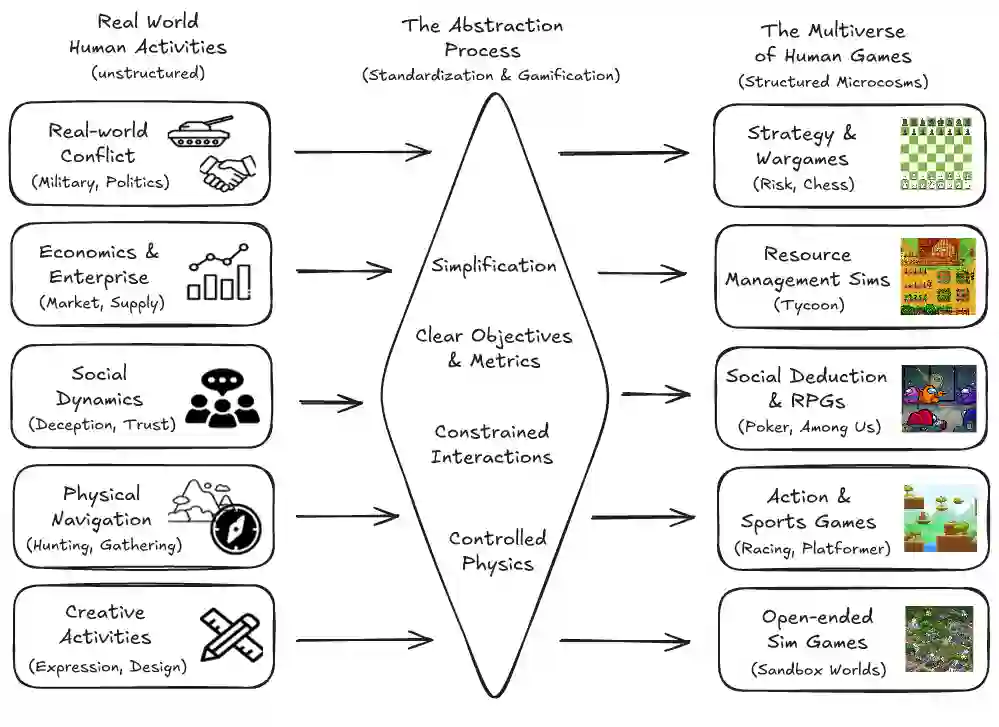
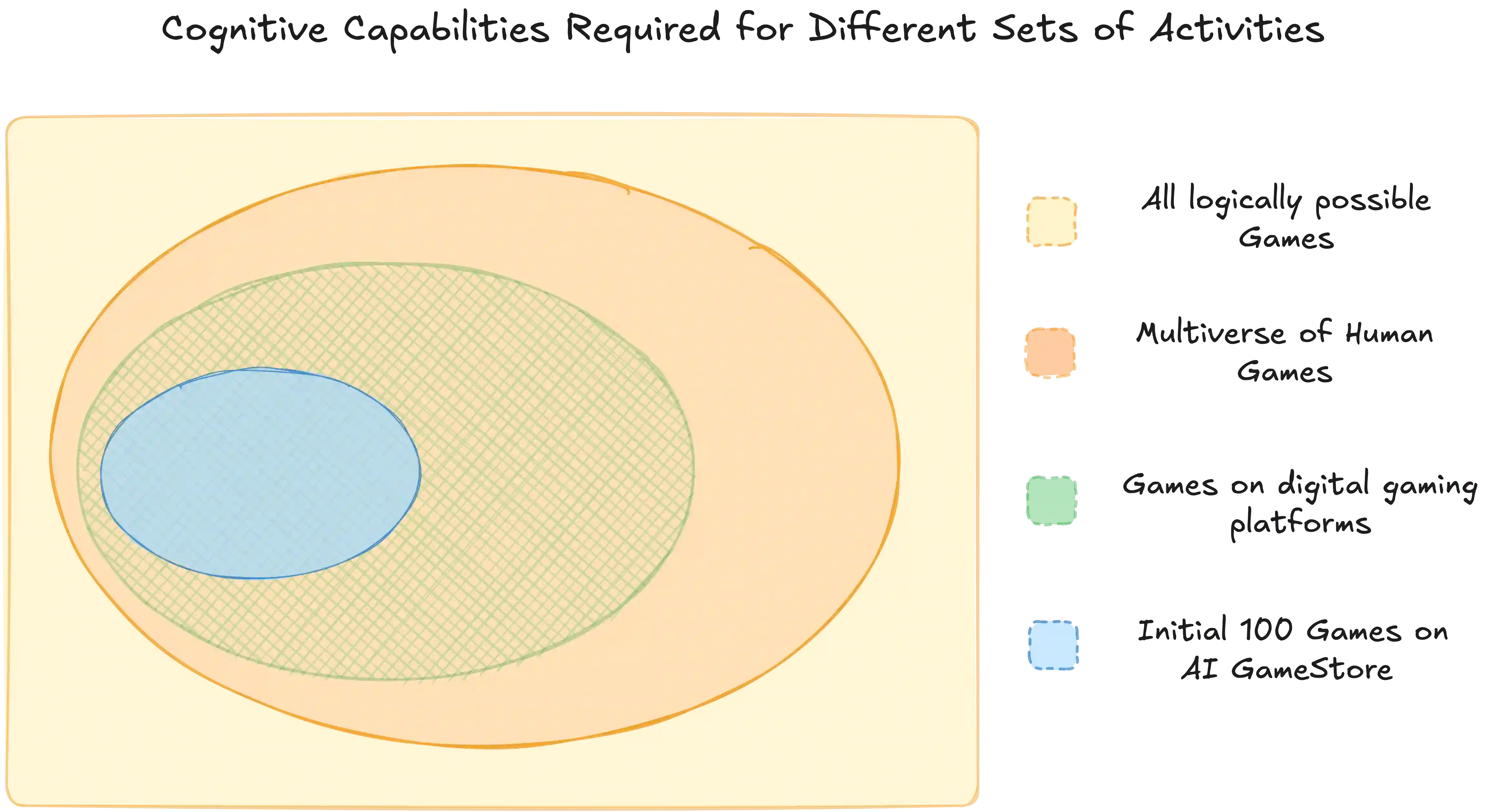
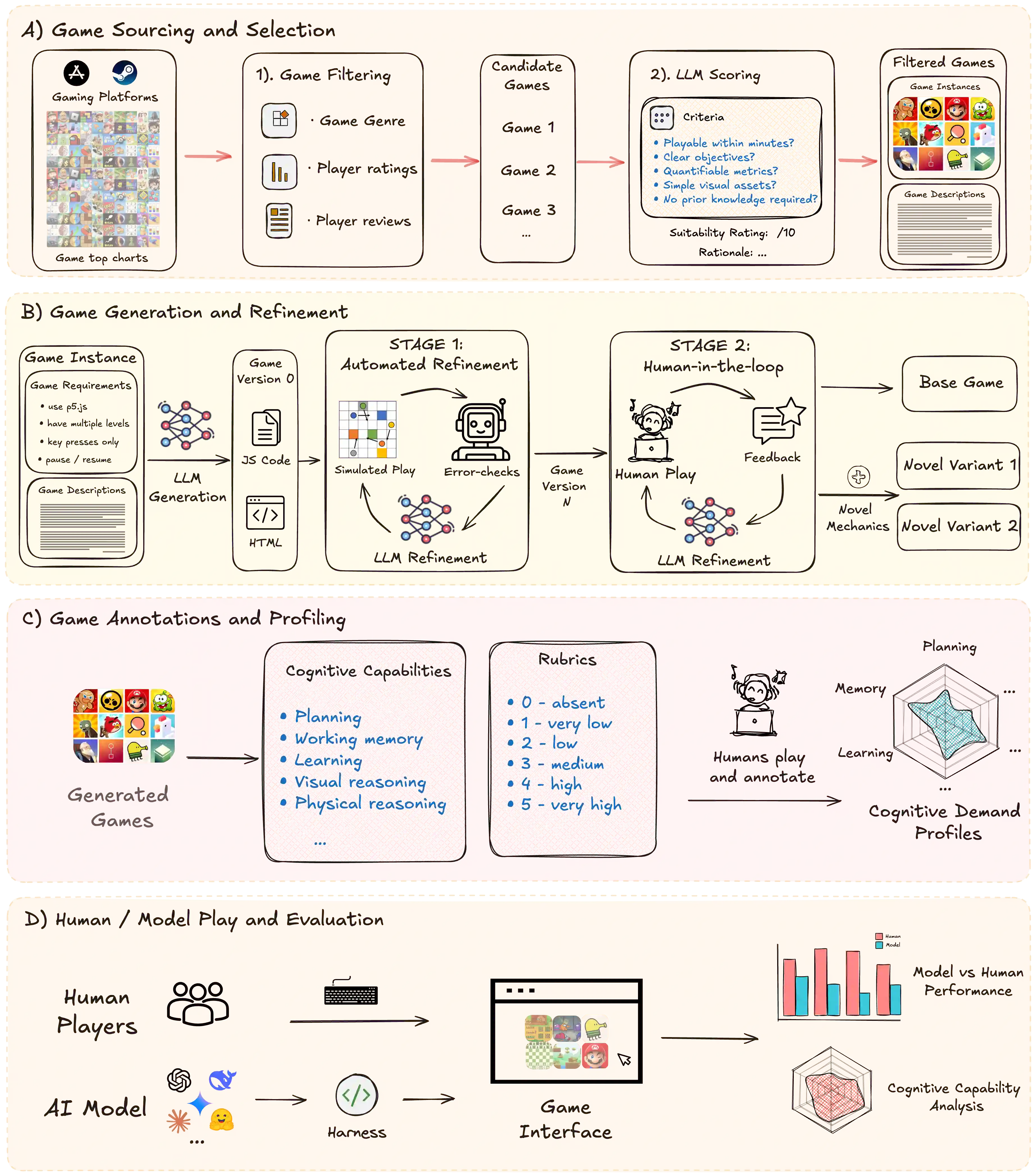
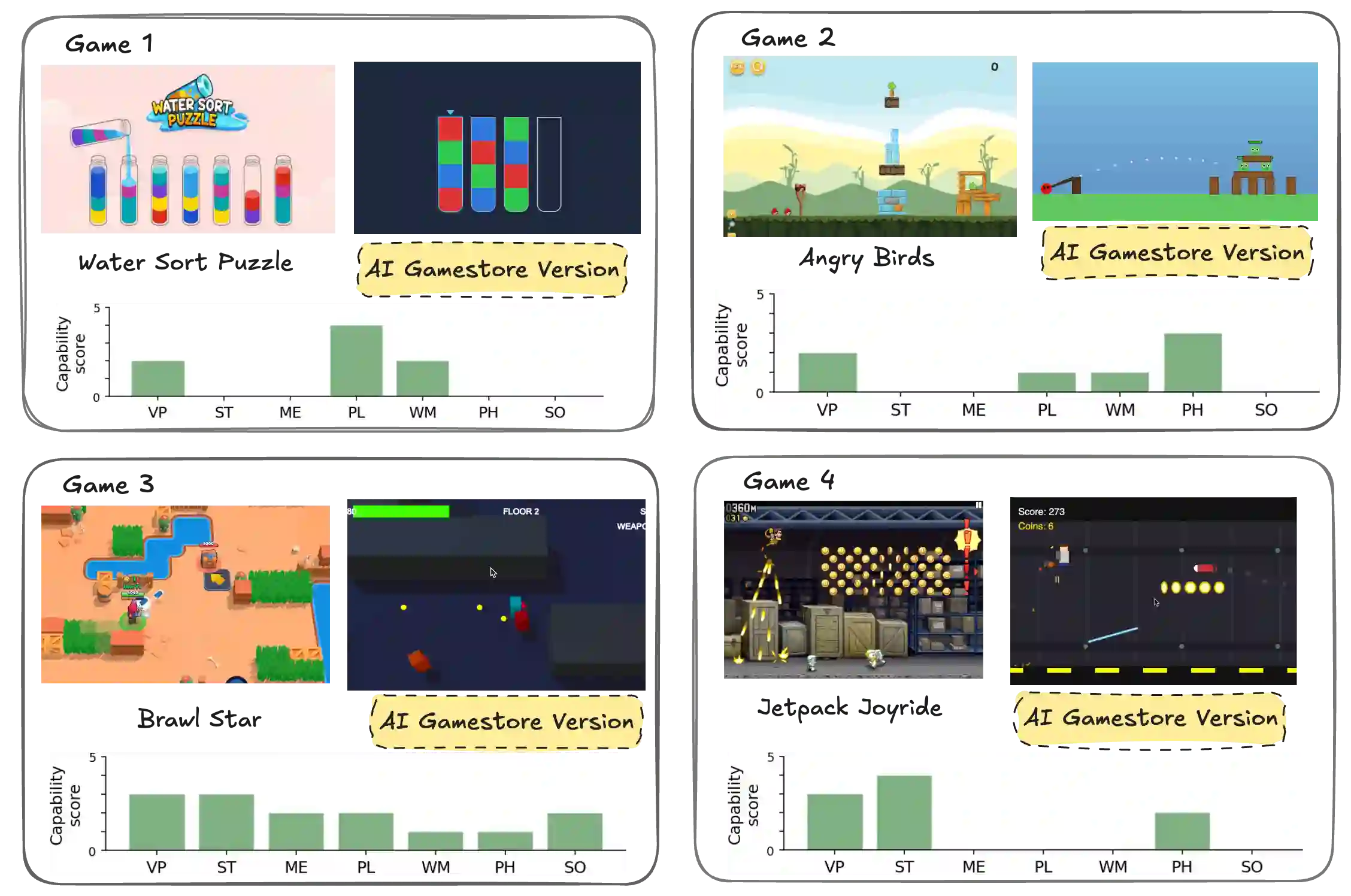
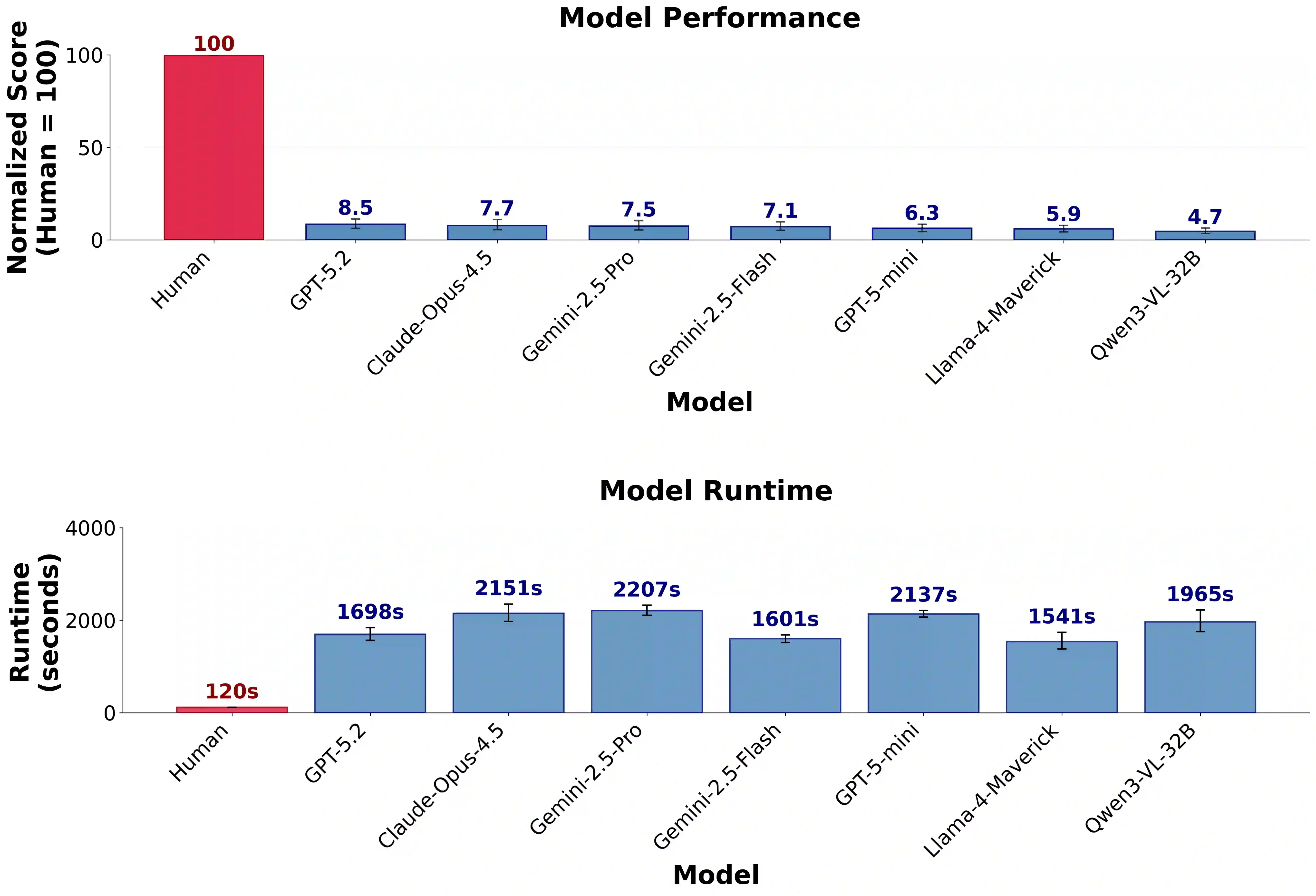
Rigorously evaluating machine intelligence against the broad spectrum of human general intelligence has become increasingly important and challenging in this era of rapid technological advance. Conventional AI benchmarks typically assess only narrow capabilities in a limited range of human activity. Most are also static, quickly saturating as developers explicitly or implicitly optimize for them. We propose that a more promising way to evaluate human-like general intelligence in AI systems is through a particularly strong form of general game playing: studying how and how well they play and learn to play \textbf{all conceivable human games}, in comparison to human players with the same level of experience, time, or other resources. We define a "human game" to be a game designed by humans for humans, and argue for the evaluative suitability of this space of all such games people can imagine and enjoy -- the "Multiverse of Human Games". Taking a first step towards this vision, we introduce the AI GameStore, a scalable and open-ended platform that uses LLMs with humans-in-the-loop to synthesize new representative human games, by automatically sourcing and adapting standardized and containerized variants of game environments from popular human digital gaming platforms. As a proof of concept, we generated 100 such games based on the top charts of Apple App Store and Steam, and evaluated seven frontier vision-language models (VLMs) on short episodes of play. The best models achieved less than 10\% of the human average score on the majority of the games, and especially struggled with games that challenge world-model learning, memory and planning. We conclude with a set of next steps for building out the AI GameStore as a practical way to measure and drive progress toward human-like general intelligence in machines.
翻译:在技术快速发展的时代,严格评估机器智能相对于人类通用智能的广泛谱系已变得日益重要且具有挑战性。传统的AI基准测试通常仅评估人类活动有限范围内的狭窄能力。其中大多数基准还是静态的,随着开发者显式或隐式地针对其进行优化,会迅速达到饱和。我们认为,评估AI系统中类人通用智能的一种更有前景的方法是通过一种特别强大的通用游戏博弈形式:研究它们如何以及以何种水平游玩和学习游玩**所有可构想的人类游戏**,并与具有相同经验水平、时间或其他资源的人类玩家进行比较。我们将“人类游戏”定义为人类为人类设计的游戏,并论证了由人类能够想象并享受的所有此类游戏构成的“人类游戏多元宇宙”在评估上的适用性。作为实现这一愿景的第一步,我们介绍了AI GameStore,这是一个可扩展的开放式平台,它利用大语言模型并结合人类参与,通过自动从流行的人类数字游戏平台获取并适配标准化、容器化的游戏环境变体,来合成新的代表性人类游戏。作为概念验证,我们基于苹果App Store和Steam的排行榜生成了100个此类游戏,并在短时游戏片段上评估了七个前沿视觉语言模型。表现最佳的模型在大多数游戏上取得的分数不到人类平均分的10%,尤其是在挑战世界模型学习、记忆和规划能力的游戏上表现不佳。最后,我们提出了一系列后续步骤,以将AI GameStore建设为一种切实可行的方法,用于衡量并推动机器向类人通用智能方向取得进展。