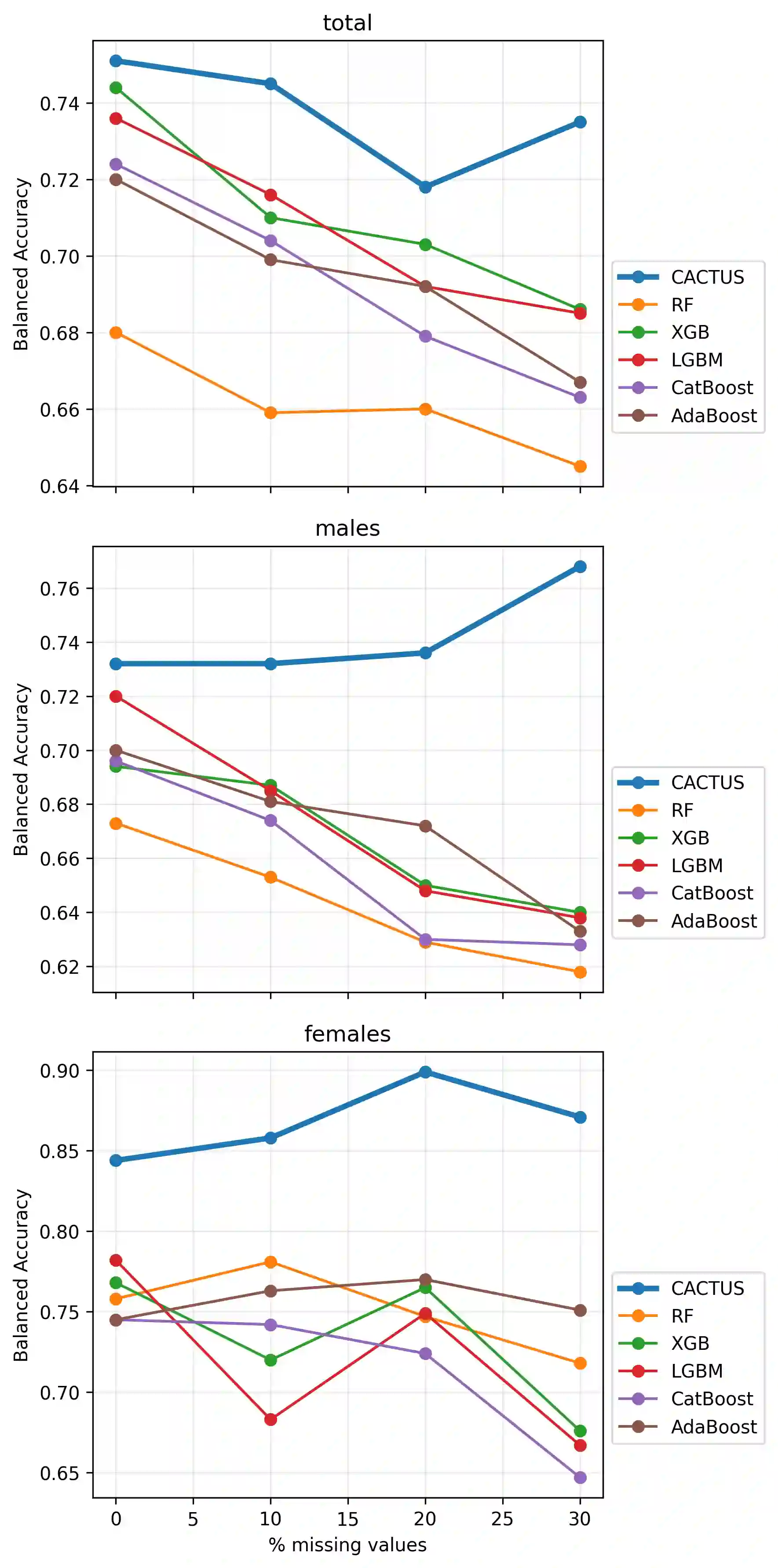
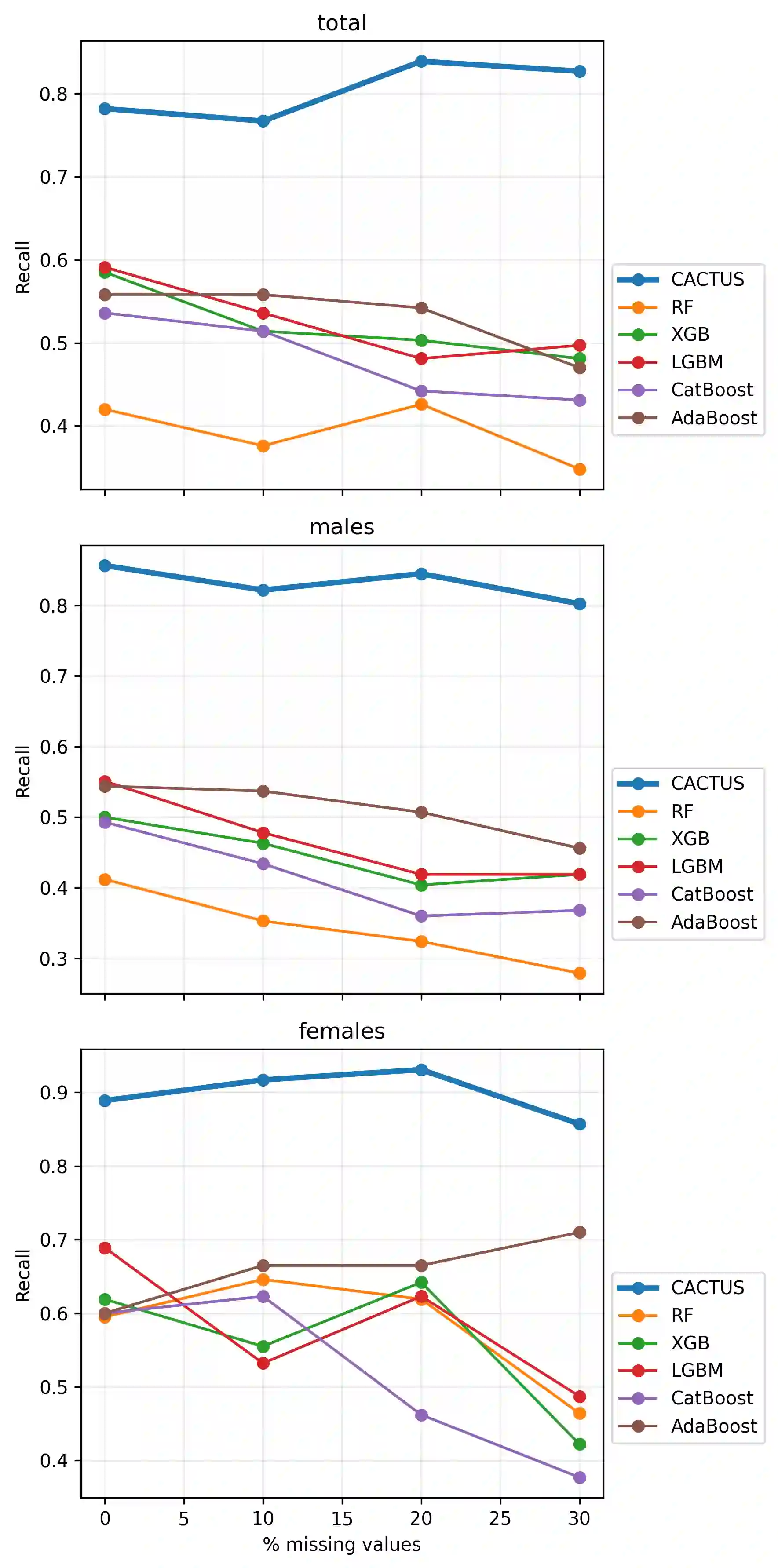
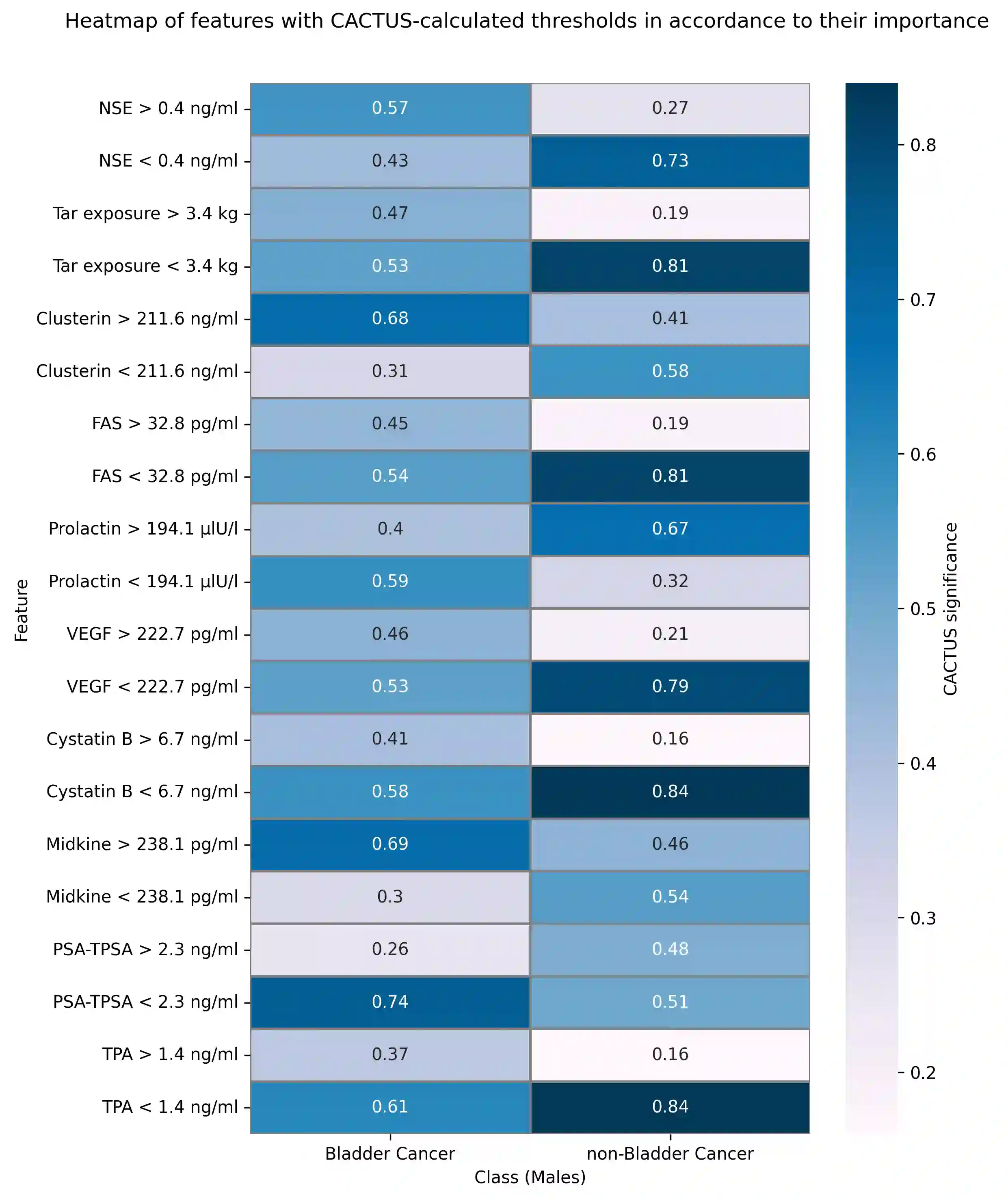
Machine learning models are increasingly applied to biomedical data, yet their adoption in high stakes domains remains limited by poor robustness, limited interpretability, and instability of learned features under realistic data perturbations, such as missingness. In particular, models that achieve high predictive performance may still fail to inspire trust if their key features fluctuate when data completeness changes, undermining reproducibility and downstream decision-making. Here, we present CACTUS (Comprehensive Abstraction and Classification Tool for Uncovering Structures), an explainable machine learning framework explicitly designed to address these challenges in small, heterogeneous, and incomplete clinical datasets. CACTUS integrates feature abstraction, interpretable classification, and systematic feature stability analysis to quantify how consistently informative features are preserved as data quality degrades. Using a real-world haematuria cohort comprising 568 patients evaluated for bladder cancer, we benchmark CACTUS against widely used machine learning approaches, including random forests and gradient boosting methods, under controlled levels of randomly introduced missing data. We demonstrate that CACTUS achieves competitive or superior predictive performance while maintaining markedly higher stability of top-ranked features as missingness increases, including in sex-stratified analyses. Our results show that feature stability provides information complementary to conventional performance metrics and is essential for assessing the trustworthiness of machine learning models applied to biomedical data. By explicitly quantifying robustness to missing data and prioritising interpretable, stable features, CACTUS offers a generalizable framework for trustworthy data-driven decision support.
翻译:机器学习模型在生物医学数据中的应用日益广泛,但其在高风险领域的采纳仍受限于鲁棒性不足、可解释性有限以及在真实数据扰动(如缺失)下学习特征的不稳定性。具体而言,即使预测性能优异的模型,若其关键特征随数据完整性变化而波动,仍可能无法赢得信任,这会损害结果的可复现性及后续决策。本文提出CACTUS(用于揭示结构的综合抽象与分类工具),一个明确为解决小型、异质且不完整临床数据集中的上述挑战而设计的可解释机器学习框架。CACTUS整合了特征抽象、可解释分类与系统化的特征稳定性分析,以量化信息性特征在数据质量下降过程中被保持的一致性程度。基于一个包含568名膀胱癌评估患者的真实世界血尿队列,我们在随机引入缺失数据的受控水平下,将CACTUS与包括随机森林和梯度提升方法在内的广泛使用的机器学习方法进行了基准比较。我们证明,CACTUS在取得竞争性或更优预测性能的同时,能随着缺失比例的增加(包括在性别分层分析中)保持显著更高的高排名特征稳定性。我们的结果表明,特征稳定性提供了与传统性能指标互补的信息,对于评估应用于生物医学数据的机器学习模型的可信度至关重要。通过显式量化对缺失数据的鲁棒性并优先选择可解释、稳定的特征,CACTUS为可信的数据驱动决策支持提供了一个可推广的框架。