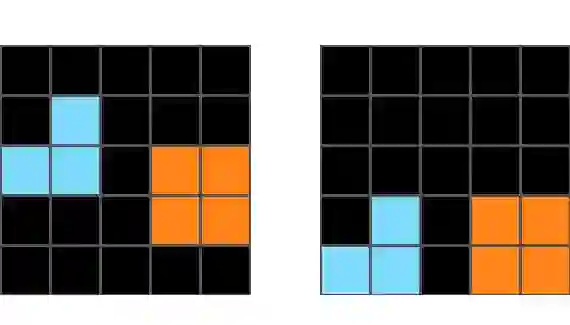
The ability to derive underlying principles from a handful of observations and then generalize to novel situations -- known as inductive reasoning -- is central to human intelligence. Prior work suggests that language models (LMs) often fall short on inductive reasoning, despite achieving impressive success on research benchmarks. In this work, we conduct a systematic study of the inductive reasoning capabilities of LMs through iterative hypothesis refinement, a technique that more closely mirrors the human inductive process than standard input-output prompting. Iterative hypothesis refinement employs a three-step process: proposing, selecting, and refining hypotheses in the form of textual rules. By examining the intermediate rules, we observe that LMs are phenomenal hypothesis proposers (i.e., generating candidate rules), and when coupled with a (task-specific) symbolic interpreter that is able to systematically filter the proposed set of rules, this hybrid approach achieves strong results across inductive reasoning benchmarks that require inducing causal relations, language-like instructions, and symbolic concepts. However, they also behave as puzzling inductive reasoners, showing notable performance gaps in rule induction (i.e., identifying plausible rules) and rule application (i.e., applying proposed rules to instances), suggesting that LMs are proposing hypotheses without being able to actually apply the rules. Through empirical and human analyses, we further reveal several discrepancies between the inductive reasoning processes of LMs and humans, shedding light on both the potentials and limitations of using LMs in inductive reasoning tasks.
翻译:从少量观察中推导出潜在原理并泛化至新情境的能力——即归纳推理——是人类智能的核心。先前研究表明,尽管语言模型在研究基准测试中取得显著成功,但其在归纳推理方面往往表现不足。本研究通过迭代假设精炼——一种比标准输入-输出提示更贴近人类归纳过程的技术——系统探究了语言模型的归纳推理能力。迭代假设精炼采用三步流程:以文本规则形式提出、选择与精炼假设。通过分析中间规则,我们发现语言模型是卓越的假设提出者(即生成候选规则的能力出众),当结合能系统性过滤所提出规则集的(任务特定)符号解释器时,这种混合方法在需要归纳因果关系、类语言指令及符号概念的推理基准测试中取得强劲表现。然而,它们同时也展现出令人困惑的归纳推理行为,在规则归纳(即识别合理规则)与规则应用(即将提出规则应用于实例)之间存在显著性能差距,这表明语言模型虽能提出假设,却无法实际应用这些规则。通过实证分析与人类评估,我们进一步揭示了语言模型与人类归纳推理过程的多重差异,阐明了语言模型在归纳推理任务中的潜力与局限性。