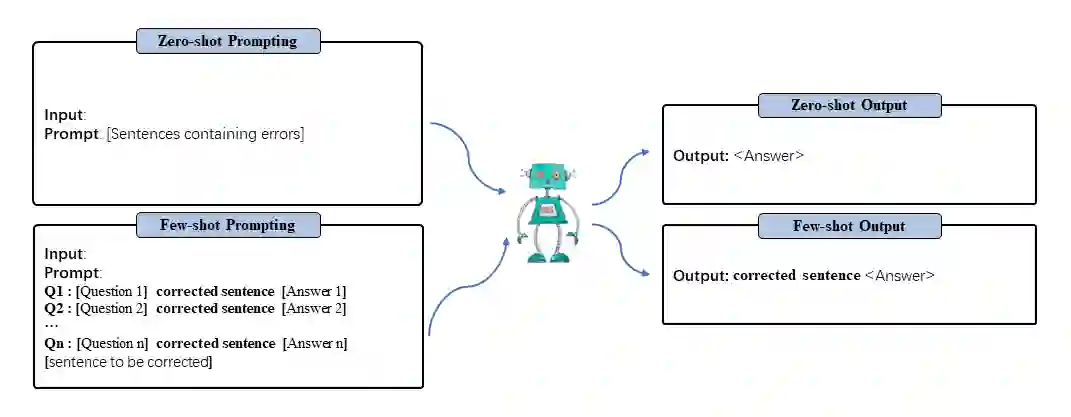
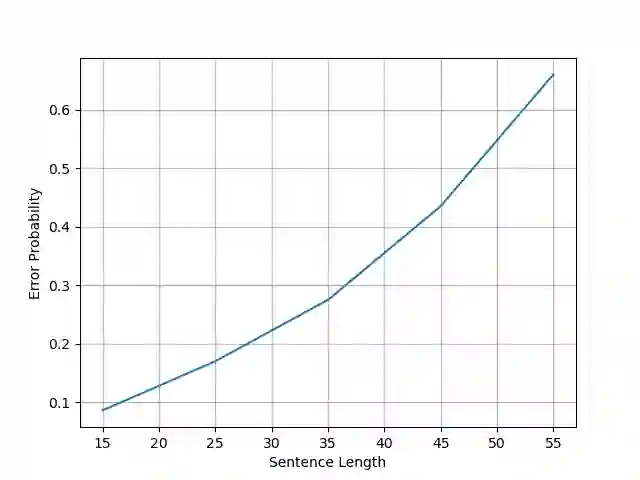
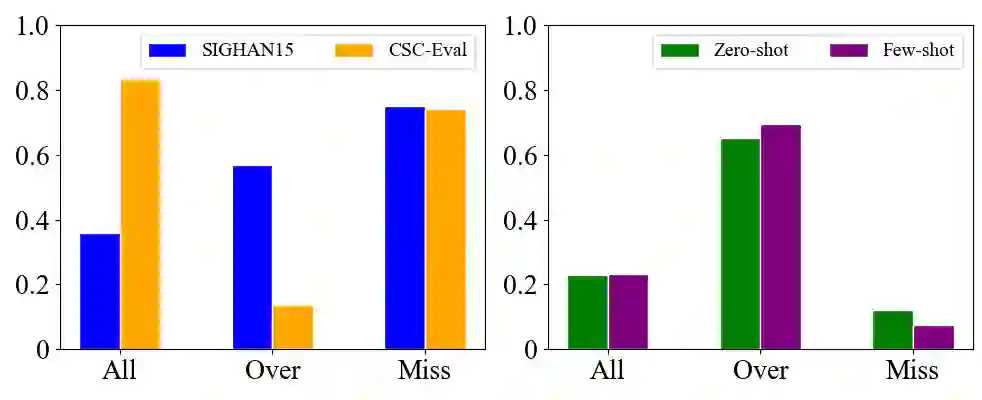
As large language models, such as GPT, continue to advance the capabilities of natural language processing (NLP), the question arises: does the problem of correction still persist? This paper investigates the role of correction in the context of large language models by conducting two experiments. The first experiment focuses on correction as a standalone task, employing few-shot learning techniques with GPT-like models for error correction. The second experiment explores the notion of correction as a preparatory task for other NLP tasks, examining whether large language models can tolerate and perform adequately on texts containing certain levels of noise or errors. By addressing these experiments, we aim to shed light on the significance of correction in the era of large language models and its implications for various NLP applications.
翻译:随着GPT等大语言模型不断推进自然语言处理(NLP)的能力,一个问题随之浮现:纠错问题是否依然存在?本文通过两个实验探究纠错在大语言模型背景下的作用。第一个实验将纠错视为独立任务,采用基于GPT类模型的少样本学习技术进行错误校正。第二个实验探索纠错作为其他NLP任务的预备任务,检验大语言模型能否容忍含有一定噪声或错误的文本并保证充分性能。通过上述实验的开展,本研究旨在揭示大语言模型时代纠错的重要性及其对各类NLP应用的影响。