
近年来,视觉-语言-动作(VLA)策略的快速发展推动了机器人操作、导航和自动驾驶的通用化,但这类“反应式”策略在复杂物理环境中往往缺乏对长期后果的推理能力,难以处理累积误差和时序信用分配问题。业界逐渐意识到:仅靠从观察到动作的直接映射是不够的,智能体需要一个能预测“世界如何随自身行为演变”的显式结构——这正是世界模型(World Model)的核心价值。然而,由于世界模型在架构、功能角色和具体应用领域上的分散发展,相关文献呈现出明显的碎片化,研究者难以快速把握整体脉络。 为此,由Bohan Hou、Gen Li、Jindou Jia等来自MIT、清华、伯克利、慕尼黑工大、ETH、牛津等机构的研究者联合撰写了这篇全面综述。论文从机器人学习的角度出发,将世界模型的技术路线清晰地划分为三大功能角色:与世界策略的耦合、作为模拟器支持强化学习和评估、以及机器人视频世界模型的生成能力演进。文章不仅系统梳理了数百篇文献,还专门将导航和自动驾驶纳入分析,并整理了代表性数据集和评估协议。 这篇综述的最大价值在于提供了一个统一的分类框架,帮助读者澄清了当前混乱的术语和范式。无论你是刚接触世界模型的新手,还是希望找到未来研究方向的从业者,这篇文章都能为你提供扎实的知识基座和清晰的研究路线图。
论文基本信息

摘要
世界模型是环境如何在动作下演化的预测表示,已成为机器人学习的核心组成部分。它们支持策略学习、规划、模拟、评估和数据生成,并随着基础模型和大规模视频生成的发展而快速进步。然而,现有文献在架构、功能角色和具身应用领域方面碎片化。本文从机器人学习视角全面回顾世界模型:探讨如何与策略耦合、如何作为强化学习和评估的模拟器,以及机器人视频世界模型从想象生成到可控、结构化、基础规模的进展。还联系导航和自动驾驶,总结代表性数据集、基准和评估协议。整体上,本综述系统回顾了快速增长的世界模型文献,理清了关键范式和应用,指出了主要挑战和未来方向。
引言:论文要解决什么问题
当前主流的视觉-语言-动作(VLA)策略在复杂物理环境中存在长期推理能力不足、时间信用分配困难以及累积误差下的鲁棒性差等问题。论文指出,这些局限并非仅仅来自动作预测能力的不足,更根本的原因是缺乏一个能显式预测“世界将如何随智能体行为演变”的结构。传统反应式策略直接映射从观察到动作,而世界模型则通过建模状态转移,赋予智能体三种核心能力:预见(foresight)——提前评估动作后果;想象驱动规划(imagination-driven planning)——在想象空间中对比候选行为;数据扩增(data amplification)——生成合成轨迹以丰富训练数据。这三项能力正是世界模型区别于一般感知预测器的关键。 论文梳理了世界模型的思想谱系:从1960年代认知科学中提出的内部模型概念(Miller等),到1970年代控制理论中的基于模型决策(Bryson & Ho),1980年代经典机器人规划(Lozano-Perez),再到现代机器学习中的模型强化学习(Nguyen & Widrow;Jiang等;Zhu等)以及大规模生成模型(Ali等;Guo等;Jiang等;Jang等)。本文的目标并非给出一个狭隘的形式定义,而是从机器人学习视角出发,聚焦于“如何让预测模型服务于策略学习、规划、模拟、评估和数据生成”,从而构建一个统一的理解框架。
配图:问题背景


方法:核心思路与技术路线
论文围绕世界模型在机器人学习中的三种功能角色组织全文,分别对应三个主要章节。下面逐一展开。
World Model for Policy / 世界模型用于策略
本节从架构角度探讨世界模型如何与机器人策略耦合。作者归纳了五种典型的组合方式:
- 逆动力学策略(Inverse Dynamics Policies with World Models):将世界模型作为前向预测器,先预测未来状态,再通过逆动力学模型从当前状态和预测状态反推出动作。这种结构显式解耦了“预测”和“控制”,但需要额外的逆模型训练。
- 单世界模型主干统一策略(Unified Policies with a Single World Model Backbone):将世界模型与策略共享一个骨干网络,通过多任务学习同时训练预测和动作生成。典型代表如UniPi、GR-1等,这类方法效率高但可能面临任务间干扰。
- MoE/MoT风格专家世界模型主干策略(MoE/MoT-Style Policies with Expert World-Model Backbones):借鉴混合专家(Mixture of Experts)或思维的多模态(Mixture of Thoughts)思想,让多个世界模型专家分别处理不同动力学模式,然后用策略网络聚合输出。这种方法擅长处理多模态环境,但增加了训练复杂度。
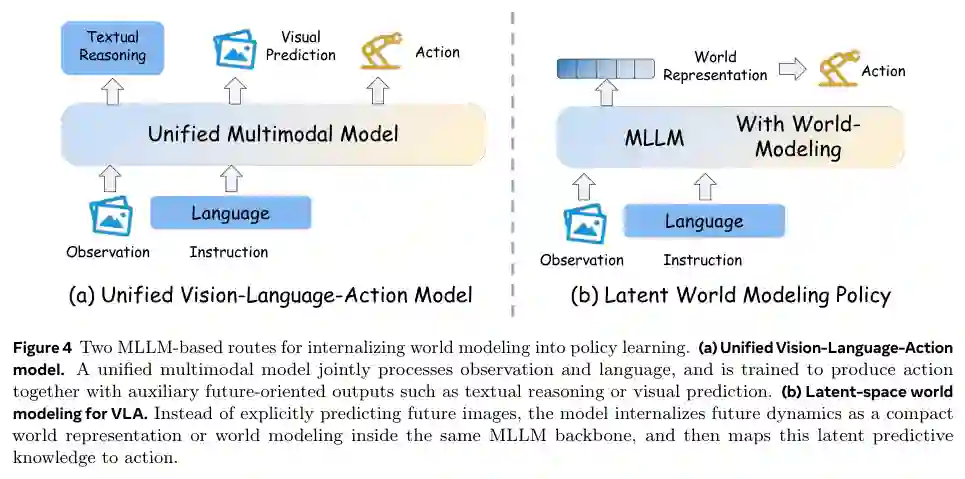
- 统一视觉-语言-动作模型(Unified Vision-Language-Action Models):在大型多模态模型(如LLaVA、Flamingo)基础上直接集成世界模型的预测头,使模型同时具备视觉理解、语言推理和动作预测能力。例如WorldVLA、UD-VLA等,是目前最主流的方向之一。
- 潜在空间世界建模策略(Policies with Latent-Space World Modeling):在策略的隐层表示中嵌入世界动态模型(如基于循环状态空间模型或随机前向预测),无需显式生成像素级预测。Dreamer系列和JEPA方法属于此类,计算效率高且泛化性好。
每种子类别下,论文都列举了代表性工作并分析了其利弊。虽然原文未给出定量比较,但通过分类清晰展示了设计空间中的主流选项。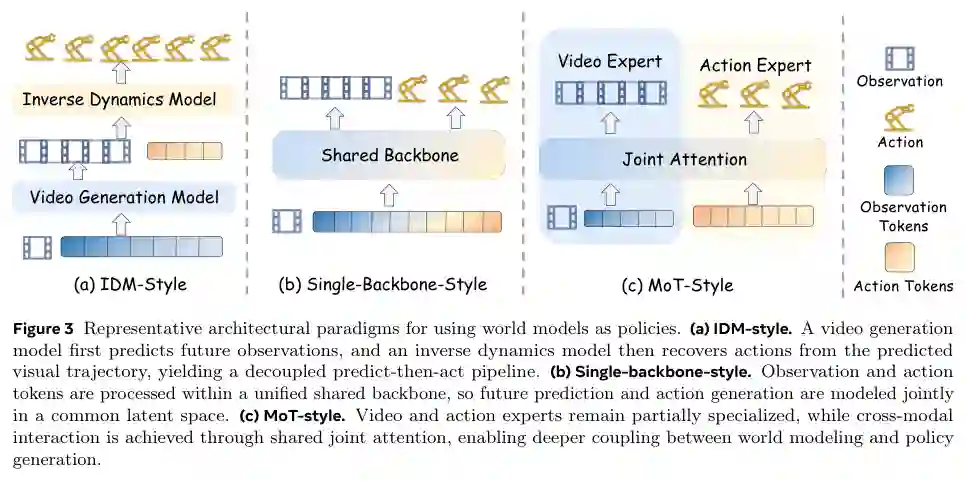
World Model as Simulator / 世界模型作为模拟器
本节从应用角度出发,关注世界模型如何充当可学习的模拟器,支持强化学习(RL)和评估。 用于强化学习:世界模型可以作为环境模型来替代真实物理环境,让智能体在其中进行想象滚动(imagination rollout),从而高效收集互动数据。这类方法(如Dreamer、Iso-Dream、EfficientZero)已在Atari和DMControl等基准上取得了显著效果。论文重点讨论了世界模型在RL中的两种角色:作为用于策略优化的世界模型(model-based RL),以及作为用于规划的无模型但基于预测的想象器(如MPC)。 用于评估:当真实环境难以获取或代价高昂时,世界模型可以提供一个低成本、可重复的评估平台。特别是对于机器人操作和自动驾驶,基于世界模型的模拟器可以快速生成多种场景,用于测试策略的鲁棒性和泛化能力。论文提到了SimGPC、World-Env等近期工作,它们尝试用世界模型取代传统物理仿真器。 该节还联系了导航和自动驾驶领域,介绍了在这些领域中世界模型作为模拟器的应用实例(例如在nuScenes、CARLA平台上的工作),但原文未给出统一实验。
Section 5: World Model for Robotic Video Generation / 世界模型用于机器人视频生成
本节按照世界建模能力从低到高的顺序,梳理了机器人视频世界模型的技术演进。
- 视频生成作为想象(Video Generation as Imagination for Policy Learning) 早期的视频世界模型主要用于为策略提供想象的前瞻画面,例如通过直接生成未来帧来辅助决策(如UniPi、VidMan等)。这时期的模型通常没有显式动作控制,只是被动预测未来。
- 动作可控的世界模型(Toward Action-Controllable Video World Models) 研究者开始将动作作为条件输入,让模型根据指定动作生成对应的未来视频。这推动了从被动预测向主动控制的转变。代表工作包括VideoPolicy、GE-ACT等。
- 结构感知生成(Structure-Aware Generation with Interaction and Geometry Priors) 进一步引入物体级交互信息、几何约束或3D场景表示,使生成的视频不仅像素匹配,而且在物理和空间上更合理。例如,结合NeRF或3D高斯散点的世界模型能够处理遮挡、物体刚性运动等。
- 从视频骨干到基础世界模型(From Video Backbones to Foundation World Models) 利用大规模视频生成模型(如Sora、Cosmos等)的预训练能力,构建可以从互联网视频中学习通用物理世界动态的“基础世界模型”。这类模型(例如Cosmos-Policy、GigaWorld)展现了强泛化性,但也面临计算成本和可控性挑战。
每个子阶段,论文都概述了技术路线、主流数据集(如Bridge Data、RoboNet、MimicGen)以及评估指标(如FVD、动作条件一致性、物理合理性)。同时指出了当前开放挑战,包括模型的可伸缩性、长期一致性、以及环境交互性的不足。
实验:设置、指标与结果
本文是综述论文,原文未进行新的统一实验。但是,在各节中,作者系统总结了相关工作中使用的实验设置、数据集和评估指标:
- 数据集 包括机器人操作数据集(Bridge Data、MimicGen、RoboNet)、导航和自动驾驶数据集(nuScenes、Waymo Open、CARLA)以及大规模互联网视频(如Videos from Kinetics、Ego4D等)。论文指出,不同子任务下数据集规模和质量差异很大。
- 评估指标 对于视频世界模型,常用指标包括Fréchet Video Distance (FVD)、Inception Score (IS)、动作条件准确性(Action Accuracy)、以及物理一致性(如碰撞率)。对于策略,常用任务成功率(Success Rate)、平均回报(Average Return)和泛化测试。对于作为模拟器的世界模型,则关注模型预测误差与真实环境执行效果之间的相关性(如Reality Gap)。
- 基准和对比 原文未提供统一实验,但在各子节中给出了代表性方法的定性比较和性能参考。例如在动作可控视频世界模型中,论文提到VideoPolicy在CALVIN和Bridge数据集上取得了优于纯生成模型的结果,但具体数值因模型和设置而异。
总体而言,综述通过引用大量已有文献的实验结果,构建了一个实证全景,但读者需要自行查阅原文以获取具体数值。
结论:贡献、局限与启发
原文未设置独立的结论章节,但全文通过对世界模型文献的系统梳理,给出了重要的总结性观点。 主要贡献:
- 首次从机器人学习视角提出统一分类框架,将世界模型的功能角色归纳为“用于策略”、“作为模拟器”、“用于视频生成”三大类,填补了文献碎片化的空白。
- 收录了截至2026年初的大量最新工作(包含大量2025-2026年的preprint和会议论文),时间覆盖全面。
- 将导航和自动驾驶领域纳入讨论,扩展了传统机器人操作以外的应用视野,并给出了数据集和基准的汇总。
- 明确指出了世界模型的核心能力(预见、想象驱动规划、数据扩增)及其与策略设计的关系。
局限:
- 作为综述,未进行统一的量化对比实验,不同工作之间的性能比较需要读者自行查阅原始文献。
- 世界模型在真实机器人上的部署面临严峻挑战:预测精度与计算开销之间的权衡、长期一致性、以及从模拟到现实的迁移(Sim-to-Real)仍然是开放问题。
- 对于世界模型如何与大规模预训练模型深度融合(例如VLA和扩散模型的结合),论文虽已涉及,但该领域变化极快,部分最新工作可能未被收录。
启发与未来方向:
- 构建“基础世界模型”(Foundation World Model)是大势所趋,利用大规模互联网视频预训练通用物理知识,再通过少量机器人数据微调适配下游任务。
- 更紧密的“模型-策略联合学习”(End-to-End World Model + Policy)可能替代分离式设计。
- 对于高动态场景(如灵巧操作、高速运动),需要引入更精细的物理先验和实时推理能力。
- 可交互、结构感知的世界模型将成为下一代具身智能的核心组件,也是评测体系变革的关键。