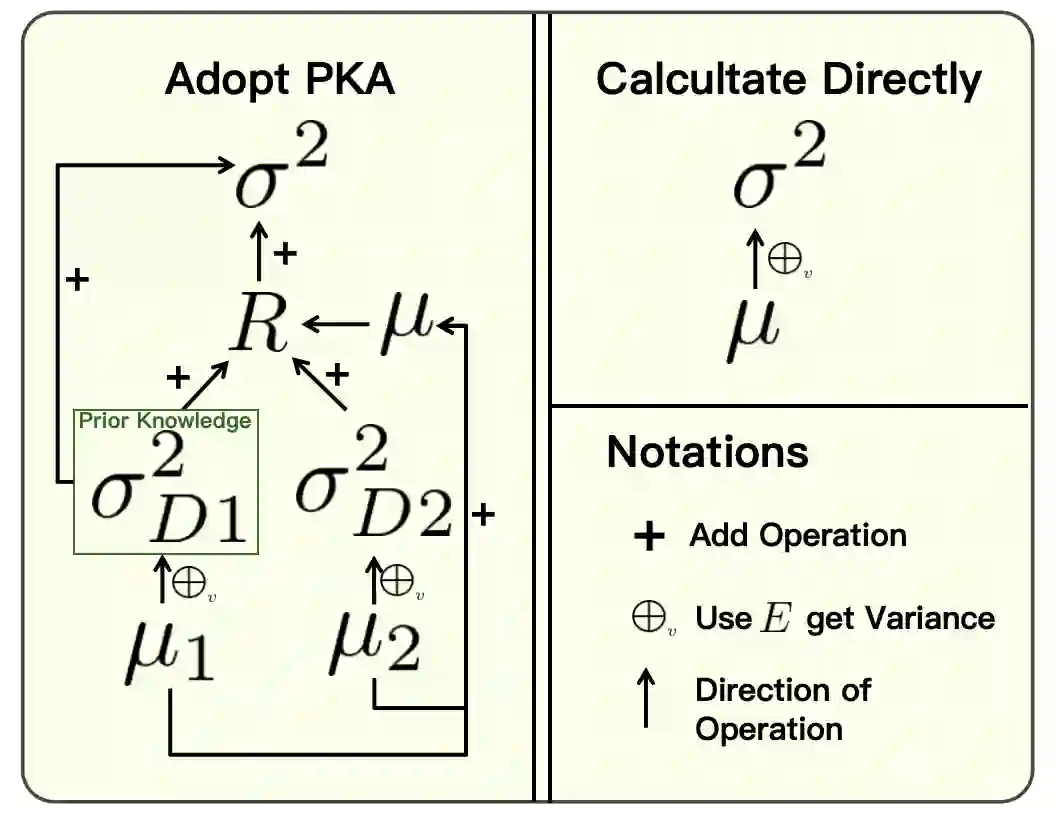
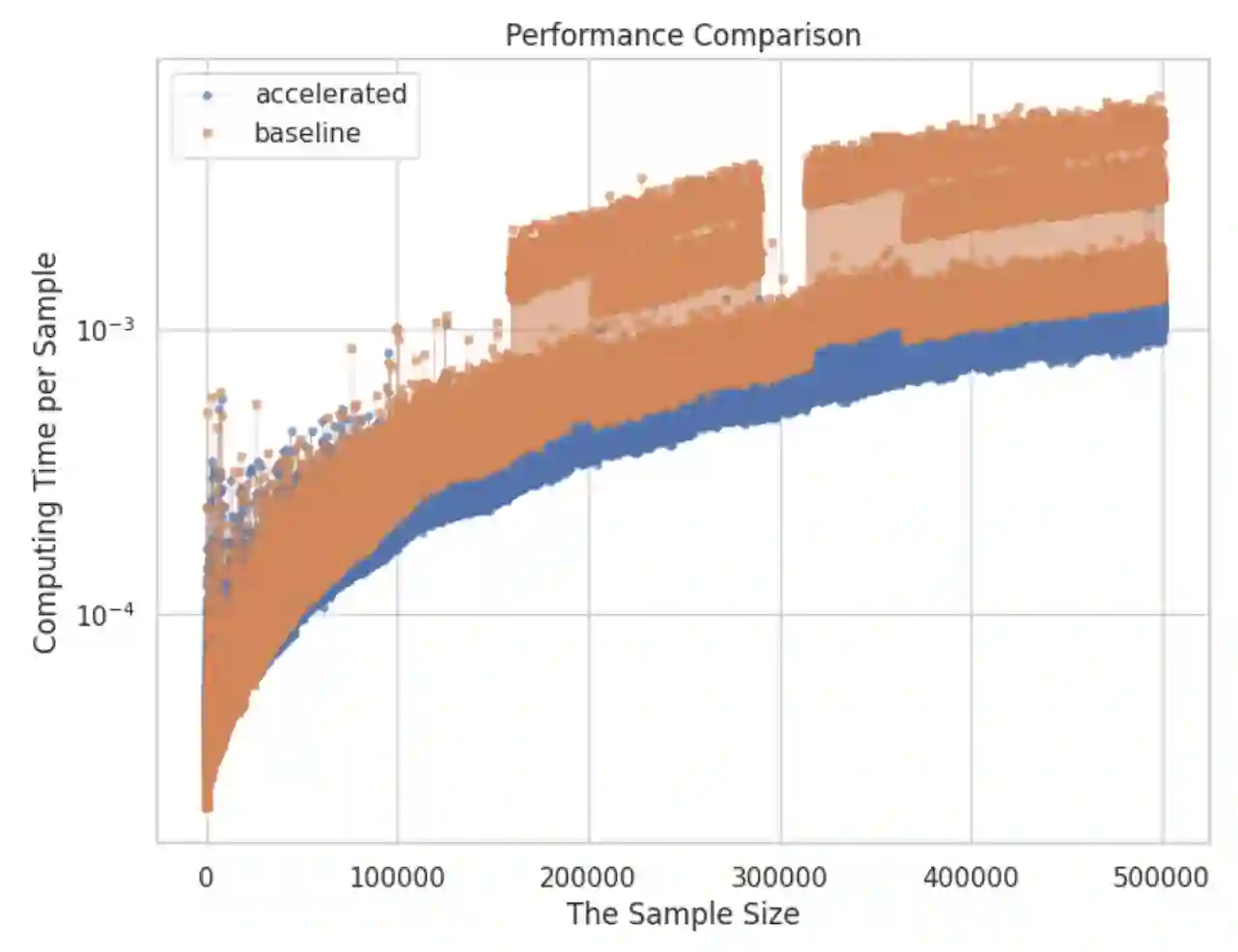
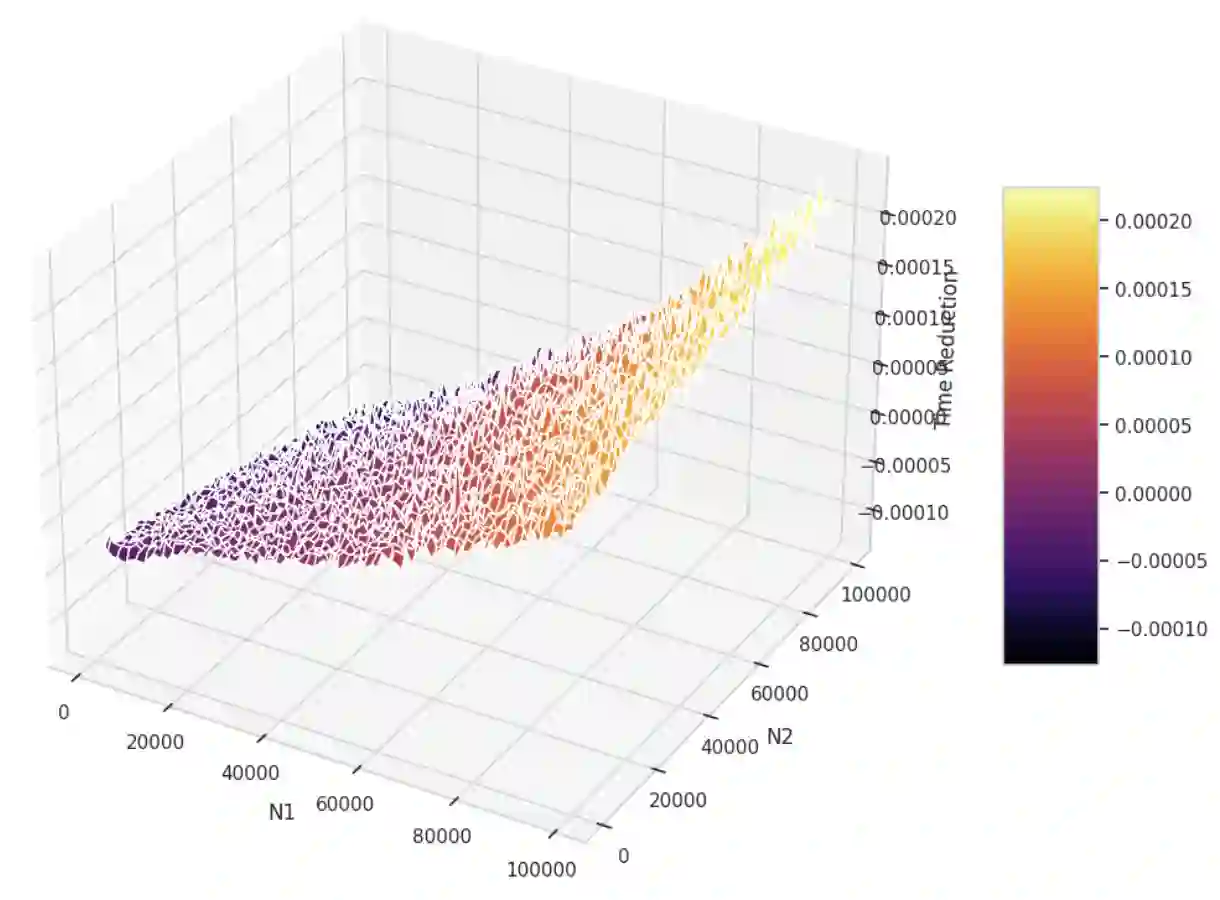
The paper introduces Prior Knowledge Acceleration (PKA), a method to speed up variance calculations by leveraging prior knowledge of the variance in the original dataset. PKA enables the efficient updating of variance when adding new data, reducing computational costs by avoiding full recalculation. We derive expressions for both population and sample variance using PKA and compare them to Sheldon M. Ross's method. Unlike Sheldon M. Ross's method, the PKA method is designed for processing large data streams online like online machine learning. Simulated results show that PKA can reduce calculation time in most conditions, especially when the original dataset or added one is relatively large. While this method shows promise in accelerating variance computations, its effectiveness is contingent on the assumption of constant computational time.
翻译:本文提出了一种称为先验知识加速(Prior Knowledge Acceleration, PKA)的方法,该方法通过利用原始数据集中方差的先验知识来加速方差计算。PKA能够在添加新数据时高效更新方差,避免完全重新计算,从而降低计算成本。我们推导了基于PKA的总体方差与样本方差的表达式,并将其与Sheldon M. Ross的方法进行了比较。与Sheldon M. Ross的方法不同,PKA方法专为在线处理大规模数据流(如在线机器学习)而设计。仿真结果表明,在大多数情况下,特别是当原始数据集或新增数据集规模较大时,PKA能够显著减少计算时间。尽管该方法在加速方差计算方面展现出潜力,但其有效性依赖于计算时间恒定的假设。