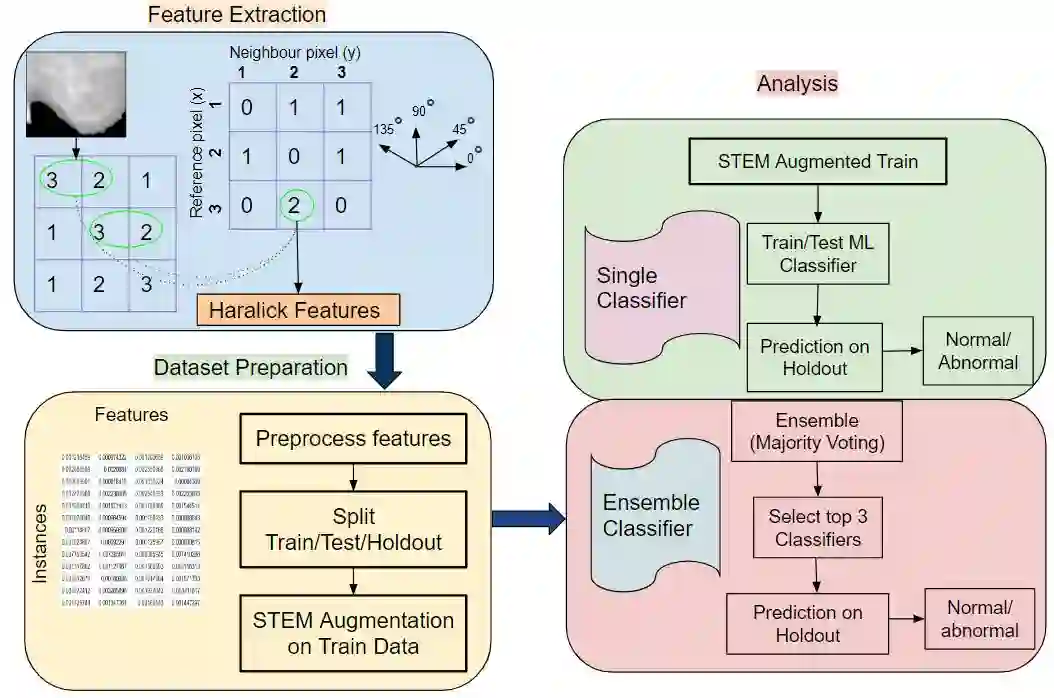
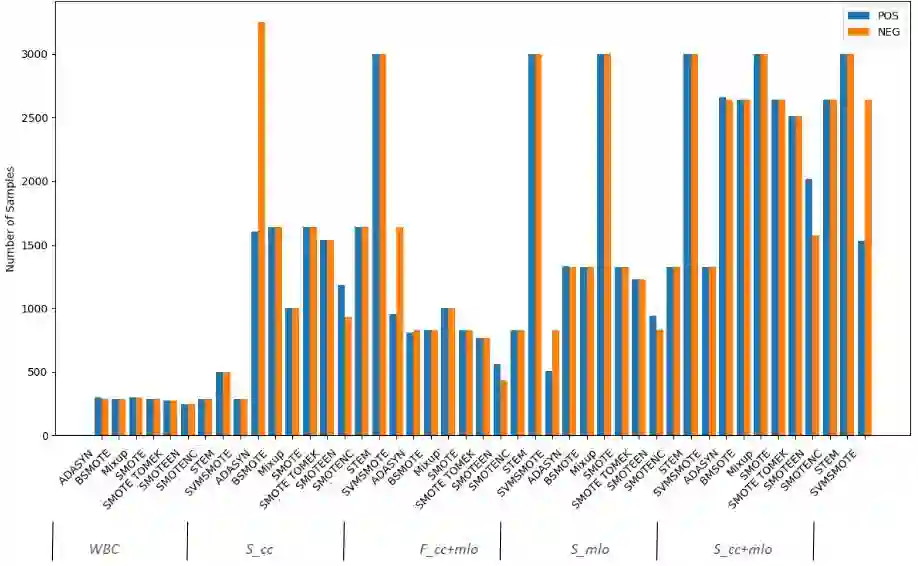
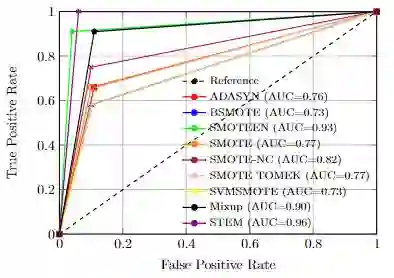
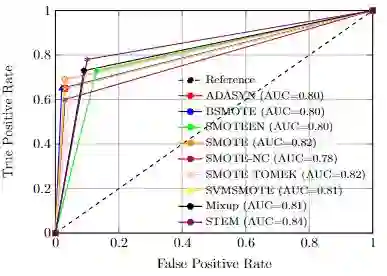
Imbalanced datasets in medical imaging are characterized by skewed class proportions and scarcity of abnormal cases. When trained using such data, models tend to assign higher probabilities to normal cases, leading to biased performance. Common oversampling techniques such as SMOTE rely on local information and can introduce marginalization issues. This paper investigates the potential of using Mixup augmentation that combines two training examples along with their corresponding labels to generate new data points as a generic vicinal distribution. To this end, we propose STEM, which combines SMOTE-ENN and Mixup at the instance level. This integration enables us to effectively leverage the entire distribution of minority classes, thereby mitigating both between-class and within-class imbalances. We focus on the breast cancer problem, where imbalanced datasets are prevalent. The results demonstrate the effectiveness of STEM, which achieves AUC values of 0.96 and 0.99 in the Digital Database for Screening Mammography and Wisconsin Breast Cancer (Diagnostics) datasets, respectively. Moreover, this method shows promising potential when applied with an ensemble of machine learning (ML) classifiers.
翻译:医学影像中的不平衡数据集通常表现为类别比例失衡与异常病例稀缺。当模型基于此类数据训练时,往往会赋予正常样本更高概率,导致性能偏差。诸如SMOTE等常用过采样技术依赖于局部信息,可能引入边缘化问题。本文探究了将两个训练样本及其对应标签进行混合来生成新数据点的Mixup增广技术作为通用邻域分布的潜力。为此,我们提出STEM方法,在实例级别上融合了SMOTE-ENN与Mixup。这种集成方式使我们能够有效利用少数类别的完整分布,从而缓解类间不平衡与类内不平衡问题。我们聚焦于乳腺癌诊断这一存在普遍不平衡数据集的问题。实验结果表明,STEM方法在数字乳腺摄影筛查数据库和威斯康星乳腺癌(诊断)数据集上分别取得了0.96和0.99的AUC值。此外,该方法在与机器学习分类器集成模型结合应用时展现出良好前景。