
导读
大语言模型在作为知识库部署时,需要不断更新事实知识以保持时效性。“顺序编辑”允许对模型参数进行多次局部修改,而无需从头重训。然而,现有方法往往堆叠各种正则化或约束机制(如零空间投影、后处理算子、约束优化目标)来维持编辑稳定性,但这些机制是否必要、核心原理是什么,始终缺乏系统性的理论回答。由 Bosch AI 中心与华东师范大学的研究者(Zheng Wang, Kaixuan Zhang, Wanfang Chen 等)完成的这篇 ICML 2026 论文,通过严格的优化分析,揭示了一个简洁而深刻的洞察:一次编辑(One-Time Editing, OTE)与顺序编辑(Sequential Editing, SE)在数学上本质等价,稳定性的根本来源是正确累积所有编辑的约束,而非任何专门的正则化技巧。基于这一发现,论文证明了大量常见正则化策略完全多余,并提出了一个极简且通用的设计准则(ℓₜ(Δ) 公式),甚至能进一步处理冲突编辑。这篇论文为日益复杂的知识编辑领域提供了“阿里阿德涅之线”——一条走出正则化迷宫、通往可解释且可靠更新的清晰路径。对于从事大模型知识更新、持续学习或参数微调的研究者与工程师而言,它颠覆了固有的设计直觉,值得深度精读。
论文基本信息

**
**
摘要
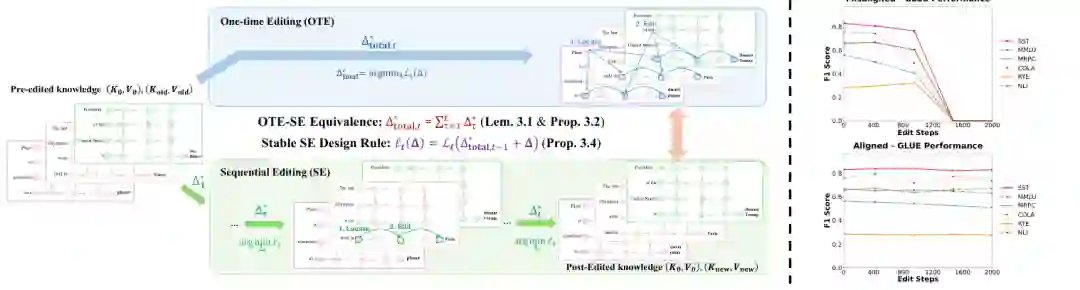
引言:论文要解决什么问题
随着大语言模型作为事实知识存储库的广泛应用(知识通常以 (subject, relation, object) 三元组形式表示),在动态环境中精确更新或修正特定结构化知识而不重训模型的能力成为核心挑战。参数修改类方法(如定位-编辑范式)先定位与目标事实相关的参数,再施加约束更新。为了支持顺序(终身)编辑,近年来涌现了多种机制:AlphaEdit 的零空间投影、隐式正则化的后处理算子、约束优化目标等。这些设计旨在减轻编辑间的干扰,保持已编辑知识。其中 AlphaEdit 因其突出的经验稳定性而引人注目。然而,这些机制的多样性和复杂性引出一个基本问题:确保成功且可靠的顺序模型编辑的基本要素到底是什么?以往研究(如 Li 等人 2024;Gupta 等人 2024;Li & Chu 2024)主要基于实证,缺乏统一理论,未能完全解释 AlphaEdit 等方法的成功。本文试图通过四个研究问题给出原理性答案:RQ1:AlphaEdit 的经验成功在多大程度上归因于其零空间投影机制?RQ2:超越 AlphaEdit,什么一般原则支配有效顺序编辑,能否提炼为有理论依据的设计准则?RQ3:在已经稳定可靠的模型更新之上应用复杂正则化策略的实际影响是什么?RQ4(隐含在扩展中):如何处理冲突编辑?本文通过对定位-编辑方法的统一 OLS 公式化,证明了 OTE 与 SE 的数学等价性,从而回答了这些问题——稳定性源自约束的正确累积,而非特殊机制。
方法:核心思路与技术路线
整体视角:从定位-编辑到 OLS 公式化
本文方法的核心是建立一个统一的优化视角。大多数定位-编辑方法可以被形式化为普通最小二乘(OLS)问题,通常存在闭式解。对于一次编辑(OTE),目标是找到一组参数变化 Δ 使得更新后的模型在新知识上满足约束,同时尽可能不损坏已有知识。对于顺序编辑(SE),编辑按顺序施加:在时刻 t,基于当前模型状态施加一个新的事实更新,同时希望保持之前所有编辑的结果。
核心证明:OTE-SE 等价性
推广到更广泛的编辑目标
论文并未止步于 OLS 特例。作者进一步将等价性推广到更一般的编辑目标类。对应 Proposition 3.4,论文提出了稳定 SE 的设计规则:ℓₜ(Δ) = ℒₜ(Δ_total, Ω₁/∗) + Δ。其中 ℒₜ 是关于第 t 次编辑的损失函数,Δ_total 是截至当前所有编辑的总参数变化,Ω₁/∗ 表示从历史编辑中保留的某种信息(如约束的表示)。关键结论是:只要当前编辑的损失函数正确引用了累积约束(而不是仅依赖当前单独解),那么顺序编辑就能保持稳定。这意味着许多旨在“记忆”历史编辑的机制(如专门的记忆缓冲区、正则化项)在原则上是多余的——只需在每步编辑时正确纳入全局约束即可。
冲突编辑的处理
在完成对一般稳定性的理解后,论文进一步扩展框架以处理冲突编辑——即后续编辑要求与先前编辑矛盾(例如先编辑“冥王星是行星”再编辑“冥王星是矮行星”,但两者物理上冲突?实际上冲突更指同一事实的不同版本)。作者表明,通过将冲突编辑建模为约束集中存在不一致,OLS 框架可以提供鲁棒解(例如采用加权或取交/并策略)。这一扩展确保了框架在矛盾更新下依然保持一致行为,无需引入额外的正则化。
与现有方法的关系
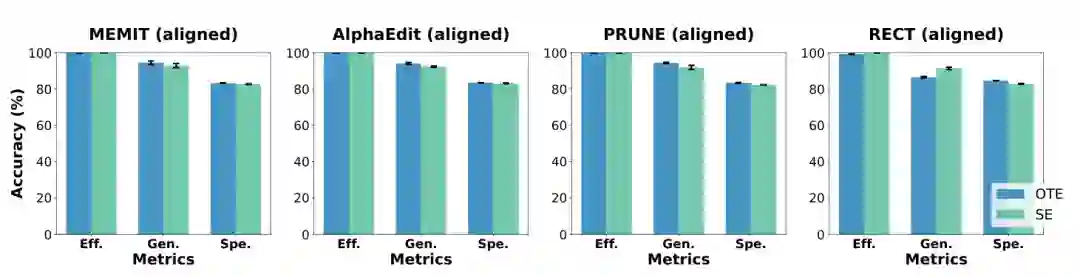
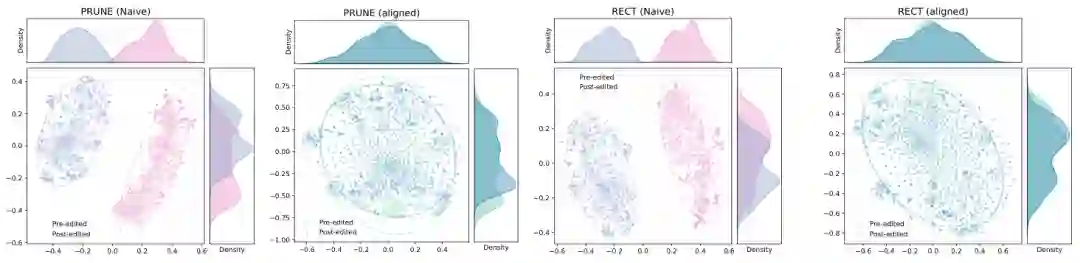
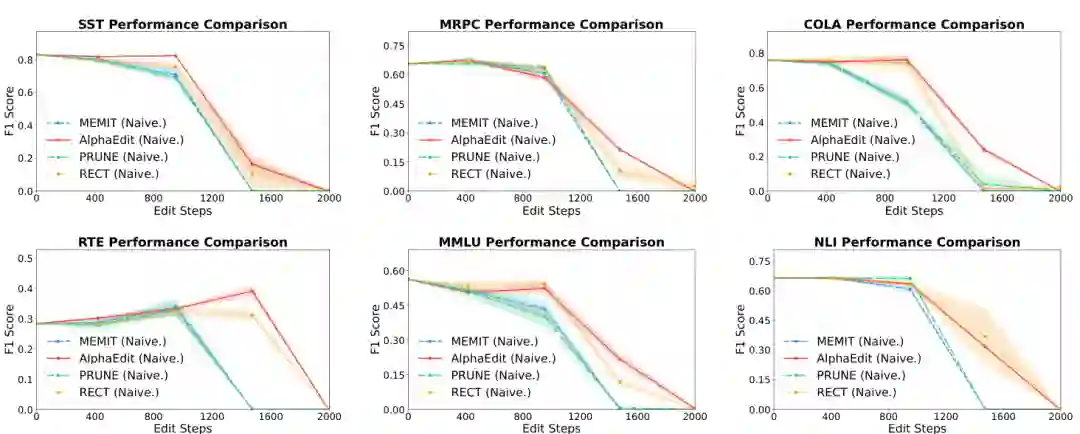
论文没有详细赘述所有定位-编辑方法,但用该统一视角解释了为何许多现有正则化策略(如 PRUNE 和 RECT 中的后处理对齐、AlphaEdit 的零空间投影)在 OTE-SE 对齐后显得冗余。实验部分对“对齐”与“未对齐”的对比直接证实了这一点。
实验:设置、指标与结果
数据集与评估任务
实验使用 GLUE 基准中的六个子任务来测试编辑后的通用能力(General Capability):SST (情感分类)、MRPC (复述检测)、CoLA (语法可接受性)、RTE (文本蕴含)、MMLU (大规模多任务理解)、NLI (自然语言推理)。选择这些任务是为了评估编辑是否破坏了模型原本的通用语言理解和推理能力。编辑测试本身在知识编辑标准数据集上进行(论文未明确指定具体编辑数据集名称,但属于结构化三元组编辑场景)。
模型与实验设置
评估了四个不同规模的模型:
- Qwen2.5 (7B) 主要模型,用于详细对比。
- GPT-2 XL (1.5B) 较小规模模型。
- GPT-J (6B) 中等规模模型。
- LLaMA-3 (8B) 大规模模型。
实验设置核心是对比 OTE 设置 和 SE 设置。在 OTE 设置下,所有编辑的约束一次性合并求解(即理想的一次编辑场景)。在 SE 设置下,按照顺序逐次应用编辑。如果模型实现是 OTE 对齐的(即顺序编辑的内部机制等价于 OTE),则两者性能应一致。反之,未对齐的 SE 实现会导致性能显著下降。
主要结果
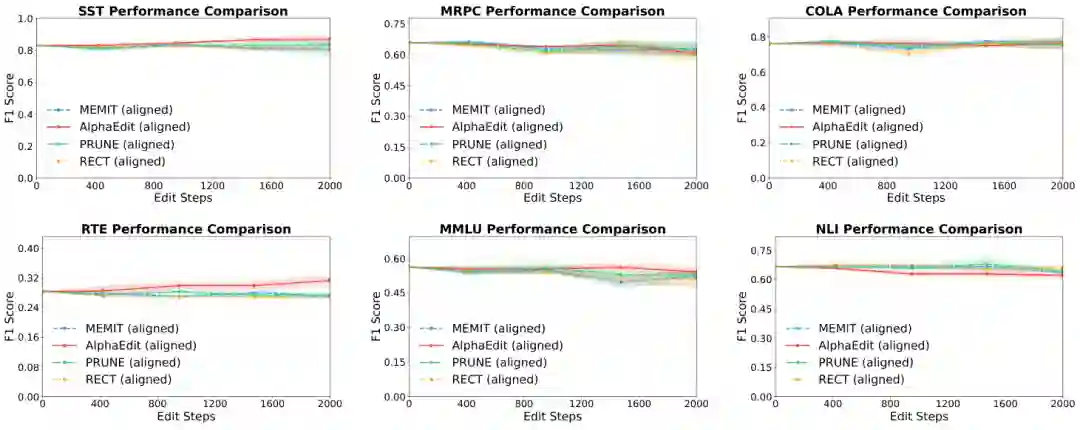
消融与分析
结论:贡献、局限与启发
贡献
- 理论奠基:首次通过严格的优化分析证明了顺序编辑与一次编辑的数学等价性,为知识编辑领域提供了统一理论框架。
- 简化设计:揭示了稳定性源于约束的正确累积而非专门正则化,从而排除了大量非必要的复杂机制。
- 实用准则:提出了可操作的稳定 SE 设计规则(ℓₜ 公式),并展示了如何将其用于改进现有方法(如 PRUNE, RECT 的对齐)。
- 冲突处理:扩展框架至矛盾编辑,提升了鲁棒性。
- 实证验证:在多个大模型上(7B 到 8B)和多任务验证了核心理论,代码开源(GitHub链接)。
局限
原文未明确说明局限性。根据论文内容推测,可能存在的局限包括:理论框架主要适用于基于 OLS 的定位-编辑方法,对于其他范式(如元学习、外部记忆)的覆盖程度未讨论;实验主要针对英文模型和 GLUE 基准,对多语言或更大模型(如 70B+)的验证未涉及;冲突编辑处理的具体算法细节未展开。但论文未明确声明这些局限,故写“原文未明确说明”。
启发
- 研究者应重新审视现有顺序编辑方法中附加的正则化模块,优先确保“约束累积”原则的实现,而非引入新的复杂性。
- 实践者可基于 OTE-SE 等价性简化代码实现:只要每步编辑的损失函数正确包含历史约束,即可获得稳定的顺序更新,无需额外记忆或正则项。
- 对于未来工作,该框架可拓展至非结构化编辑、多模态模型更新等领域,为持续学习提供更简洁的理论基石。