
导读
当前,大型语言模型(LLMs)的快速发展使“自动研究”从科幻走向了现实。像AutoResearchClaw、AI Scientist、ROBIN等系统已经能够以有限的人工干预,完成从创意生成、实验设计、代码编写到论文写作的全流程。然而,这些系统大多被设计为“隐藏的串行管道”:用户输入一个主题,系统黑盒式地输出一篇论文。这种模式存在两大痛点:一是缺乏交互性,用户无法在过程中观察、干预或调整研究方向;二是实验执行的可信度不足,常见失败模式包括实验仅部分运行、中间结果难以查看、最终论文中的结果表格与实际执行输出不一致。真实的研究是交互式、迭代、角色专业化且工件密集型的过程,而现有系统尚未能支持这种 “实验室原生” 的体验。 针对这一缺口,来自多家机构的研究人员(Fan Wu、Cheng Chen、Zhenshan Tan等)提出了 Claw AI Lab,一个实验室原生的自主多智能体研究平台。其核心创新在于将自动研究从“隐藏的 prompt-to-paper 管道”转变为“交互式 AI 实验室”。用户只需输入一个提示,即可实例化一个包含可定制角色、协作工作流、实时监控和回滚恢复功能的完整研究团队。尤其引人注目的是,平台引入了一个称为 Claw-Code Harness 的关键组件,它将本地代码库、数据集和检查点连接到可运行的实验,并将执行工件反馈回研究循环,从而显著改善了实验完成度和结果完整性。在内部评估中,Claw AI Lab 在想法新颖性、实验完整性和论文展示质量上被 AI 专家评判持续优于基线系统。 这篇论文不仅提出了一个更强的平台,更提出了一种更优的自主研究框架:从自动化论文写作转变为构建可用、可靠的科学基础设施。对于关注 AI 辅助科研、多智能体系统、科学自动化的研究人员和工程师来说,这是值得精读的近期工作。
论文基本信息

摘要
本文介绍了 Claw AI Lab,一个实验室原生的自主研究平台,它将自动研究从隐藏的 prompt-to-paper 管道升级为交互式 AI 实验室。与以单智能体或固定串行工作流为中心的系统不同,Claw AI Lab 允许用户通过一个提示实例化完整的研究团队,支持可定制角色、协作工作流、实时监控、工件检查以及通过统一仪表板进行回滚/恢复控制。平台还支持三种不同的研究模式:探索(Explore)、讨论(Discussion)和复现(Reproduce),使自动研究在实践中更具可操控性和实验室感。Claw AI Lab 的一个关键实际贡献是 Claw-Code Harness,它连接本地代码库、数据集和检查点到可运行的实验,并将执行工件反馈回研究循环。因此,该 harness 不仅改善了执行集成,还提升了实验完成度和结果完整性:实验更易于检查、迭代,并能忠实地转移到最终论文中,减少了部分运行和格式错误结果报告等常见失败模式。在五个 AI 研究案例的内部评估中,以 AutoResearchClaw 为基线,Claw AI Lab 在想法新颖性、实验完整性和论文展示质量上被 AI 专家评判一致偏好。我们将 Claw AI Lab 视为一个全新范式的前期步骤:将自主研究视为可用、交互式和可靠性意识的科学基础设施。
引言:论文要解决什么问题
现有自动研究系统的局限性
近年来自动研究系统取得了显著进展。AutoResearchClaw (Liu 等, 2026)、autoresearch (Karpathy, 2026)、AI Scientist (Lu 等, 2024)、ROBIN (Ghareeb 等, 2025)、AI co-scientist (Gottweis 等, 2025) 等系统展示了在最小人类干预下从创意到论文的全自动流程可行性。然而,这些系统大多将自动研究视为一个黑盒管道:用户提供主题,系统输出最终论文,中间过程几乎不可见、不可控。这种设计忽视了一个关键事实——真实的研究是交互式、迭代、角色专业化和工件密集型的活动。
核心痛点:缺乏交互性、可检查性和可靠性
Claw AI Lab 的引言明确指出,当前自动研究领域的核心痛点包括:
- 缺乏交互性:用户无法在过程中监控进展、检查中间输出或动态调整研究方向。
- 实验执行不可靠:常见失败模式包括实验仅部分运行(例如训练未完成、评估集未覆盖)、中间结果难以查看、最终论文中的结果表格未能忠实反映实际执行输出。
- 工件管理不完善:代码、结果、图表和日志等工件未能作为第一公民被系统管理,导致可复现性受损。
Claw AI Lab 的解决方案
针对以上痛点,Claw AI Lab 提出了一种全新的框架:不是将自动研究等同于自动论文生成,而是将其重新定义为“交互式 AI 实验室”的操作。具体而言,平台提供:
- 一个统一仪表板,包含实时事件流、多项目监控、工件检查和一键回滚。
- 支持三种研究模式的灵活工作流(探索、讨论、复现)。
- 一个核心组件 Claw-Code Harness,它将本地研究资产(代码库、数据集、检查点)与可运行实验桥接,并将执行结果反馈回研究循环。
为什么值得读
这篇论文的价值在于它不仅提出了一个更强的平台,更提出了一种更优的自主研究框架——从纯粹的自动化论文写作转向构建可用、可检查、可靠性意识的科学基础设施。这种视角转变对 AI 辅助科研乃至科学方法论都具有启发意义。此外,论文在方法设计上采用了分层多智能体架构,并详细介绍了 Claw-Code Harness 的设计,为后续系统开发提供了参考。
方法:核心思路与技术路线
总体架构:分层多智能体金字塔
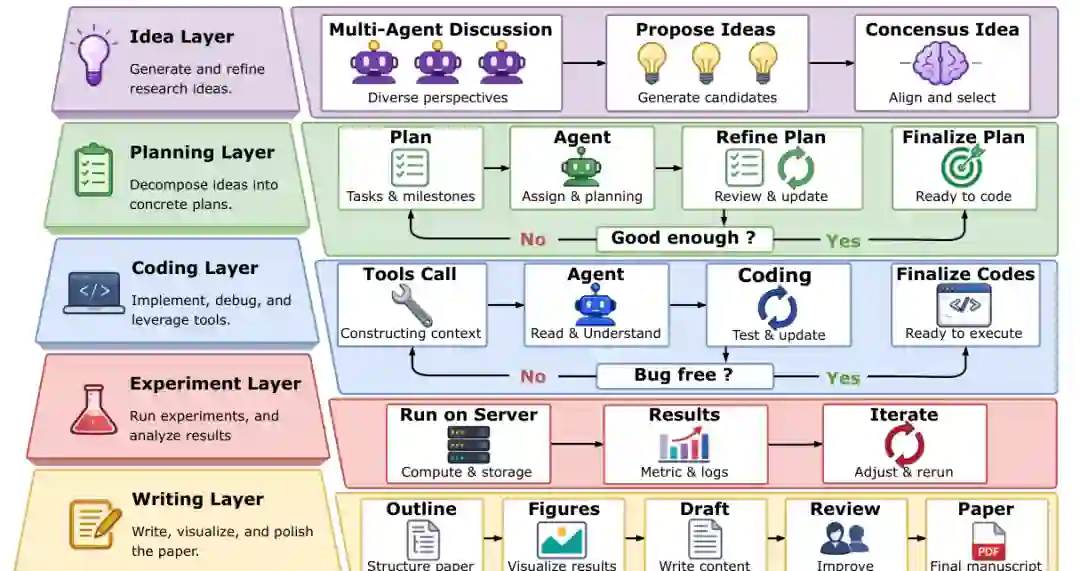
Idea 层(创意层):多智能体讨论与共识
创意生成过程从多智能体讨论阶段开始。系统不依赖单一视角,而是鼓励通过并行提议、结构化辩论和细化来探索问题空间。多个智能体共同探索问题空间,提出多样化的想法候选。之后通过共识机制选择和整合最有前景的方向。这种讨论驱动设计提高了鲁棒性和多样性,更好地反映了真实研究想法是如何通过协作而非孤立生成形成的。
Planning 层(规划层):任务分解与迭代细化
给定选定的创意,系统将其分解为结构化计划,包括任务、依赖关系和里程碑。一个规划代理通过验证循环(“足够好吗?”)迭代细化计划,不完整或模糊的组件在执行前被修订。关键的是,规划不是一次性过程,而是支持自适应细化,允许基于下游阶段(例如编码失败或实验结果)的反馈进行更新。这确保计划保持可行并与实际约束对齐。
Coding 层(编码层):基于 Claw-Code Harness 的代理编码循环
编码层将获批的实验计划转化为可运行的研究代码。这是 Claw AI Lab 最核心的贡献之一。该层以 Claw-Code Harness 为中心(基于 UltraWorkers, 2026 的 claw CLI 代理工具),实现了一个代理编码循环:模型可以检查本地代码库、数据集和检查点,然后通过受控工具(包括 bash、read file、write file、edit file、glob search 和 grep search)编写、运行、调试和细化实验文件。该 harness 不仅提供执行封装,还成为连接本地研究资产与可运行实验、并将实验输出连接回更广泛研究工作流的接口。 通过这种方式,harness 加强了实现、执行和报告之间的连续性。它改善的不仅是实验能否运行,还包括实验是否被完整执行、是否可检查、以及是否被正确反映到最终论文中。
Experiment 层(实验层):运行与分析
实验层执行已完成的编码任务,运行实验并分析结果。该层从编码层接收可执行代码和配置,在本地或远程服务器上运行,收集指标和日志,并将结果反馈给上游层(例如,如果实验失败,可触发规划或编码层的修订)。平台支持对中间结果的实时监控和工件检查。
Writing 层(写作层):论文撰写与可视化
写作层负责撰写、可视化和润色最终论文。给定规划、实验输出(包括图表、数值结果)和代码库,写作代理生成论文初稿,包括大纲、内容、图表和最终手稿。该层还使用专门的图形生成模型(如 Gemini-3-Pro-Image-Preview)生成论文插图。通过与实验层的紧密连接,写作层能够确保论文中的结果表格和描述忠实反映实际执行输出,减少部分运行或格式错误报告等常见失败模式。
三种研究模式
Claw AI Lab 支持三种不同的研究模式,使用户可以根据需求选择合适的工作流:
- Explore 模式 用于探索性研究,从初始化想法开始,自动完成所有阶段。
- Discussion 模式 强调多智能体协作讨论,适用于需要多角度分析的主题。
- Reproduce 模式 专注于复现已有工作和分析,使用独立的复现提示。
这些模式使自动研究在实践中更具可操控性和灵活性。
实验:设置、指标与结果
实验设置
Claw AI Lab 以完全自主项目模式运行。模型配置如下:
- 主模型和编码模型 GPT-5.4
- 图形生成模型 Gemini-3-Pro-Image-Preview(用于论文插图)
- 后备模型 Qwen3.5-Plus / Qwen-Plus
基线系统 AutoResearchClaw 的配置为:
- 主模型 GPT-5.4
- 图像模型 Gemini-2.5-Pro-Flash-Image
- 后备模型 GPT-4o / GPT-4o-mini
主题选择
实验在四个不同的主题上进行比较,包含三个研究主题和一个复现主题:
- 研究主题 1:Quantifying Hallucination in Generated Video Models(量化生成视频模型中的幻觉)
- 研究主题 2:LIAR Dataset-Based Fake News Classification Solution(基于 LIAR 数据集的假新闻分类方案)
- 研究主题 3:A Q-Learning Approach for Student Performance Improvement Using Public Educational Data(利用公共教育数据的 Q-learning 学生成绩改进方法)
- 复现主题 4:Reproducing and Analyzing PhyCustom (Wu et al., 2025) on Flux (Labs, 2024)(在 Flux 上复现和分析 PhyCustom)
评估维度与协议
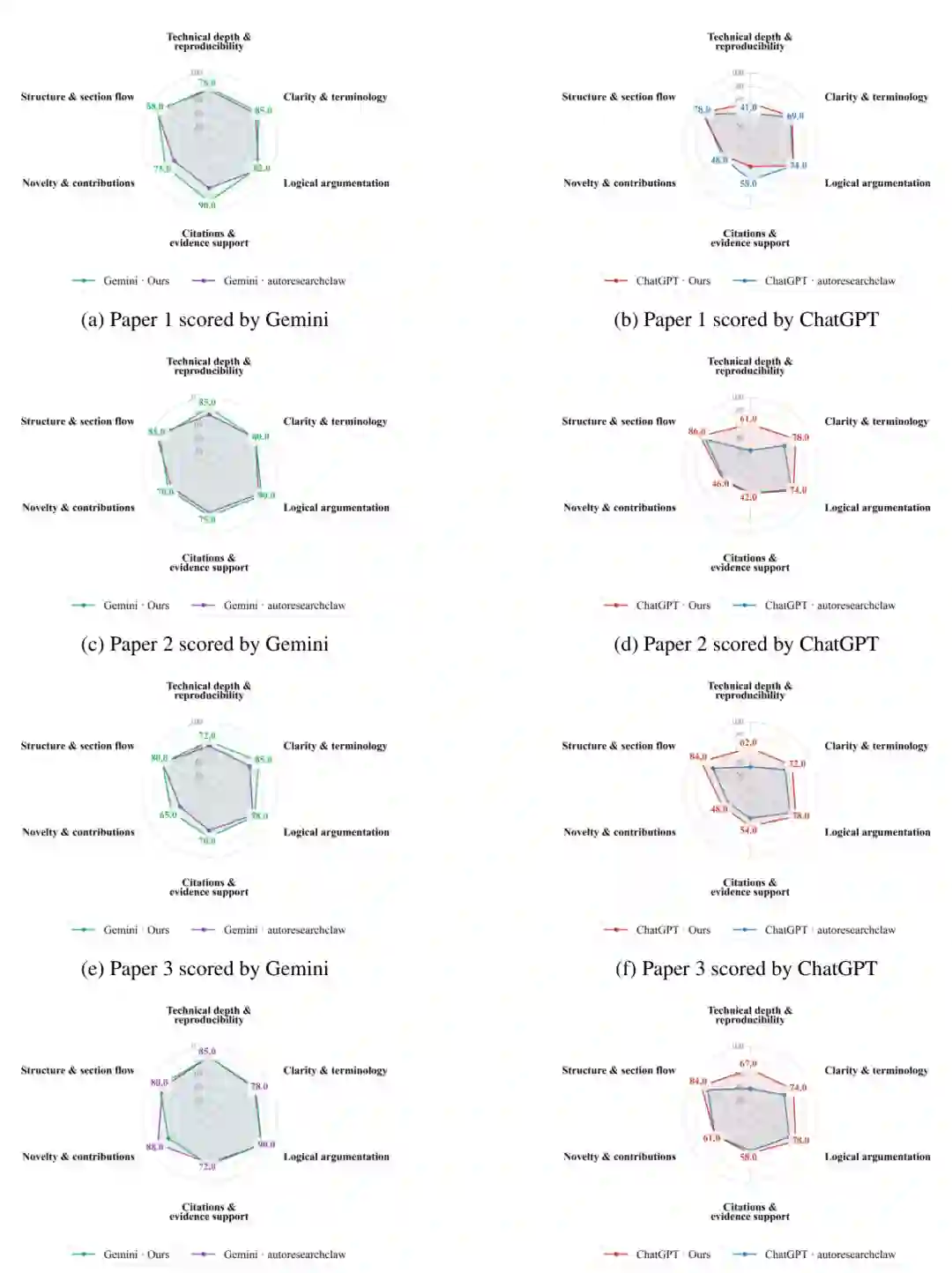
每篇生成的论文由两个 LLM 评估器进行评审:ChatGPT 5.4 Thinking 和 Gemini 3.1 Pro。评估在六个维度上进行,每个维度采用100分制:
- 技术深度与可复现性 (technical depth&reproducibility)
- 结构与段落流畅性 (structure§ion flow)
- 新颖性与贡献 (novelty&contributions)
- 清晰度与术语 (clarity&terminology)
- 逻辑论证 (logical argumentation)
- 引用与证据支持 (citations&evidence support)
每次评审在全新的对话窗口中进行,以减少上下文携带效应。研究论文使用相同的学术评审提示,复现论文使用独立的复现导向提示。
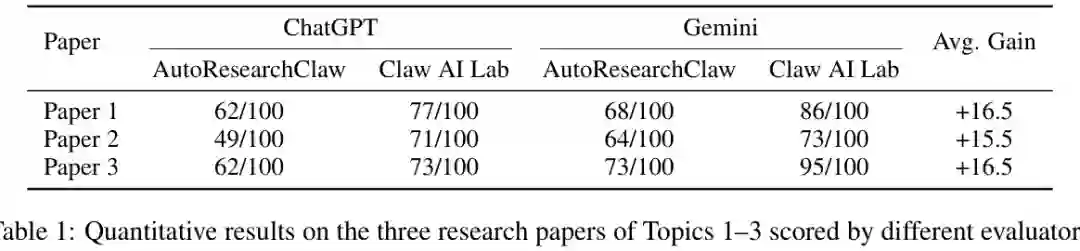
主要结果

讨论
需要注意的是,论文并没有声称Claw AI Lab已经解决了自主科研的所有问题。它更像是把研究代理从“单次生成器”推向“可运行的科研操作系统”:用户可以检查中间工件,系统可以根据失败反馈回滚和修正,实验输出可以被写作层直接引用。这种设计使自动研究从演示型prompt工程更接近真实研究工作流。 论文将改进归因于 Claw-Code Harness 带来的更可靠和高效的实验执行。通过连接本地代码库、数据集和检查点,该 harness 使实验更易于检查和迭代,为生成的论文提供了更可信的经验支持,从而带来更稳定的整体论文质量提升。此外,三种研究模式和分层多智能体架构确保了更好的全局协调和局部优化,进一步促进了实验完整性和论文忠实度。
消融/分析
原文未明确进行独立的消融实验或组件分析。
结论:贡献、局限与启发
贡献
Claw AI Lab 的主要贡献可以总结为以下几点:
- 全新的自主研究框架:从自动化论文写作转变为构建可用的、交互式的、可靠性意识的 AI 实验室系统,而不只是一个更强的论文生成管道。
- Claw-Code Harness:连接本地代码库、数据集和检查点的核心组件,使实验可运行,并将执行工件反馈回研究循环,显著改善了实验完成度和结果完整性。
- 分层多智能体架构:将端到端研究分解为创意、规划、编码、实验和写作五个层次,每个层次由专业智能体负责并通过验证循环迭代细化。
- 三种研究模式:支持探索、讨论和复现,使自动研究在不同场景下更具可操控性。
- 一致且显著的性能提升:在四个主题的评估中,相对于强基线 AutoResearchClaw 获得一致改进(研究主题平均提升 15.5-16.5 分,复现主题提升 5.0 分),并被两个 LLM 评估器一致偏好。
局限
原文未明确说明局限性。从系统设计和实验设置来看,可能存在以下潜在局限(基于论文内容合理推断,非原文直接陈述):评估依赖 LLM 评估器而非真实人类专家评审,可能无法完全模拟同行评审质量;实验仅在四个主题上进行比较,样本量有限;系统依赖单一模型(GPT-5.4)作为主模型,未测试在其他模型上的泛化性;Claw-Code Harness 对本地环境和资源有依赖,可能影响可复现性。但需明确,这些是作者未在原文中讨论的内容,读者应结合自身理解。
启发
Claw AI Lab 指向了自主研究领域更广阔的方向。论文作者明确指出:未来自主研究的方向不是更长的隐藏管道,而是交互式、可检查、可靠性意识的 AI 实验室系统。从更广泛的角度看,这篇论文的贡献不仅在于提出了一个更强的平台,更在于提出了一种更优的自动研究框架——从“自动论文写作”转变为“构建可用的科学基础设施”。这一视角转变对于后续自主科学发现系统的设计具有重要的指导意义。此外,Claw-Code Harness 作为实验执行和后端的桥梁,为其他自动化科研平台提供了可借鉴的组件化思路。对于希望从事 AI 辅助科研工具开发的读者,这篇论文提供了实用的参考。
原文信息
原文链接:http://arxiv.org/abs/2605.22662v1 项目主页和代码:https://github.com/Claw-AI-Lab/Claw-AI-Lab