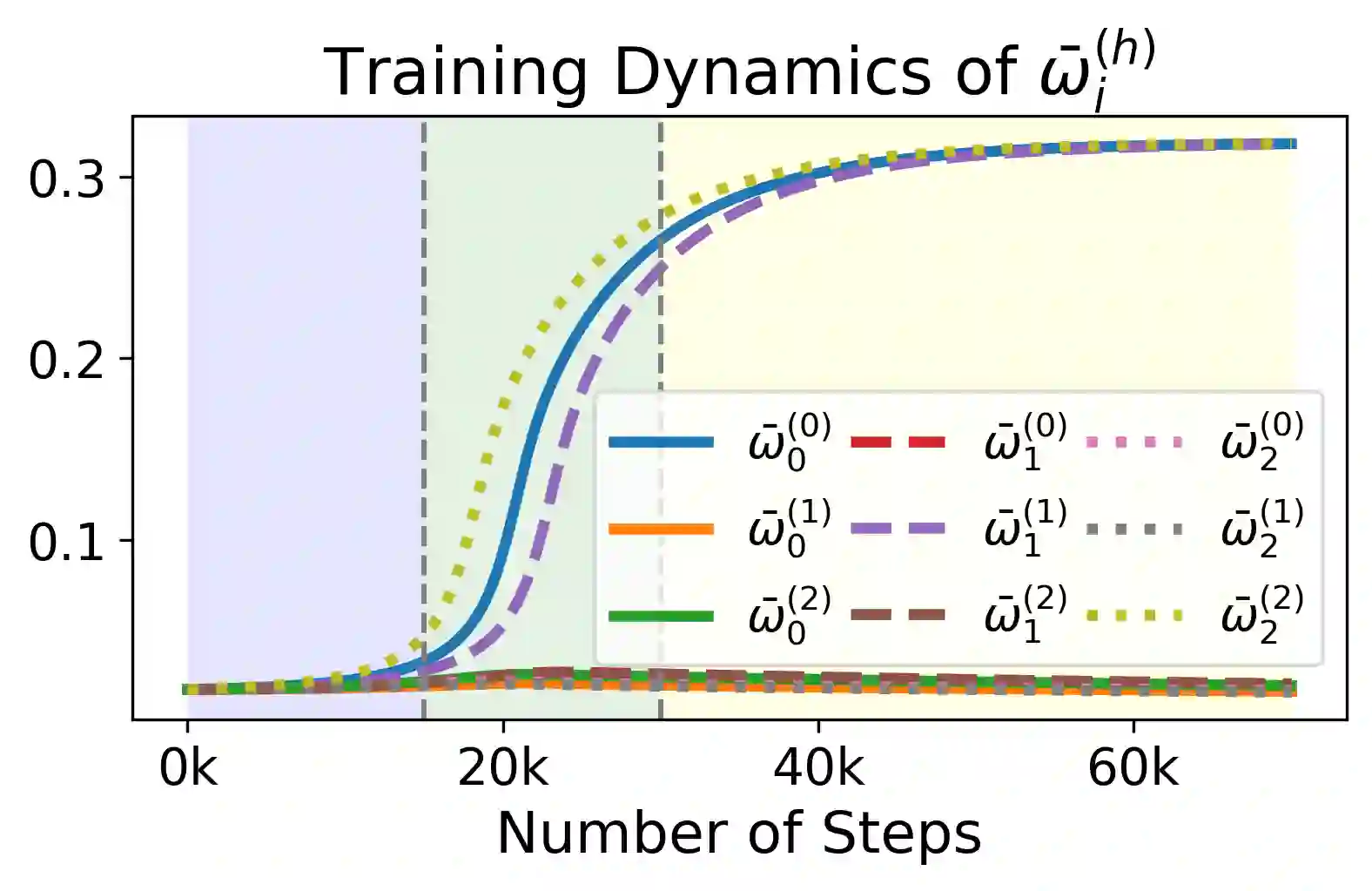
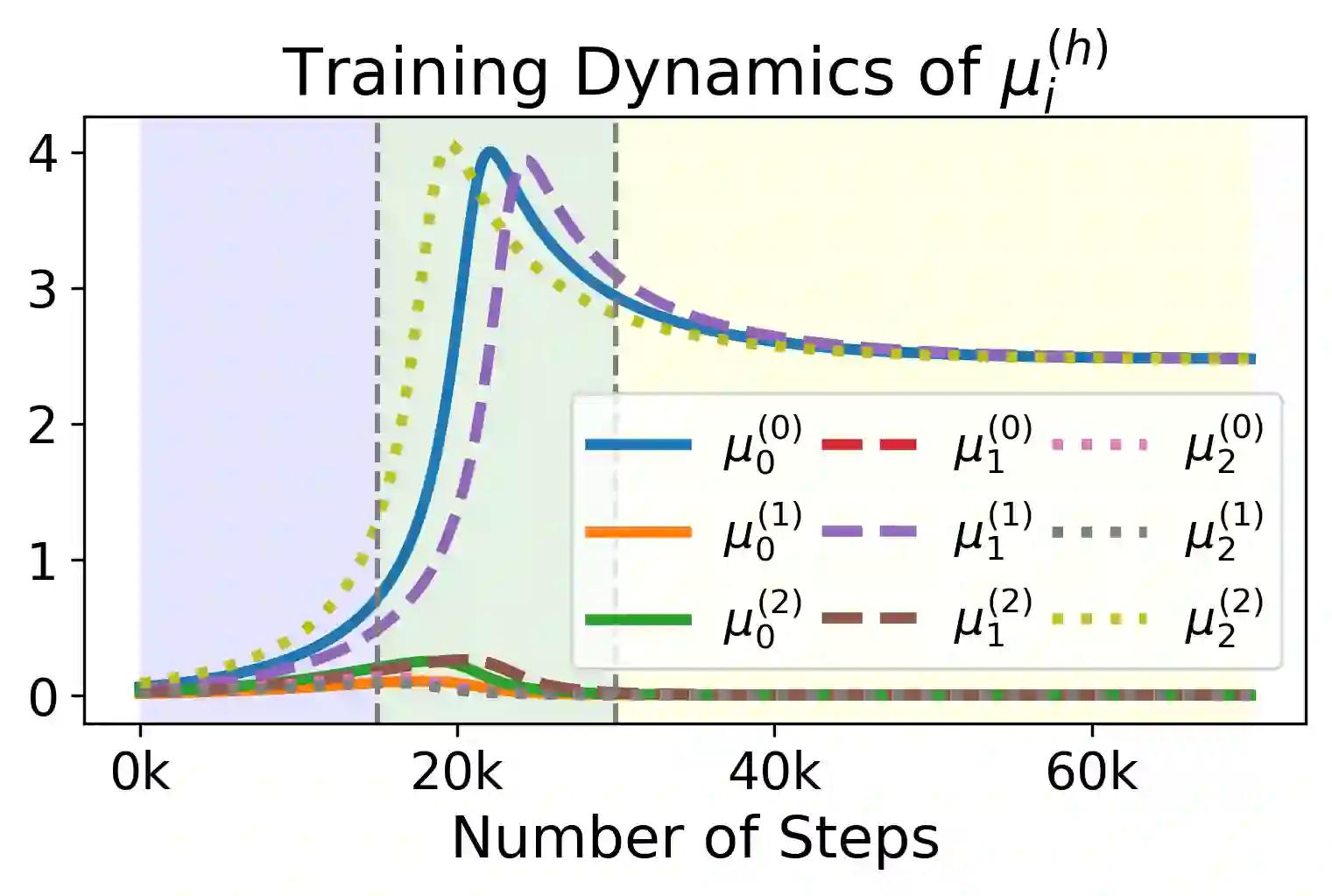
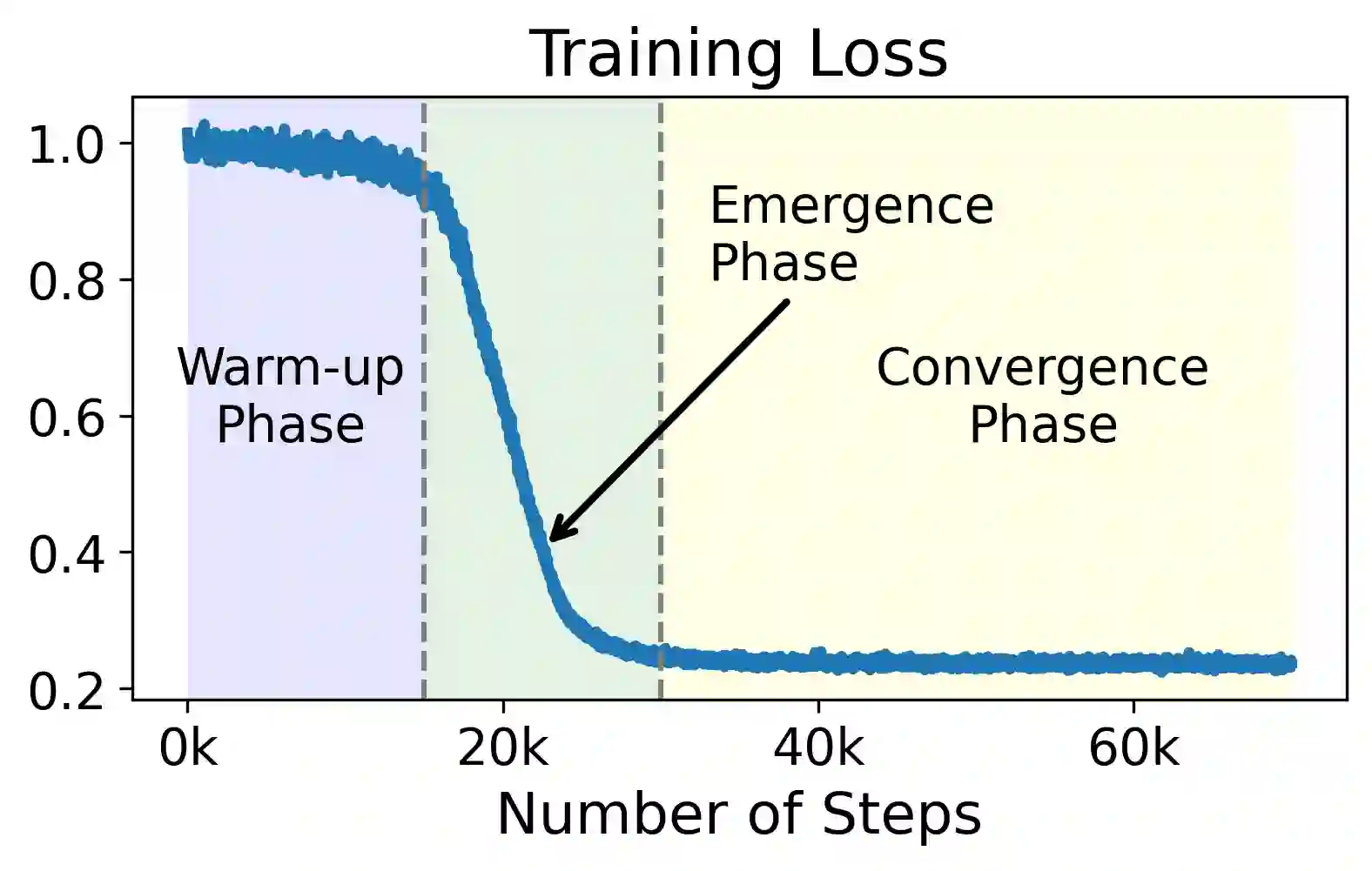
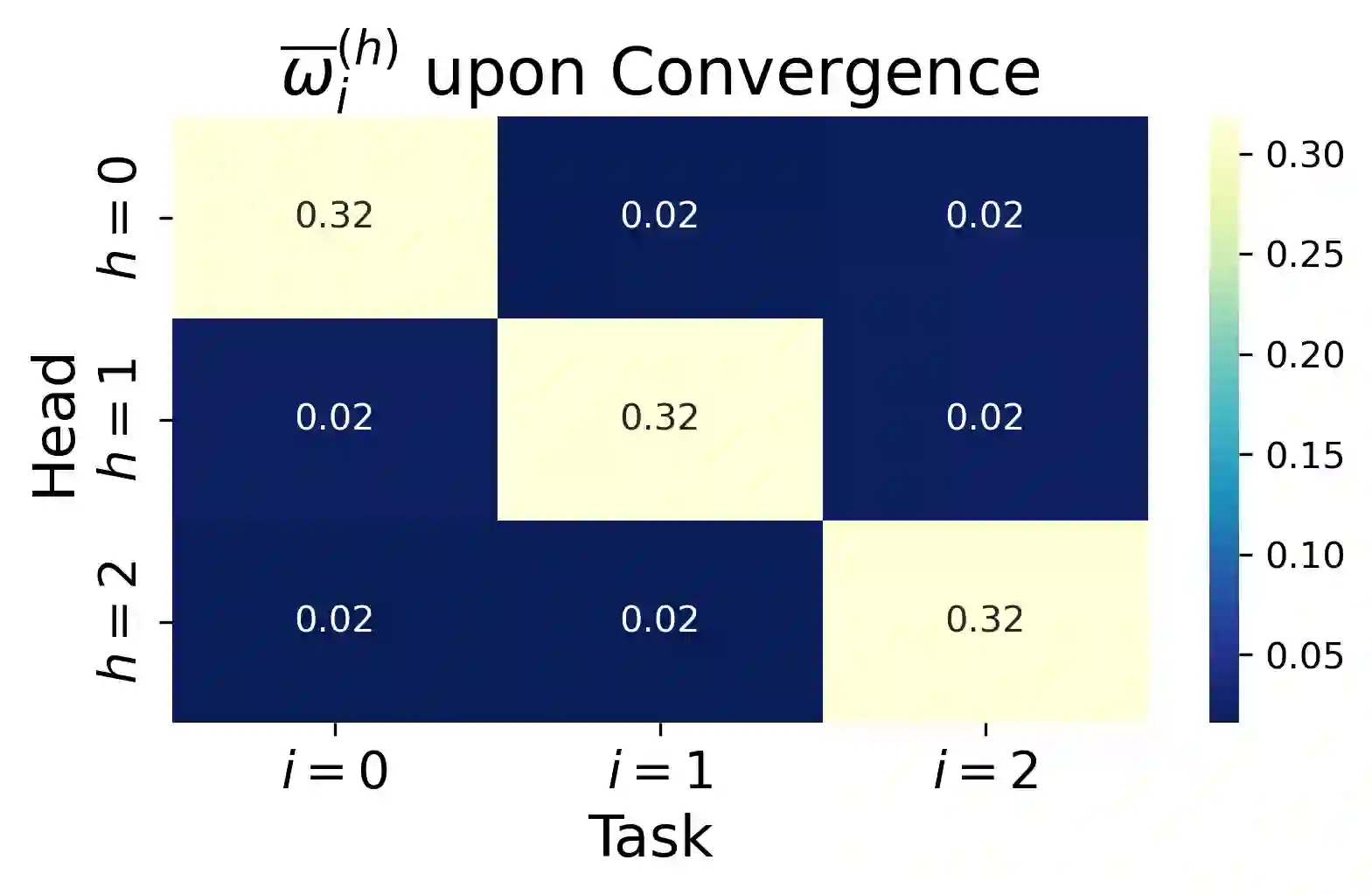
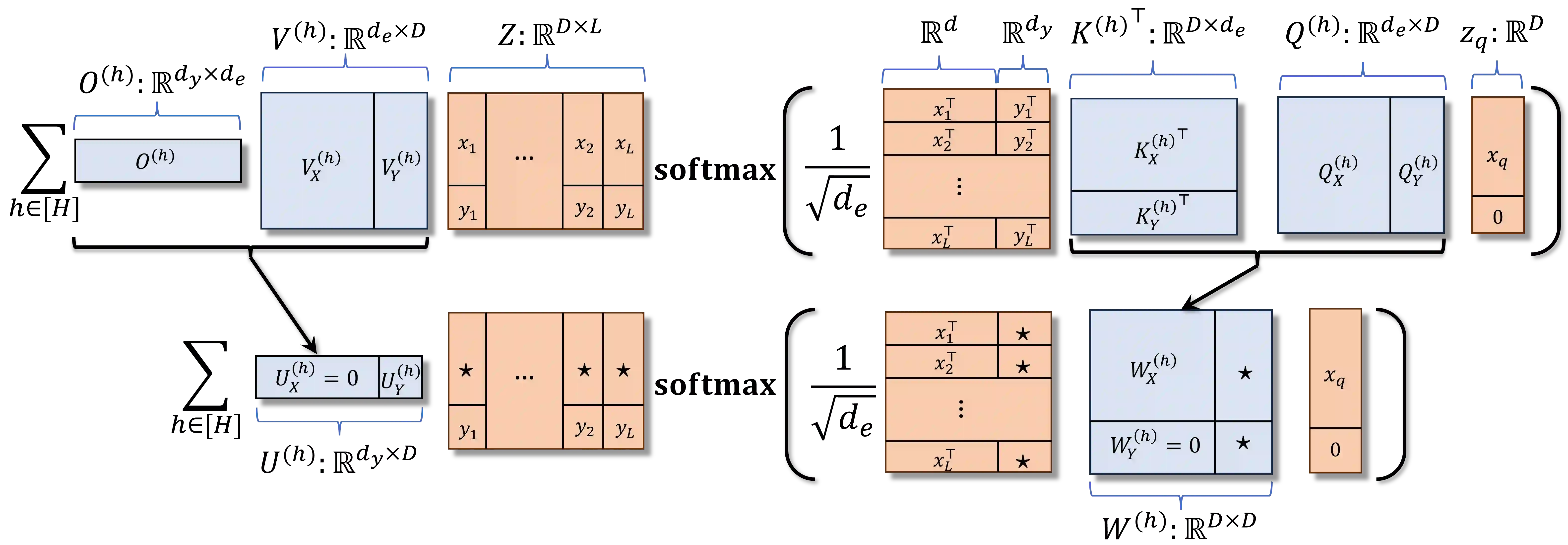
We study the dynamics of gradient flow for training a multi-head softmax attention model for in-context learning of multi-task linear regression. We establish the global convergence of gradient flow under suitable choices of initialization. In addition, we prove that an interesting "task allocation" phenomenon emerges during the gradient flow dynamics, where each attention head focuses on solving a single task of the multi-task model. Specifically, we prove that the gradient flow dynamics can be split into three phases -- a warm-up phase where the loss decreases rather slowly and the attention heads gradually build up their inclination towards individual tasks, an emergence phase where each head selects a single task and the loss rapidly decreases, and a convergence phase where the attention parameters converge to a limit. Furthermore, we prove the optimality of gradient flow in the sense that the limiting model learned by gradient flow is on par with the best possible multi-head softmax attention model up to a constant factor. Our analysis also delineates a strict separation in terms of the prediction accuracy of ICL between single-head and multi-head attention models. The key technique for our convergence analysis is to map the gradient flow dynamics in the parameter space to a set of ordinary differential equations in the spectral domain, where the relative magnitudes of the semi-singular values of the attention weights determines task allocation. To our best knowledge, our work provides the first convergence result for the multi-head softmax attention model.
翻译:我们研究了对用于多任务线性回归上下文学习的多头softmax注意力模型进行梯度流的动力学过程。我们证明了在合适的初始化选择下,梯度流的全局收敛性。此外,我们证明梯度流动力学过程中会出现一个有趣的"任务分配"现象,其中每个注意力头专注于解决多任务模型中的单个任务。具体而言,我们证明梯度流动力学可划分为三个阶段——预热阶段(损失下降较慢,注意力头逐渐建立对单个任务的偏好)、涌现阶段(每个头选择单个任务,损失快速下降)以及收敛阶段(注意力参数收敛至极限)。进一步地,我们证明了梯度流的最优性:梯度流学习得到的极限模型与最优多头softmax注意力模型在常数因子范围内性能相当。我们的分析还刻画了单头与多头注意力模型在上下文学习预测精度上的严格分离。收敛分析的关键技术是将参数空间中的梯度流动力学映射到谱域中的一组常微分方程,其中注意力权重半奇异值的相对大小决定了任务分配。据我们所知,本文首次为多头softmax注意力模型提供了收敛性结果。