

强化学习(Reinforcement Learning, RL)催化了大推理模型(Large Reasoning Models, LRMs)的兴起,将机器的推理能力提升至全新高度。在这些模型的性能引发广泛关注的同时,探究驱动这些行为的内部机理已成为同样关键的研究前沿。 本文对 LRMs 的机理理解进行了全面综述,将近年来的研究成果归纳为三个核心维度: 1. 训练动力学(Training Dynamics)
推理机制(Reasoning Mechanisms)
非预期行为(Unintended Behaviors)
通过综合这些见解,我们旨在弥合“黑盒性能”与“机理透明度”之间的鸿沟。最后,我们讨论了尚未得到充分探索的挑战,并勾勒出未来机理研究的路线图,包括对应用可解释性、改进方法论以及统一理论框架的需求。
**1 引言 (Introduction)
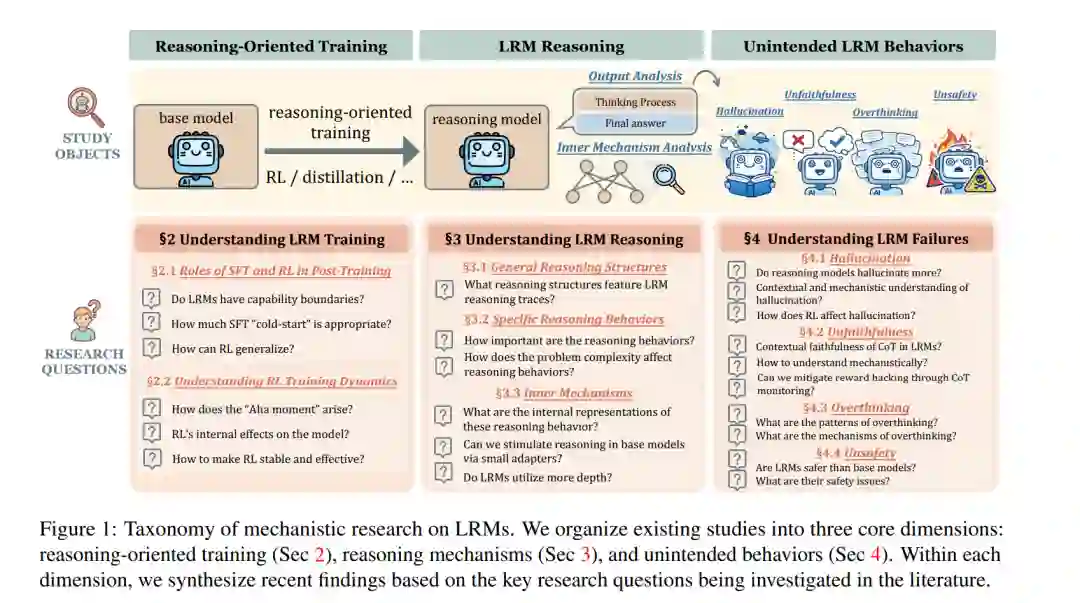
过去几年见证了大语言模型(LLMs)推理能力的显著进步。近期,强化学习(Reinforcement Learning, RL)已成为一种激励复杂推理的变革性范式,促使了先进大推理模型(Large Reasoning Models, LRMs)的崛起(DeepSeek-AI et al., 2025; Jaech et al., 2024)。这些模型在数学、编程和逻辑等广泛领域展现出了卓越的性能。值得注意的研究(DeepSeek-AI et al., 2025)表明,基于可验证奖励的强化学习(RL from Verifiable Rewards, RLVR)(DeepSeek-AI et al., 2025; Lambert et al., 2024)训练能够诱导出引人注目的涌现式推理行为,例如长思维链(Extended Reasoning Chains)和自省(Self-reflection)。 尽管取得了这些令人印象深刻的进展,LRMs 在很大程度上仍被视为“黑盒”。许多基础性问题尚无定论,包括:RL 的作用与监督微调(SFT)有何不同?定义 LRM 推理的结构特征是什么?驱动其独特行为的内部机制又是怎样的?此外,非预期行为(如幻觉、不忠实性及过度思考)的根源何在?这种透明度的缺失激发了学术界对机理研究(Mechanistic Research)日益浓厚的兴趣,旨在揭示促使这些模型执行复杂推理的底层过程。 本文对 LRMs 机理研究这一新兴领域进行了全面综述。从研究对象的视角出发(如图 1 所示),我们将相关工作按照面向推理的训练过程、LRM 推理行为以及 LRM 非预期行为进行组织: 1. 面向推理的训练过程 (§2): 本节探讨专门针对推理能力的训练过程背后的机制。我们首先剖析了 SFT 与 RL 的互补作用 (§2.1),并考察了 RL 中的关键训练动力学,例如“顿悟时刻(Aha Moments)”如何涌现,以及训练过程中内部表示(Internal Representations)如何演化 (§2.2)。 1. LRM 推理 (§3): 我们深入探讨了 LRM 推理底层的机制,分析了其输出结果及内部表示。本节探讨了 LRM 推理轨迹(Reasoning Traces)的一般结构特征 (§3.1)、自省等关键行为 (§3.2),以及支撑这些行为的内在机制 (§3.3)。 1. LRM 非预期行为 (§4): 我们进一步审视了 LRMs 的副作用,探索了与典型非预期行为相关的行为模式和内部机制,包括幻觉 (§4.1)、不忠实的思维链(CoT) (§4.2)、过度思考 (§4.3) 以及安全性问题 (§4.4)。
贡献与独特性。 本综述的独特之处在于专门聚焦于对 LRMs 的机理理解,这一主题在现有文献中受到的关注相对有限。虽然已有一些综述对大推理模型和 RL 技术进行了概括性回顾(Zhang et al., 2025c; Li et al., 2025f; Zhang et al., 2025h; Xu et al., 2025),但并未深入探讨驱动 LRM 推理的底层机制。特别地,Chen et al. (2025b) 探讨了长 CoT 推理,但主要关注 CoT 输出的行为特征,极少涉及内部机制。此外,虽有综述研究缓解过度思考的方法(Feng et al., 2025; Sui et al., 2025),但其重点在于高效推理技术,而非过度思考背后的机理。据我们所知,本文是首篇全面综述 LRM 机理的工作,对训练过程、推理行为及非预期结果提供了更为详尽且深度的分析。