
强化学习(RL)已成为提升大语言模型(LLM)推理能力的核心后训练工具。在RL后训练系统中,rollout——即从提示(prompt)到终止的采样轨迹,包括中间推理步骤以及可选的工具或环境交互——决定了优化器学习所用的数据。然而,rollout设计常被视为实现细节而被低估。本综述为基于RL的推理LLM后训练提供了优化器无关的rollout策略视角。我们形式化统一符号的rollout管线,并引入**GFCR(生成-过滤-控制-重放)**生命周期分类法,将rollout管线分解为四个模块化阶段:Generate(生成)提出候选轨迹;Filter(过滤)通过验证器、评委或评论家构建中间信号;Control(控制)在预算下分配计算资源并做出继续/分支/停止决策;Replay(重放)在不更新权重的情况下跨rollout保留和复用工件。我们还补充了可靠性、覆盖率与信息性、成本敏感性三条准则,用于描述rollout设计必须权衡的要素。通过数学、代码/SQL、多模态推理、工具使用代理和代理技能基准等案例研究,我们验证了该框架的有效性。
1 Introduction / 引言
随着强化学习在LLM后训练中地位的提升,rollout策略的重要性日益凸显。一个rollout是从提示到终止的采样轨迹,在纯文本设定中表现为包含中间推理和最终答案的完整输出;在工具或环境交互设定中,则包含动作-观察循环和外部反馈。rollout设计常常主导训练成本和学习信号质量,但现有文献多集中于优化算法和奖励建模,rollout策略的细节往往被低估或隐藏。 论文中的四幅配图如下:
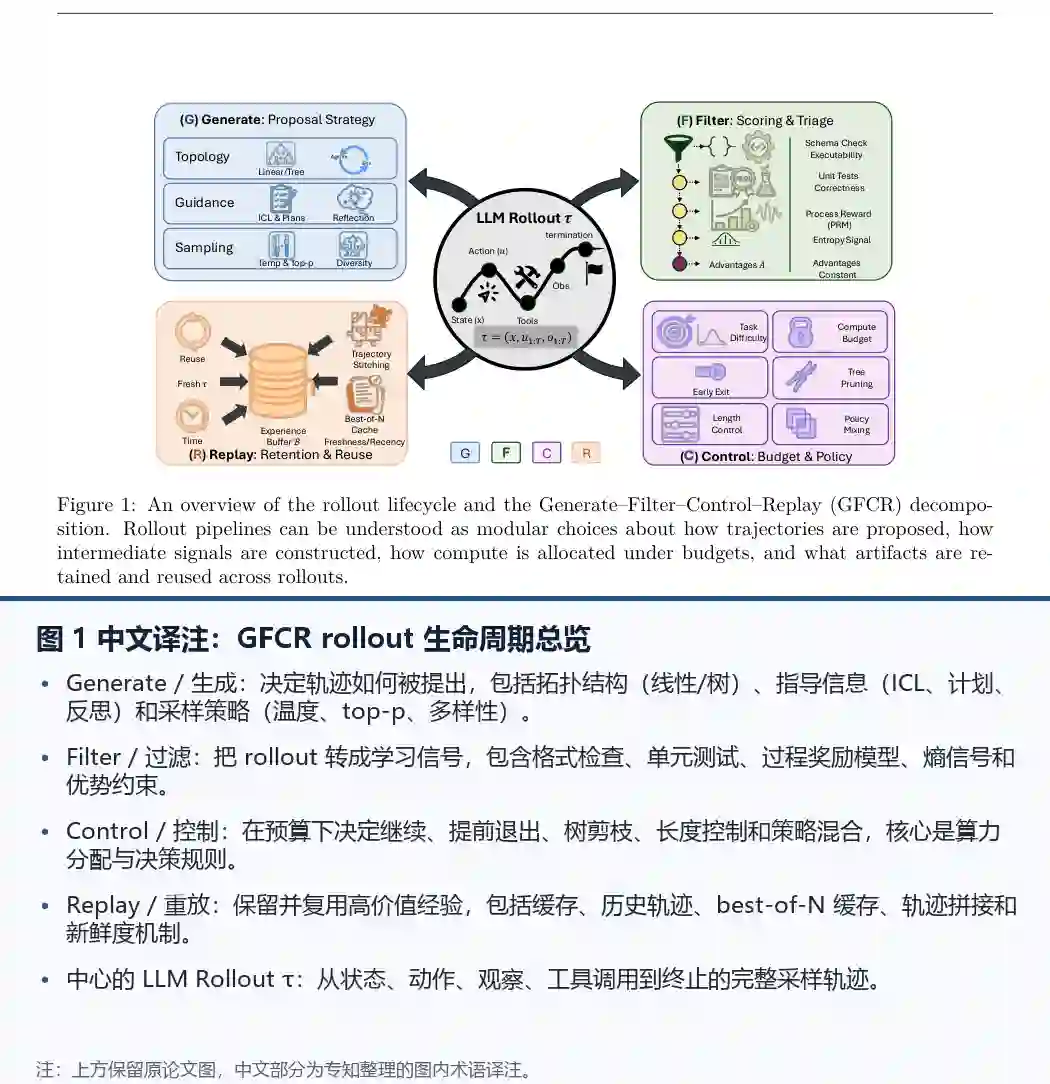
- Figure 1 提供了rollout生命周期和GFCR分解的整体概览。它展示了rollout管线可被理解为关于轨迹如何提出、中间信号如何构建、计算如何分配以及跨rollout哪些工件被保留和复用的模块化选择。
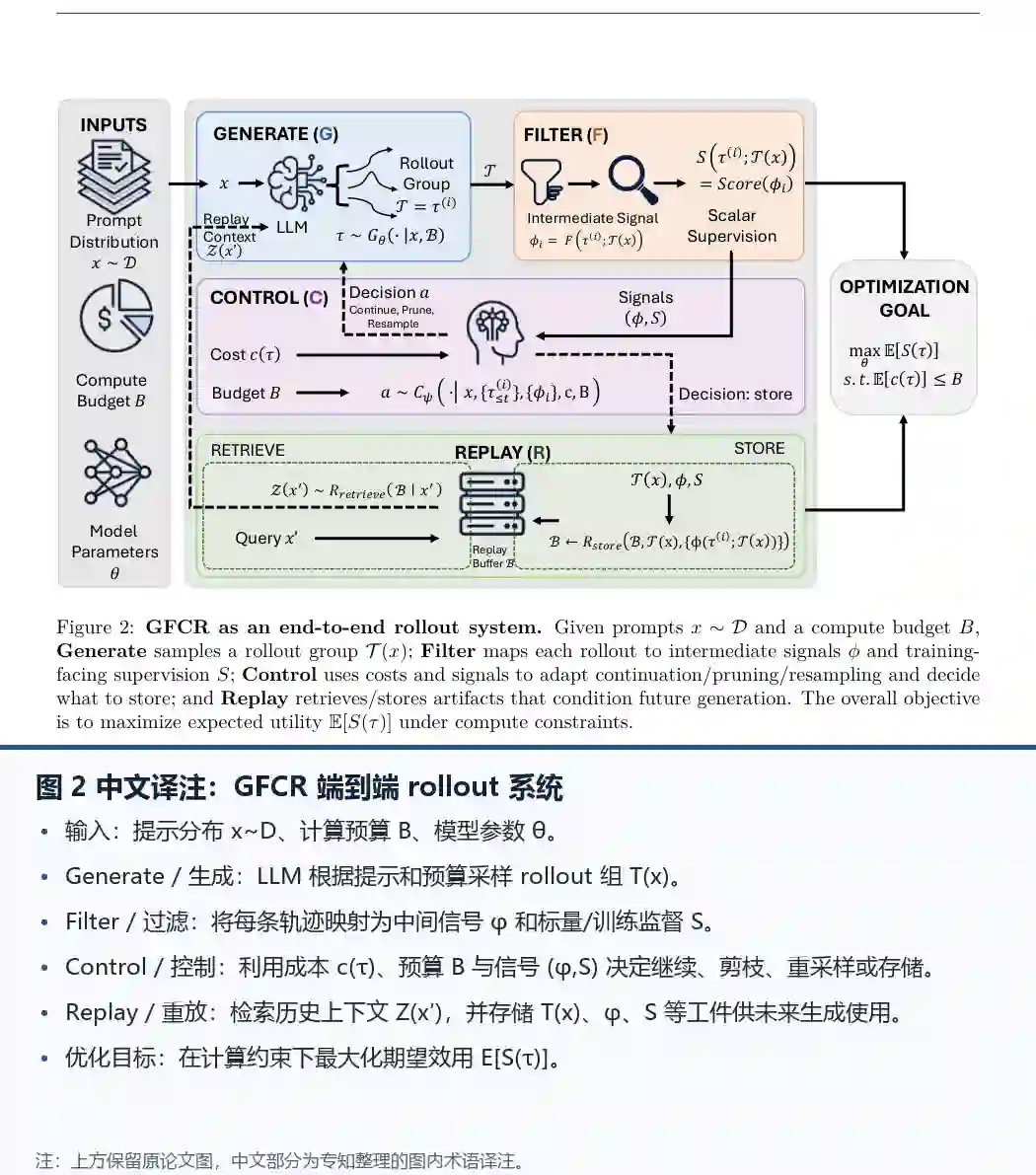
- Figure 2 展示了GFCR作为端到端rollout系统的完整流程。给定提示和计算预算,Generate采样一个rollout组;Filter为每个rollout构建中间信号和训练监督;Control根据成本和信号决策继续/剪枝/重采样并决定存储什么;Replay检索/存储工件以调节未来生成。目标是在计算约束下最大化期望效用。
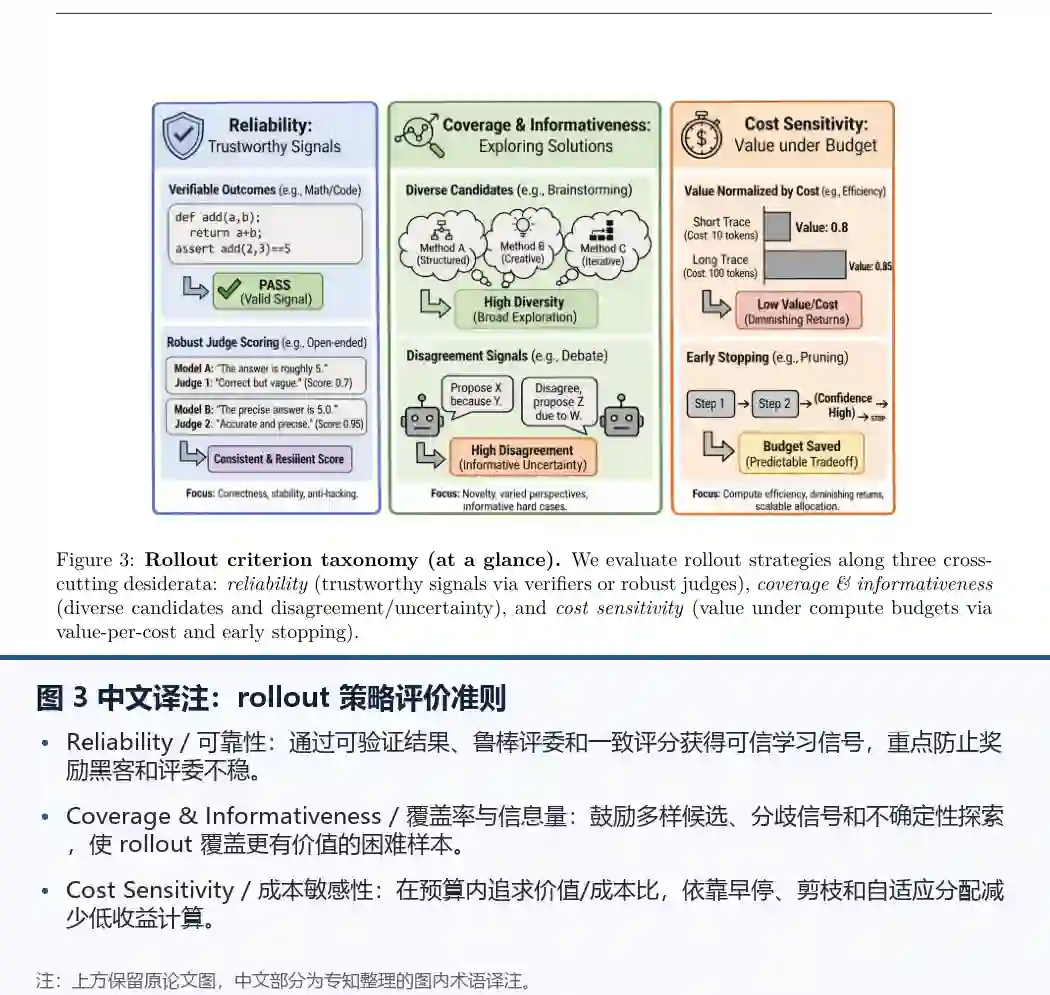
- Figure 3 展示了rollout准则分类法,分为三个交叉维度:可靠性(通过验证器或稳健评委实现可信信号)、覆盖率与信息性(多样候选和不一致性/不确定性)、成本敏感性(通过价值-成本比和提前停止实现预算下的价值)。
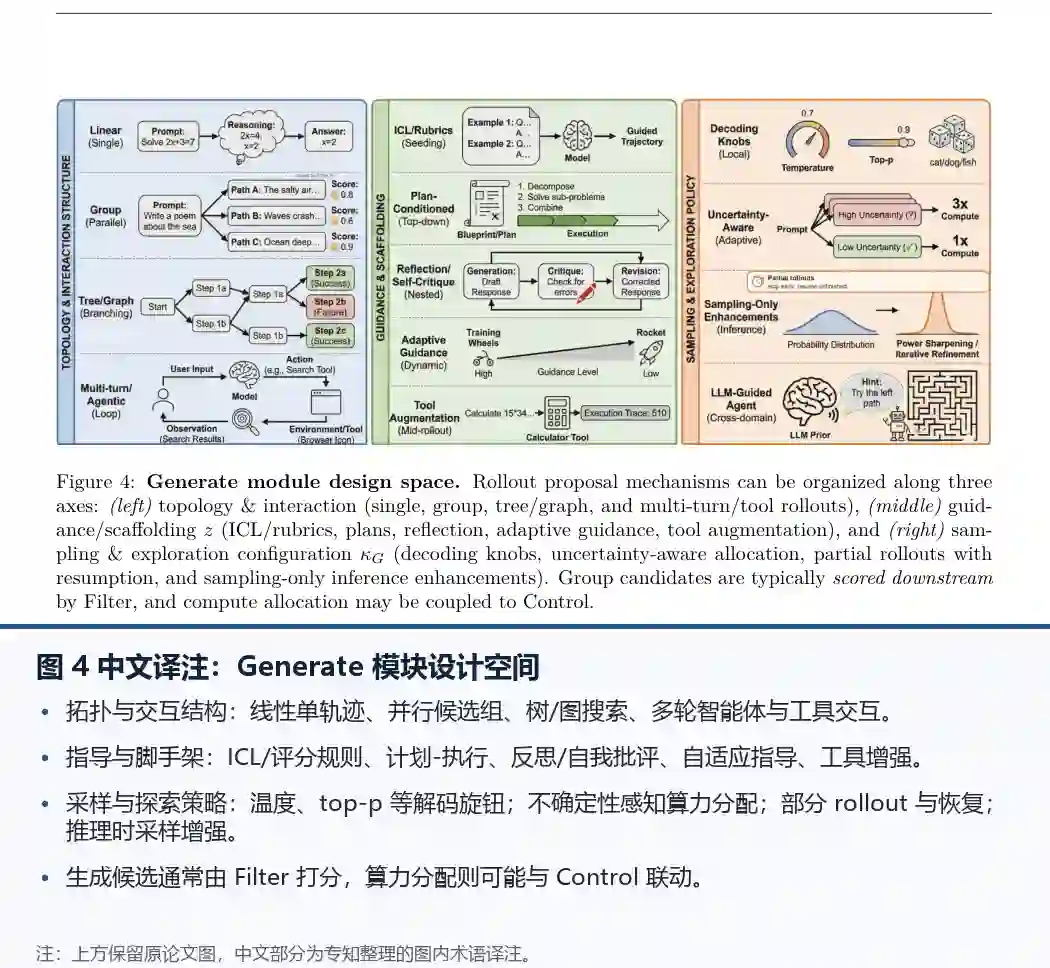
- Figure 4 展示了Generate模块的设计空间。rollout提议机制可沿三个轴组织:拓扑与交互(单线、组、树/图、多轮/工具rollout)、指导与脚手架(示例/规则、计划、反思、自适应指导、工具增强)、采样与探索配置(解码参数、不确定性感知分配、部分rollout与恢复、仅采样推理增强)。
本综述的贡献包括:首次系统组织rollout策略;提出GFCR和准则分类法;综合各类rollout方法;通过多领域案例进行验证;提供诊断索引和开放挑战。
2 Related Work / 相关工作
我们将本综述与现有调查进行对比。现有调查主要围绕反馈建模、奖励学习和优化目标组织,隐含地处理rollout策略。例如,RLHF和偏好学习调查强调反馈收集与建模;RL增强LLM调查总结RLHF、RLAIF和直接偏好系列;技术调查聚焦RL算法和训练机制;管线级调查分类RL出现在数据生成、预训练、后训练和测试时推理的哪些位置;推理和代理中心综述则聚焦多步推理、搜索和环境交互。相比之下,本综述将rollout策略作为分析单位,提供模块化词汇表比较不同系统如何组合拓扑、采样、评分粒度、预算分配和经验复用。
3 Foundations: Rollouts, Criteria, and the GFCR Framework / 基础:Rollout、准则与GFCR框架
本节建立基础。首先介绍GFCR的功能分解:Generate、Filter、Control、Replay四个模块。然后定义全局符号:rollout τ = (x, u_1:T, o_1:T),其中x是提示,u_t是模型动作,o_t是环境观察。训练系统通常采样单个rollout或一组K个rollout。Filter信号记为ϕ,训练信号S由Score(ϕ)得到。计算成本c(τ)和预算B约束整体优化。 GFCR模块常交错:Filter信号触发Control决策(如剪枝、提前停止),Replay工件种子化未来的Generate,Control策略决定哪些工件进入Replay。 准则分类法描述三个诉求:可靠性(可验证结果、稳健评委评分)、覆盖率与信息性(多样候选、分歧信号)、成本敏感性(价值归一化、提前停止)。GFCR是功能分解,准则是对选择理由和评价方式的描述。
4 Generate: How Trajectories Are Proposed / 生成:如何提出轨迹
Generate模块规定候选rollout的提议方式。输出是候选集T(x) = {τ^(i)},受拓扑Topo、指导z和采样配置κ_G影响。拓扑分为线性、组、树/图和交互式四类。线性rollout采样单轨迹;组rollout采样K个并行候选,支持组内比较和方差缩减(如GRPO);树/图rollout在中间前缀分支,利用共享前缀分摊计算并通过剪枝分配预算;多轮/工具rollout在动作-观察循环中运行。 指导与脚手架包括ICL种子、计划条件、反思子rollout、自适应指导强度和工具增强。采样策略包括解码参数(温度、top-p)、不确定性感知采样(根据奖励方差或语义熵分配计算)和仅采样推理增强。 代表性方法包括GRPO、DAPO、TreeRPO、TreeRL、RAGEN等。
5 Filter: From Rollouts to Learning Signals / 过滤:从Rollout到学习信号
Filter模块将候选rollout映射为中间信号和面向优化器的监督。形式化为:ϕ_i = F(τ^(i); T(x)),包含结构有效性门控(解析/编译/可执行性)、正确性验证(单元测试、精确匹配)、过程质量评分(步级PRM)、比较评估(成对/列表性评判)、学习价值信号(不确定性、熵)和训练信号构建(权重、优势、标签)。 结构有效性门控过滤掉格式不匹配的rollout,减少假阴性。正确性验证用于代码(单元测试)和数学(精确匹配)。过程评分提供步级部分信用。比较评估通过评委实现相对偏好。学习价值信号用于加权或引导采样。 代表性方法包括xVerify、RLTF、CodeRL、Lightman等人的PRM、GRPO的组内归一化等。
6 Control: Compute Allocation, Decision Rules, and On/Off-Policy Knobs / 控制:计算分配、决策规则与同/离策略控制
Control 模块回答的是:在有限预算下,哪些样本值得继续 roll out,哪些前缀应该提前停止,哪些分支应该扩展或剪掉,以及训练时应该混合多少新鲜 on-policy 数据和历史 off-policy 数据。它把 Filter 产生的中间信号、每条轨迹的计算成本以及全局预算约束转化为一系列决策,从而直接塑造实际被优化器看到的 rollout 组分布。换句话说,Generate 决定“能生成什么”,Filter 决定“哪些信号可用”,而 Control 决定“把算力花在哪里”。 从形式上看,Control 可以被理解为预算约束下的序贯决策过程。对一个 prompt x,系统维护一组正在展开的部分轨迹前缀,并在每一步根据成本 c(τ)、预算 B、Filter 信号 ϕ 和训练监督 S 决定继续、剪枝、重采样或存储。论文将其目标写成在每个 prompt 或全局预算约束下最大化学习效用 U(T),这里的效用可以是可用样本量、信号强度、正确性提升或其他训练价值代理。
6.1 Prompt and Task Selection / 提示与任务选择
第一类控制发生在 rollout 之前:选择哪些 prompt 值得生成。传统做法通常从训练分布中均匀采样,但许多 prompt 贡献的学习信号很低。例如,当一个 rollout 组里的所有样本奖励完全相同,GRPO 类方法的组内优势会坍缩为零,几乎没有梯度。GRESO 试图预测这种零方差 prompt 并在保留探索的同时跳过它们;VCRL 则把组内奖励方差视为样本难度代理,认为太容易或太难的 prompt 往往方差低,中等难度 prompt 更能产生有用学习信号。 另一条线使用不确定性建模做任务选择。VADE 用 Beta 后验估计每个 prompt 的正确率,并通过 Thompson sampling 偏向信息量高的 prompt;SEED-GRPO 不直接选择 prompt,而是根据多个答案的语义熵调节策略更新幅度,对高不确定样本采取更保守更新;SEC 则把课程选择建模为非平稳多臂老虎机,在类别层面学习哪些难度或任务类型能带来更高学习收益。它们共同体现出一个趋势:rollout 分配不再是固定采样过程,而是自适应资源管理问题。
6.2 Budgeting and Scheduling / 预算与调度
第二类控制决定每个 prompt 分配多少 rollout 宽度、深度和 token 预算。早期 GRPO 风格训练常采用固定 K 个候选,但固定宽度会在简单题上浪费计算,也可能在困难题上探索不足。论文总结了方差感知、困难度感知和不确定性感知的调度方法:对低信息样本少采样,对争议样本或高不确定样本增加候选数、搜索深度或 token 预算。 这种调度也影响系统吞吐。长 reasoning rollout 具有明显长尾,少数超长样本会拖慢同步训练。控制层因此需要把 rollout 数量、最大长度、候选组大小、树搜索宽度以及 batch 负载均衡放在同一个预算框架下考虑。其核心权衡是:固定预算带来稳定实现,自适应预算提升计算效率,但也可能引入选择偏差和复现难度。
6.3 Rollout Configuration Control / rollout 配置控制
第三类控制针对单条轨迹的形态,包括最大长度、是否“深思考”、温度、top-p、简洁性奖励、正负样本比例等。ShorterBetter 用最短正确答案定义 Sample Optimal Length(SOL),希望学到实例自适应的最优 CoT 长度;DECS 指出轨迹级奖励和 token 级优化之间存在错配,因此引入解耦 token 级奖励和课程 batch 调度,减少冗余 token 而不压制必要探索。 是否需要长推理本身也可以被控制。AdaptThink 观察到简单问题上直接回答模式可能优于长推理,因此训练模型根据题目难度选择 thinking 或 no-thinking 模式;Large Hybrid-Reasoning Models 用冷启动微调加在线 RL 学习混合思考决策;CoRL 则关注调用外部 LLM 推理时的性能-成本权衡。GFPO 和 Train Long, Think Short 进一步说明:训练阶段多花一点采样和筛选成本,可能换来测试阶段更短、更高效的推理。
6.4 Early Exit、Branching、On/Off-Policy 与系统吞吐
Control 还覆盖部分 rollout 的提前退出、树搜索剪枝以及多智能体分支控制。若某个前缀已经被局部检查器判定成功或高置信失败,系统可以停止继续生成;若树上某些分支前景较差,可以剪枝,把预算转移给更有希望的分支。TreeRPO 等方法利用树采样估计不同推理步骤的期望奖励,构造更密集的步骤级训练信号。 最后,Control 也决定 on-policy 和 off-policy 数据如何混合。on-policy rollout 与当前策略一致,但昂贵;历史 replay 能提高样本效率,却带来策略漂移风险。RePO 在 GRPO 中加入 replay buffer,ReMix 让 PPO/GRPO 等 on-policy RFT 方法利用 off-policy 数据;AR3PO 则通过在当前策略下重新计算旧响应 token 概率来缓解重要性比率失控。系统层面,ReSpec、DAS、TLT、EARL、Seer 等方法把 speculative decoding、长尾负载均衡、动态并行和相似样本复用纳入控制问题,以提升 rollout 吞吐。
7 Replay: Retention, Reuse, and Self-Evolution / 重放:保留、复用与自我演化
Replay 模块关注 rollout 结束后“什么值得留下、如何复用、何时丢弃”。它不是简单的数据缓存,而是把过去生成的轨迹、验证信号、子步骤、失败样本、正确锚点和工具交互记录组织成可检索工件,使未来 Generate、Filter 和 Control 都能受益。论文用存储规则 Rstore 和检索规则 Rretrieve 来形式化 Replay:前者决定哪些轨迹或信号进入缓冲区,后者根据相似度、正确性、多样性、成本和新鲜度为新 prompt 检索相关工件。
7.1 Response Resampling and Retention / 响应重采样与保留
最直接的 replay 是把完整响应作为可复用单元。其作用有两类:一是复用过去高价值样本,提升数据效率;二是在组归一化目标中稳定优势信号。例如,当当前 prompt 的所有 rollout 都错误时,GRPO 的奖励方差为零,梯度会消失。DAPO 通过动态采样继续寻找既非全错也非全对的 batch,但会增加推理成本;AR3PO 则保留早期正确响应,当当前组全错时注入缓存正确样本,让错误 rollout 获得负优势而不是零梯度。 Replay buffer 也支持 off-policy 复用。RePO、ReMix、ExGRPO 等方法利用历史响应改进样本效率,同时需要处理策略漂移和重要性权重问题。如果旧策略 πθ− 与当前策略 πθ 差异太大,复用样本可能带来偏差;因此需要重算概率、约束 KL、按正确性/熵/学习进展排序,或者设置刷新和淘汰机制。
7.2 Recomposition and Segment Reuse / 轨迹重组与片段复用
第二种 replay 粒度不是整条轨迹,而是可验证片段。长推理、代码修复、工具调用和代理任务往往包含多个子问题或子轨迹,其中某些前缀、补丁、测试、工具结果是可复用的。把这些片段切分、验证、存储,再在新任务中重组,可以摊销共享计算,也能把学习信号从“终局正确/错误”细化到局部步骤。 这种思想尤其适合代码、SQL、数学证明和多步代理。代码任务里,已验证补丁、单元测试、错误日志和修复片段可以被缓存;数学任务里,正确中间引理或短正确片段可作为未来解题 scaffold;工具代理里,成功的网页导航子流程或 API 调用序列可转成可检索技能。相比整条 replay,片段 replay 更灵活,但也更依赖边界切分、片段正确性验证和上下文兼容性判断。
7.3 Self-Evolving Curricula and Intrinsic Feedback / 自我演化课程与内在反馈
第三种 replay 更进一步:rollout 不只是训练数据,而会主动扩展训练分布。STaR、Self-Rewarding、Self-Play RL、AGILE/Auto-RL、Agent0、LANCE 等方法都体现了这种自我演化思路。模型可以生成新任务、反思已有缺陷、构造更难样本、给数据打偏好标签,甚至让一个课程智能体和一个执行智能体相互促进:课程智能体提出更难、更需要工具的问题,执行智能体通过 RL 学会解决这些问题。 这类方法的潜力在于减少人工标注依赖、持续扩展能力边界;风险则在于偏差累积、质量漂移和不可追踪。若自生成任务越来越偏离真实需求,或奖励模型与策略共同漂移,Replay 会把错误偏好固化进训练。论文因此强调 replay 需要记录来源、策略版本、验证器结果、时间戳和刷新状态,确保复用样本既有价值也可审计。
8 Domains and Case Studies / 领域与案例研究
论文把基准看作 rollout 接口:任务实例 x 来自分布 D,模型在接口中产生轨迹 τ=(x,u1:T,o1:T),其中 u 是模型动作,o 是环境观察。不同领域的核心差异不只是任务内容,而是接口返回什么反馈、验证器是否可靠、轨迹是否多轮、能否复用片段,以及预算应如何在深度、宽度和重放之间分配。
8.1 Verifiable Language Interfaces / 可验证语言接口
数学、代码和 SQL 是最典型的可验证语言接口。数学任务通常是纯文本 rollout,终局答案经过归一化后用精确匹配或规则验证;DeepSeekMath、DeepSeek-R1、SEED-GRPO 等系统展示了 RLVR 风格目标如何与数学数据和采样策略结合。TreeRL、TreeRPO、VCRL 等方法进一步说明,树/组 rollout、方差感知课程和不确定性采样会显著影响训练稳定性与成本。 代码和 SQL 则是执行接地接口。模型输出程序、补丁或查询,验证器由编译、运行、单元测试或数据库执行提供。CodeRL、RLTF、LiveCodeBench、BIRD、Arctic-Text2SQL-R1 等案例表明,执行反馈天然形成“生成-执行-观察失败-修复”的多阶段 rollout。这里 Filter 很具体:能否编译、能否通过测试、执行结果是否等价;Replay 也很自然:可缓存通过测试的补丁、错误日志、部分查询和已验证片段。
8.2 Multimodal Reasoning Interfaces / 多模态推理接口
多模态任务把输入扩展为图像、视频、空间场景或音视频片段。与数学/代码不同,多模态推理往往缺少通用强验证器,因此系统需要把任务设计成可规则验证,或者借助结构化答案抽取、标签检查、合成数据和专门评测协议来获得相对稳定的奖励。R1-VL、MMR1、SpaceR、SPACEVISTA、InternSpatial、SPAR、VSI-Bench 等工作体现了这种方向。 对 GFCR 来说,多模态接口让 Generate 更复杂:rollout 可能包含视觉观察、文本推理和空间关系判断;Filter 需要把自由文本答案转成可检查结构;Control 要决定是否需要更多视觉证据、更多采样或更长 reasoning;Replay 则可以复用已验证视觉-语言推理模板、空间关系片段或合成样本生成策略。
8.3 Agentic Interactive Benchmarks / 代理交互基准
代理交互任务与纯文本任务的关键差异是 o1:T 不为空:模型每一步动作都会改变环境并收到观察。软件工程基准(如 SWE-Bench、SWE-agent、SWE-Gym、Agent-RLVR)要求模型在代码库中定位问题、编辑文件、运行测试并根据反馈迭代。Web 代理基准(BrowserGym、AgentDojo、ARLAS)要求模型点击、输入、浏览并处理网页状态,也可能面对间接提示注入等安全风险。对话模拟器(RLVER、SAGE)则把用户状态和情绪轨迹作为可验证奖励来源。 这些基准中的 rollout 通常长、稀疏奖励明显、环境反馈昂贵。因此 Control 的作用被放大:何时停止、何时回退、何时开新分支、是否继续调用工具,都决定成本与成功率。Replay 也从“记住答案”变成“记住过程”:成功的工具调用序列、网页导航流程、代码编辑策略和失败诊断都可能成为未来任务的可复用经验。
8.4 Agentic Skills Benchmarks / 代理技能基准
代理技能基准进一步考察模型能否从轨迹中归纳可复用技能,并迁移到新任务。WebArena、Mind2Web、BrowserGym 等环境中,Agent Workflow Memory 将子流程抽象为可检索自然语言工作流;Agent Skill Induction 把技能表示为可重新执行的 Python 函数;SkillWeaver 让代理自动发现并打磨可复用 API;ReUseIt 等工作关注技能在不同任务和模型间的复用。 在这一类接口中,GFCR 的四个模块更像一个长期学习循环:Generate 产生候选行动和技能调用,Filter 验证技能是否成功,Control 决定是否存入技能库或继续探索,Replay 在新任务中检索旧技能。论文强调,这类场景把 rollout 策略从“单次后训练采样技巧”推向“持续自我改进系统设计”:关键不只是一次任务成功,而是能否形成可维护、可追踪、可迁移的经验库。
9 Failure Modes and Open Problems / 失败模式与开放挑战
常见rollout病理包括:零奖励模式(所有rollout失败)、奖励黑客、长度膨胀、信号噪声、计算浪费、回放过时等。GFCR框架提供了诊断索引,将每个病理映射到具体模块和缓解杠杆。开放挑战包括:验证器/评委校准、原则性计算核算、安全自我演化与溯源追踪、改进汇报标准以增强可重复性。
10 Conclusion / 结论
本综述通过GFCR框架系统组织了LLM强化学习后训练中的rollout策略。我们将rollout管线分解为生成、过滤、控制、重放四个模块,并辅以可靠性、覆盖率、成本敏感性准则。通过数学、代码、多模态、代理等领域案例,展示了该框架的统一描述能力。我们提供了诊断索引和开放挑战,期望推动更可重复、高效且可信的rollout管线设计。

