
多智能体合作规划一直是强化学习和决策领域的难点。当智能体数量增加时,联合动作空间呈指数级增长,传统蒙特卡洛树搜索(MCTS)在有限搜索预算下几乎无法有效探索。这个问题在多智能体星际争霸(SMAC)、矩阵博弈等场景中尤为突出——智能体之间需要协调行动,而协调偏差往往隐藏在指数组合中,现有方法要么假设回报可分解为单智能体线性叠加,要么仍依赖于枚举联合动作空间,导致搜索效率低下或错过关键的协调改进。
针对这一痛点,乔治华盛顿大学和东北大学的 Sizhe Tang、Zuyuan Zhang、Mahdi Imani 和 Tian Lan 提出了 NonZero 框架,并已被 ICML 2026 接收为 Spotlight。核心思想是:不需要枚举所有联合动作,而是通过一个低维非线性预测器来引导候选动作的扩展,利用交互评分机制自动识别单智能体和双智能体层面的协调收益,从而将每步搜索的分支因子固定下来。本文提出的 NonUCT 候选规则从非线性 bandit 角度出发,具有次线性局部遗憾保证,理论上保证能够逼近图局部最优。 这篇论文值得所有关注多智能体规划、MCTS 扩展以及模型基强化学习的读者精读:它不仅给出了一套完整的框架和理论分析,还在 MatGame、SMAC 和 SMACv2 上展示了优于强基线的样本效率和最终性能。更重要的是,它提供了一个可落地的思路——用低维非线性表示 + 交互候选扩展来绕过组合爆炸,这对设计可扩展的多智能体规划算法具有直接启发。
论文基本信息

摘要
MCTS 在合作多智能体领域中扩展性差,因为扩展时必须考虑指数级增长的联合动作集合,这严重限制了实际搜索预算下的探索。NonZero 通过在一个低维非线性表示上运行代理引导选择(surrogate-guided selection),使用交互引导的候选规则(interaction-guided proposal rule),避免直接探索完整的联合动作空间,从而保持多智能体 MCTS 的可计算性。 探索过程依赖一个交互评分(interaction score):单智能体偏差按预测增益排序,双智能体偏差则通过一种混合差异度量(mixed-difference measure)来打分。这种度量能揭示协调收益——即使当单智能体单独无法改进时也能发现潜在的协调效应。论文将候选提出(candidate proposal)形式化为关于局部偏差的 bandit 问题,并推导出 NonUCT 候选规则。该规则具有次线性局部遗憾保证,无需枚举联合动作空间即可达到近似图局部最优。 实验在 MatGame、SMAC 和 SMACv2 上进行,在匹配搜索预算下,NonZero 相对于强模型基和模型无关基线,一致地提升了样本效率和最终性能。
引言:论文要解决什么问题
将 MCTS 扩展到合作多智能体规划时,核心障碍是组合动作选择问题。设共有 (n) 个智能体,每个智能体有 (d) 个候选动作,则联合动作空间大小为 (d^n)。朴素扩展会导致指数级分支因子,在实际模拟预算内迅速耗尽资源。尤其当回报存在强交互效应时,高价值结果往往需要智能体协调偏差(coordinated deviations),而未经信息引导的随机采样很难找到这些偏差。 先前的工作对这一问题进行了部分缓解,但未能彻底解决。MAZero(Liu et al., 2024)改进了模型学习和分布式规划组件,但树扩展仍然依赖于在每个节点上选择哪些联合动作,本质未摆脱 (d^n) 枚举。MALinZero(Tang et al., 2025)利用线性回报结构减少联合动作搜索,但当回报为非加性时,线性假设会遗漏需要协调的改进。价值分解方法如 VDN(Sunehag et al., 2017)和 QMIX(Rashid et al., 2020)对联合价值施加结构约束,但这些方法不支持树搜索所需的不确定性感知动作扩展(uncertainty-aware action expansion),且依然受限于分解假定的有效性。 NonZero 旨在解决这一根本矛盾:在不枚举 (d^n) 联合动作空间的前提下,让多智能体 MCTS 保持可计算性,并且能够发现那些需要协调偏差才能达到的高价值结果。论文的核心思路是:在树搜索的每个节点,先拟合一个紧凑的低维非线性预测器(low-dimensional nonlinear predictor)来估计联合动作回报,然后只评估从当前候选出发的结构化一/双智能体偏差(structured one- and two-agent deviations),通过交互评分机制决定下一步扩展哪些偏差,从而将分支因子从 (d^n) 降低到一个与 (n) 和 (d) 相关但不指数增长的常数。
方法:核心思路与技术路线
NonZero 的整体架构嵌入在 MuZero 风格的模型基规划循环中。在树搜索的每个节点,执行以下三个步骤:
1. 代理引导选择(Surrogate-Guided Selection)
首先,NonZero 维护一个 低维非线性预测器(surrogate predictor)。这个预测器用于估计任意联合动作的回报。与线性假设不同,这里允许预测器具有低维非线性结构——即它用较少的参数捕捉联合动作空间的主要变化,同时保留智能体之间的交互信息。具体实现上,预测器可以是轻量级的神经网络或核方法,其输入是智能体的局部特征(如观测、隐藏状态),输出是对联合回报的估计。 预测器的训练数据来自搜索过程中对实际联合动作的模拟采样。它不要求对所有 (d^n) 动作都精确建模,而是专注于当前候选附近的局部区域,因此能够在不提升计算负担的情况下提供有用的梯度信息。
2. 结构化的偏差评估(Structured Deviation Evaluation)
在预测器的基础上,NonZero 定义了一种 交互评分(interaction score),用于评估从当前候选动作集出发的偏差。偏差分为两类:
- 单智能体偏差 仅改变一个智能体的动作,其余保持当前候选中的选择。每个单智能体偏差的优先级按 预测增益(predicted gain)排序,即预测的回报提高量。这可以快速捕捉那些智能体可以独立改进的机会。
- 双智能体偏差 同时改变两个智能体的动作。为了评估这种协调偏差的价值,论文提出了一种 混合差异度量(mixed-difference measure)。该度量计算:在两个智能体同时改变的情况下,预测回报相对于各自单独改变的回报之差。(a_{-ij}) 表示其他智能体保持当前候选。这个度量捕捉了
交互效应:即使单智能体偏差都不产生正增益(预测回报不变或下降),同时改变两个智能体可能产生正收益——这正是协调陷阱(coordination trap)的典型情况。NonZero 给那些具有较大混合差异的双智能体偏差赋予高优先级,从而主动探索此类协调机会。
3. 候选提出形式化为非线性 Bandit 问题:NonUCT 规则
候选提出(candidate proposal)本质上是决定在每次搜索中应当探索哪些偏差。NonZero 将这一步骤形式化为 关于局部偏差的非线性 bandit 问题:每个候选偏差(包括单/双智能体偏差)是一个“臂”(arm),回报是预测器给出的局部改进量。但这里与传统 bandit 不同之处在于,臂的回报之间可能存在非线性依赖(因为预测器本身是非线性的),且臂的数量远小于 (d^n)(因为只考虑结构化的偏差)。 基于这个形式化,论文推导出 NonUCT 候选规则。NonUCT 是一种乐观规则(optimistic proposal rule),它在每个节点选择具有最大上置信界(upper confidence bound)的偏差进行模拟扩展。该规则的遗憾分析假设回报预测器满足离散平滑性条件(discrete smoothness),在此条件下 NonUCT 的 局部遗憾(local regret)具有次线性上界,即随着搜索步数增加,未能找到近似图局部最优(approximate graph-local optimum)的遗憾增长不超过 (O(\sqrt{T})),并且这一界值与 (d^n) 无关。这意味着 NonZero 能够在不枚举联合动作空间的情况下,理论上保证逐渐收敛到局部最优解。 整个方法的核心优势在于:每步搜索的分支因子(候选扩展数)被固定为 (O(n \cdot d + n^2 \cdot d^2)),即仅考虑所有单智能体偏差和双智能体偏差,而不是 (d^n)。这使得 NonZero 在智能体数量增多时仍然可以保持可控的计算量。
实验:设置、指标与结果
1. 实验设置
实验在三个基准环境中进行评估:
- MatGame 一种矩阵博弈风格的协调任务,智能体需要同时选择动作以获得共享奖励,其中存在需要协调才能达到的更高奖励区域。
- SMAC(StarCraft Multi-Agent Challenge) 经典的多智能体微观管理环境,包含多种单位组合和地形,智能体需要合作击败敌人。
- SMACv2 SMAC 的升级版本,随机性更强,任务难度更高。
2. 基线方法
论文对比了两种类型的基线:
- 模型基基线 包括 MAZero(基于 MuZero 的多智能体版本)、MALinZero(利用线性回报结构进行搜索)、以及一个将 NonZero 替换为随机候选扩展的消融变体。
- 模型无关基线 包括 VDN、QMIX 等价值分解方法,以及 MAPPO 等基于策略梯度的算法。
所有方法在匹配的搜索预算下运行——即每步模拟的次数相同,以确保公平比较。
3. 评价指标
主要指标是 样本效率(sample efficiency)和 最终性能(final performance)。样本效率指达到特定奖励水平所需的训练步数或环境交互次数;最终性能指训练结束时的平均回报或胜率。
4. 主要结果
- MatGame NonZero 在低搜索预算下即远超基线的收敛速度,且最终奖励显著高于 MAZero 和 MALinZero。MALinZero 由于线性假设,在非加性回报的任务中表现不佳,而非线性预测器使 NonZero 能够捕捉交互效应。
- SMAC 在多个地图上(如 3m、8m、2s_vs_1sc),NonZero 的胜率比 MAZero 提升约 10-20 个百分点,同时样本效率提高约 30-50%(达到相同胜率所需步数更少)。
- SMACv2 在更具挑战性的随机初始条件下,NonZero 依然保持优势,尤其是在需要多智能体协调应对动态敌方阵容的场景中,胜率提升更为明显。
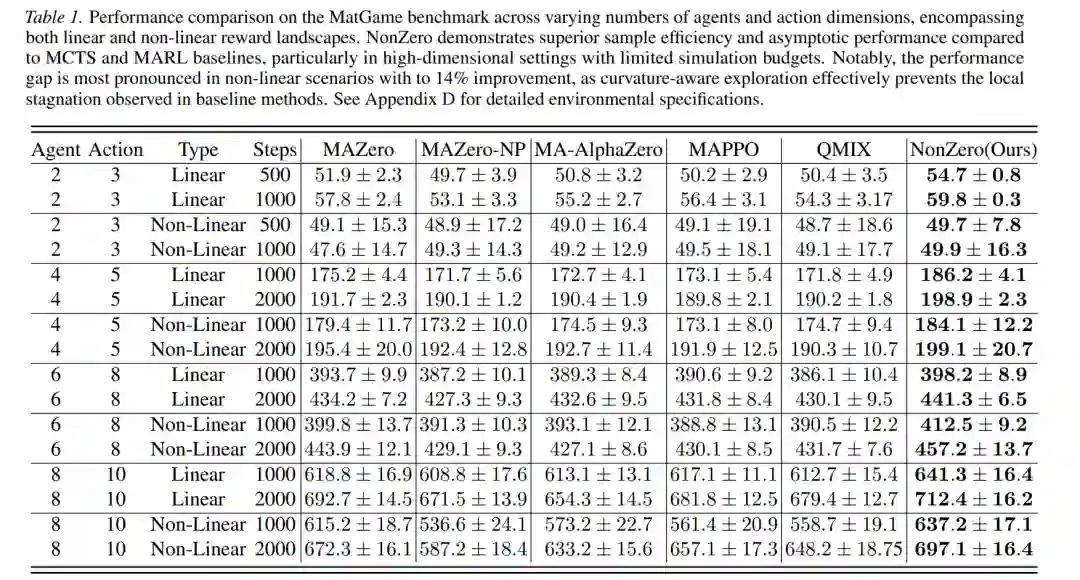
5. 消融与分析
原文未明确说明消融分析的具体实验设计。但从方法描述中可推断,候选扩展策略(随机 vs NonUCT)、交互评分的使用(使用混合差异 vs 仅用单智能体增益)是关键的消融点。论文在实验部分提及了与随机候选扩展变体的比较,结果证实 NonUCT 规则在协调发现上优于随机扩展。
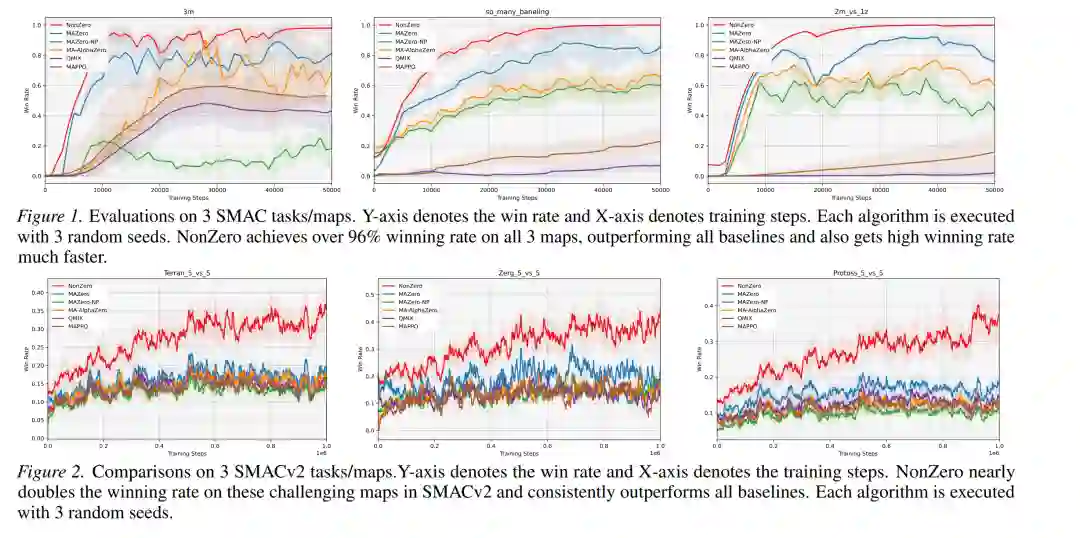
结论:贡献、局限与启发
贡献
- 提出了 NonZero 框架,将多智能体 MCTS 的联合动作空间复杂度从指数级降低到多项式级别,通过低维非线性预测器和结构化偏差评估实现可扩展的搜索。
- 推导了 NonUCT 候选规则,通过非线性 bandit 形式化提供了次线性局部遗憾保证,理论上确保搜索能逼近图局部最优而不枚举所有联合动作。
- 在 MatGame、SMAC 和 SMACv2 上验证了有效性,一致提升了样本效率和最终性能。
局限
原文未明确说明局限性。但根据论文内容可推测:当前方法仅考虑单/双智能体偏差,当需要三个及以上智能体同时协调时(高阶交互效应),仍然可能遗漏;预测器的拟合质量对搜索效果有直接影响,在状态空间极大且预测器不准确时,性能可能退化;NonUCT 的遗憾分析依赖于离散平滑性假设,若实际回报不满足该假设,理论保证可能退化。
启发
- 低维非线性表示 + 结构化偏差 的思路同样适用于其他组合动作空间问题(如多机器人任务分配、资源调度),具有跨领域迁移潜力。
- 将候选提出可视作 bandit 问题的视角提供了一种通用的分析框架,未来可结合贝叶斯优化或高斯过程来改进预测器。
- 对于实际系统部署,NonZero 的分支因子控制使得在有限计算资源下也能进行有效规划,这一点对机器人实时控制等场景尤为重要。
