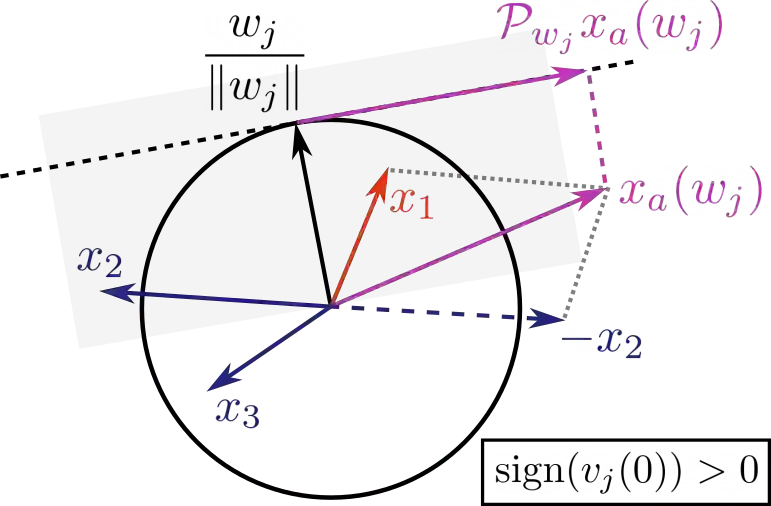
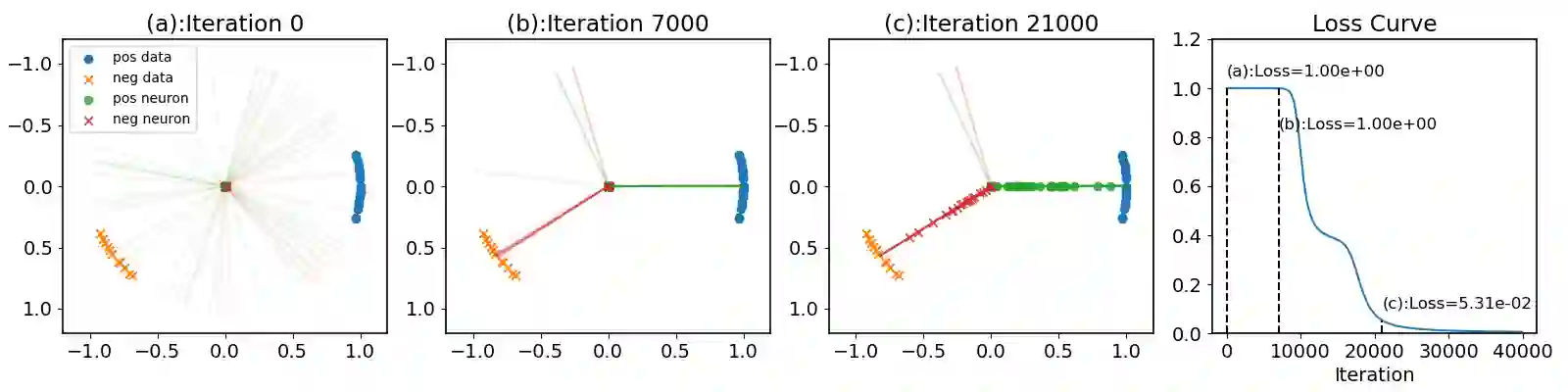
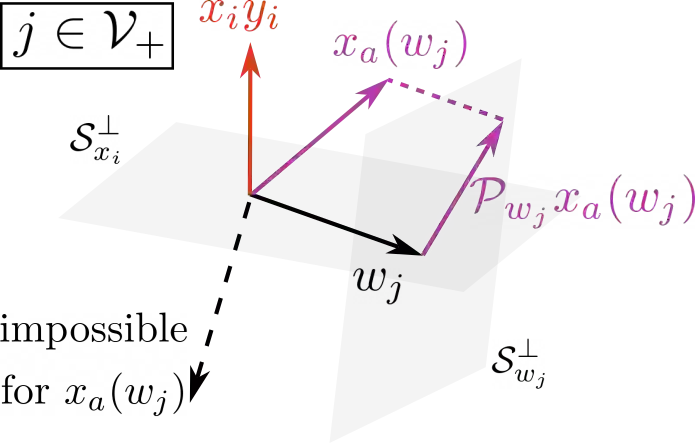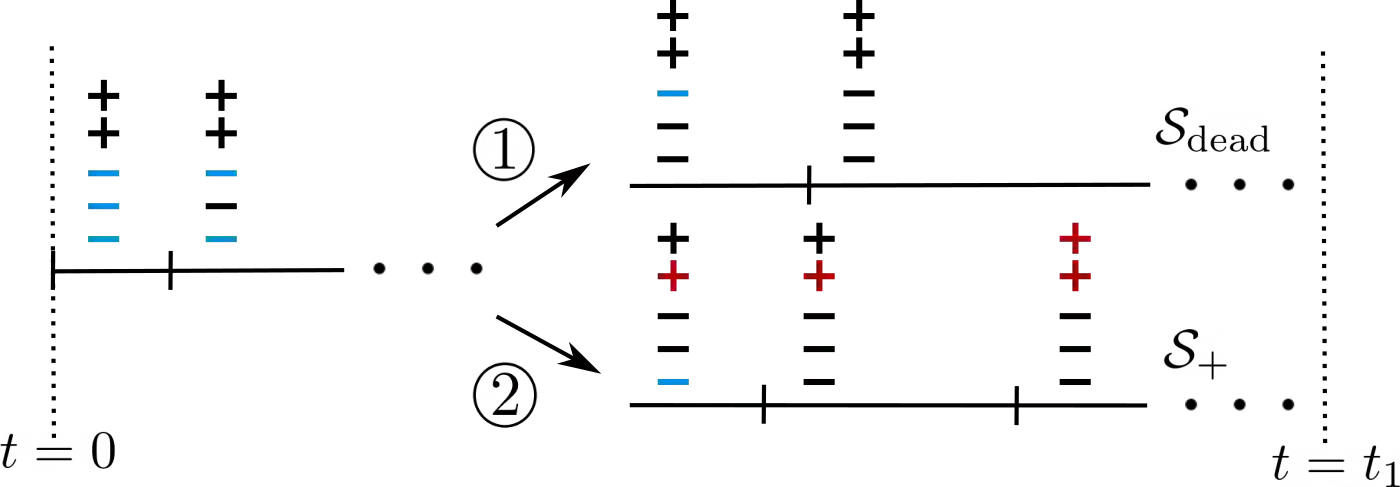This paper studies the problem of training a two-layer ReLU network for binary classification using gradient flow with small initialization. We consider a training dataset with well-separated input vectors: Any pair of input data with the same label are positively correlated, and any pair with different labels are negatively correlated. Our analysis shows that, during the early phase of training, neurons in the first layer try to align with either the positive data or the negative data, depending on its corresponding weight on the second layer. A careful analysis of the neurons' directional dynamics allows us to provide an $\mathcal{O}(\frac{\log n}{\sqrt{\mu}})$ upper bound on the time it takes for all neurons to achieve good alignment with the input data, where $n$ is the number of data points and $\mu$ measures how well the data are separated. After the early alignment phase, the loss converges to zero at a $\mathcal{O}(\frac{1}{t})$ rate, and the weight matrix on the first layer is approximately low-rank. Numerical experiments on the MNIST dataset illustrate our theoretical findings.
翻译:本文研究使用小初始化梯度流训练双层ReLU网络进行二分类的问题。我们考虑输入向量具有良好分离性的训练数据集:任意具有相同标签的输入数据对呈正相关,而不同标签的数据对呈负相关。分析表明,在训练初期,第一层神经元会依据其在第二层对应的权重,尝试与正类数据或负类数据对齐。通过对神经元方向动力学的细致分析,我们给出了所有神经元与输入数据充分对齐所需时间的$\mathcal{O}(\frac{\log n}{\sqrt{\mu}})$上界,其中$n$为数据点数量,$\mu$衡量数据分离程度。在早期对齐阶段之后,损失以$\mathcal{O}(\frac{1}{t})$速率收敛至零,且第一层权重矩阵近似低秩。在MNIST数据集上的数值实验验证了我们的理论发现。