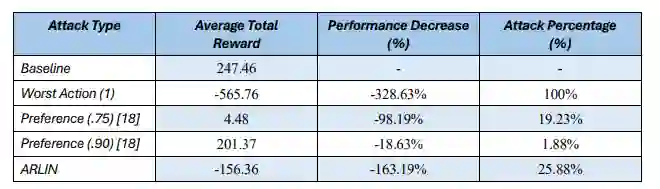
可解释强化学习技术有助于洞察深度强化学习模型的决策过程,并可用于在部署前识别策略中的脆弱性与缺陷,但这些技术同时也暴露了关键的策略信息及相关脆弱性,对手可利用这些信息针对训练后的策略发起更高效、更具破坏性的对抗性攻击。本文介绍ARLIN工具包,这是一个开源Python库,通过提供详细、人类可理解的解释性输出,识别训练后的深度强化学习模型中潜在的脆弱点和关键环节。为展示ARLIN的有效性,我们针对一个公开可用的深度强化学习模型提供了解释性可视化与脆弱性分析,并演示如何利用ARLIN生成的输出来成功降低模型的整体性能,同时限制攻击的整体可探测性。开源代码存储库可在 https://github.com/mitre/arlin 下载。
本文介绍了ARLIN工具包,这是一个用Python编写的开源研究库,为深度强化学习模型提供解释性输出和脆弱性检测功能,专门设计用于增强模型保证并识别训练后模型内潜在的失效点。据我们所知,ARLIN是首个专注于利用全局可解释性技术、在部署前对深度强化学习模型进行保证的开源Python工具包。为测试ARLIN的有效性,我们使用它来识别一个公开深度强化学习模型中的脆弱性,并演示对手如何利用该信息在训练环境中成功降低模型的整体性能,同时相较于当前最先进的对抗攻击时序方法,降低了攻击的可探测性。
本文为可解释与对抗性深度强化学习领域引入了三项主要贡献:
• ARLIN工具包:首个开源Python工具包,专注于利用全局可解释性技术,通过人类可理解的分析可视化,在部署前对深度强化学习模型进行保证。
• 一种利用解释性输出来识别攻击深度强化学习模型最佳时机的新技术,以确保策略失效和被操纵。
• 用于衡量针对深度强化学习模型的对抗攻击在人类与机器观察者面前可探测性的新度量标准。