

摘要
长程多模态智能体高度依赖外部记忆;然而,基于相似性的检索机制往往会召回陈旧、低可信度或相互冲突的信息项,进而引发智能体的过度自信错误。本文提出了多模态记忆智能体 (Multimodal Memory Agent, MMA)。该架构通过整合来源可信度、时间衰减以及冲突感知网络共识,为每个检索到的记忆项分配动态可靠性评分,并利用该信号对证据进行重加权,在支持信息不足时选择弃权。
此外,我们推出了 MMA-Bench,这是一个通过程序化生成的基准测试集,用于评估具备受控说话者可靠性及结构化图文矛盾环境下的信念动态。通过该框架,我们发现了**“视觉安慰剂效应” (Visual Placebo Effect)**,揭示了基于 RAG 的智能体如何从基础模型中继承潜在的视觉偏见。实验结果显示:在 FEVER 数据集上,MMA 在保持基准准确率的同时,将方差降低了 35.2% 并提升了选择性效用;在 LoCoMo 安全导向配置下,MMA 提高了执行准确率并减少了错误回答;在 MMA-Bench 测试中,MMA 在视觉模式下达到了 41.18% 的 TypeB 准确率,而基准模型在相同协议下表现溃缩至 0.0%。 代码已开源至:https://github.com/AIGeeksGroup/MMA。
1 引言
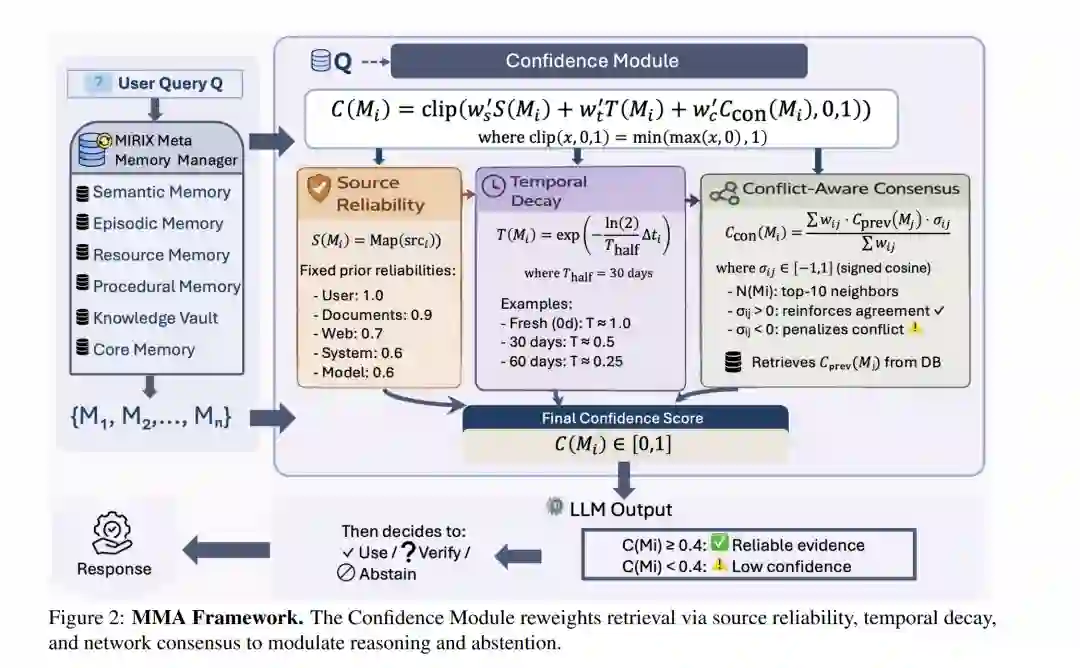
存储增强型大语言模型(LLM)智能体日益成为长程交互系统的基石,这类系统必须能够随时间推移保留并更新用户特定的上下文(Park et al., 2023; Guo et al., 2024)。近期的存储架构引入了更具结构化的存储管理与控制机制,在对话基准测试中取得了显著成果(Wang and Chen, 2025; Packer et al., 2024)。然而,当智能体必须在噪声输入、陈旧信息和相互矛盾的记忆环境下运行时,可靠性仍是一个瓶颈。 一个核心限制在于,许多存储系统在推理过程中默认将检索到的项视为同等可靠。但在实践中,信息质量差异巨大:来源的可信度各异,事实会随时间过时,且新检索的内容可能与此前存储的内容发生冲突。若缺乏显式的可靠性建模,低质量记忆可能会在多步推理中传播,并放大下游误差(Xiong et al., 2025)。更复杂的是,基于 LLM 的智能体会产生流利但失真的输出(幻觉),这掩盖了不确定性并导致过度自信的回答,在现实应用中引发了实际的安全风险(Ji et al., 2023)。即便在支持信息不足或不一致时,它们也经常做出回应,产生随后被证实为错误的自信回答。在错误代价高昂的安全敏感型应用中,这种评估证据充足性及仲裁冲突能力的缺失显得尤为突出。 鉴于这些挑战,我们的初衷包含两个方面:(i) 存储层级的可靠性评估,以及 (ii) 与认识论审慎性(Epistemic Prudence)激励相一致的评价体系。针对不可靠记忆的传播,智能体需要一种机制,通过综合考量来源可信度、时间近颖性(Temporal Recency)以及与相关记忆的一致性,将可信信息与存疑内容区分开来。针对认识论意识,智能体必须能够检测证据不足并在适当时选择弃权(Varshney et al., 2023; Kuhn et al., 2023)。测试这种能力需要激励相容的框架(如弃权感知评分),此类框架应奖励合理的弃权并惩罚过度自信的错误,从而超越仅关注准确率的指标(Quach et al., 2024; Yadkori et al., 2024)。这种方法更符合实际部署需求(Geifman and El-Yaniv, 2017),即承认不确定性通常优于给出自信的错误答案。 为了应对这些挑战,我们提出了 MMA(多模态记忆智能体),这是一种具备选择性预测能力的置信度感知记忆智能体。本项研究主要有三大贡献: * 首先,我们构建了一个推理时存储项级置信度评分框架,利用来源可信度、时间衰减和冲突感知网络共识对检索到的记忆进行重加权。如 Figure 1 所示,该可靠性信号通过优先考虑来源可靠的证据并弱化陈旧或支持较弱的描述,缓解了基于相似性检索的陷阱。 * 其次,我们引入了 MMA-Bench,这是一个程序化生成且参数化的基准测试集。它在受控的来源可靠性先验和结构化的图文冲突下,对长程信念修正(Belief Revision)施加压力,并采用奖励校准弃权、惩罚过度自信错误的评分机制。 * 第三,我们在 FEVER、LoCoMo 和 MMA-Bench 上对 MMA 进行了评估。在 FEVER(500 个样本,3 个随机种子)上,MMA 在匹配 MIRIX 基准原始准确率(59.93% vs. 59.87%)的同时,将跨种子的标准差降低了 35.2%(±1.62% vs. ±2.50%),并在弃权奖励下获得了更高的选择性得分($\alpha=0.2$ 时为 0.6484 vs. 0.6468)。在 LoCoMo 上,一种安全导向的 MMA 配置(不含共识机制)在提升执行准确率(79.64% vs. 78.96%)的同时减少了错误回答(298 vs. 317)。在具有高噪声且检索极具挑战性的 MMA-Bench 上,MMA 在视觉模式下实现了 41.18% 的 Type-B 准确率(可靠性反转),而 MIRIX 基准在相同评估协议下的表现则溃缩至 0.0%。
