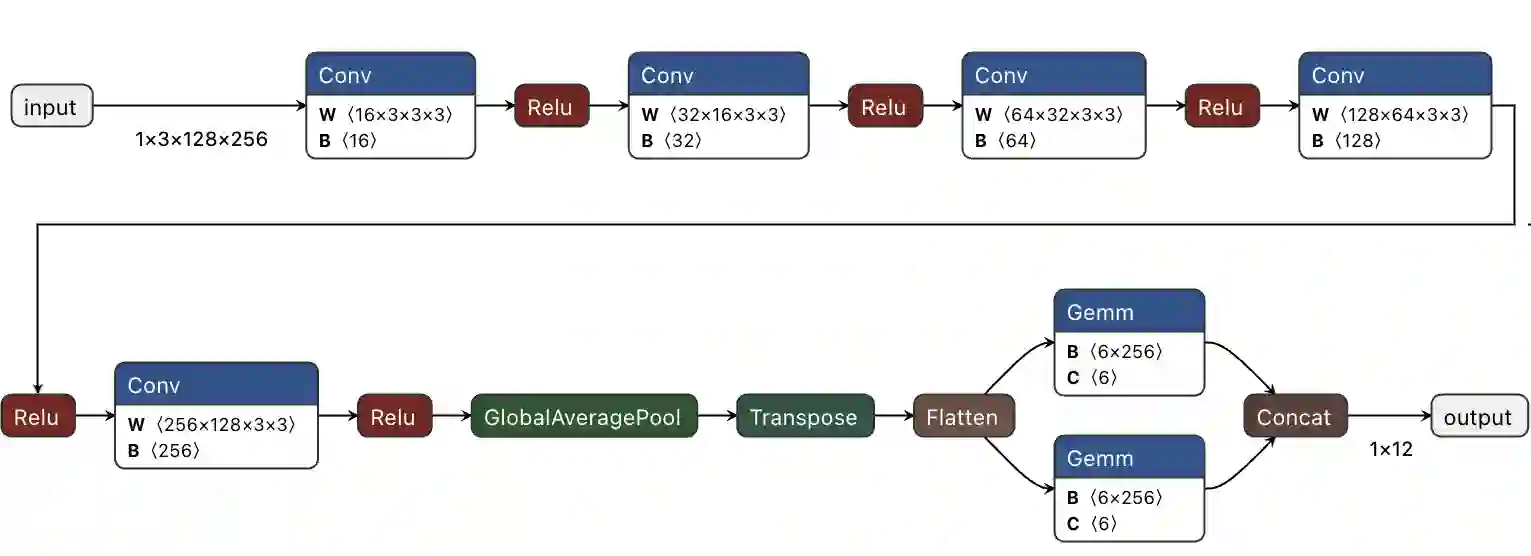
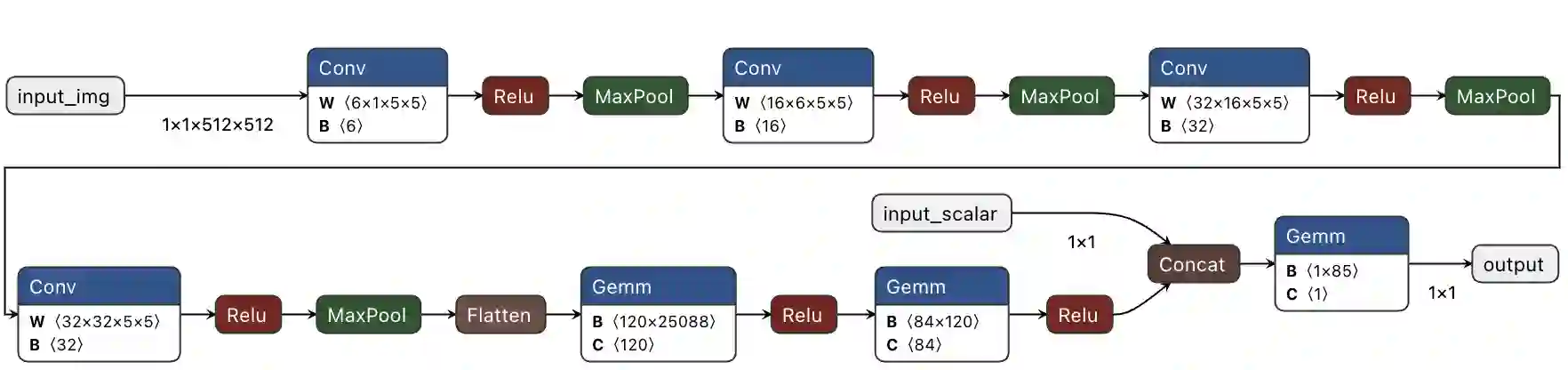
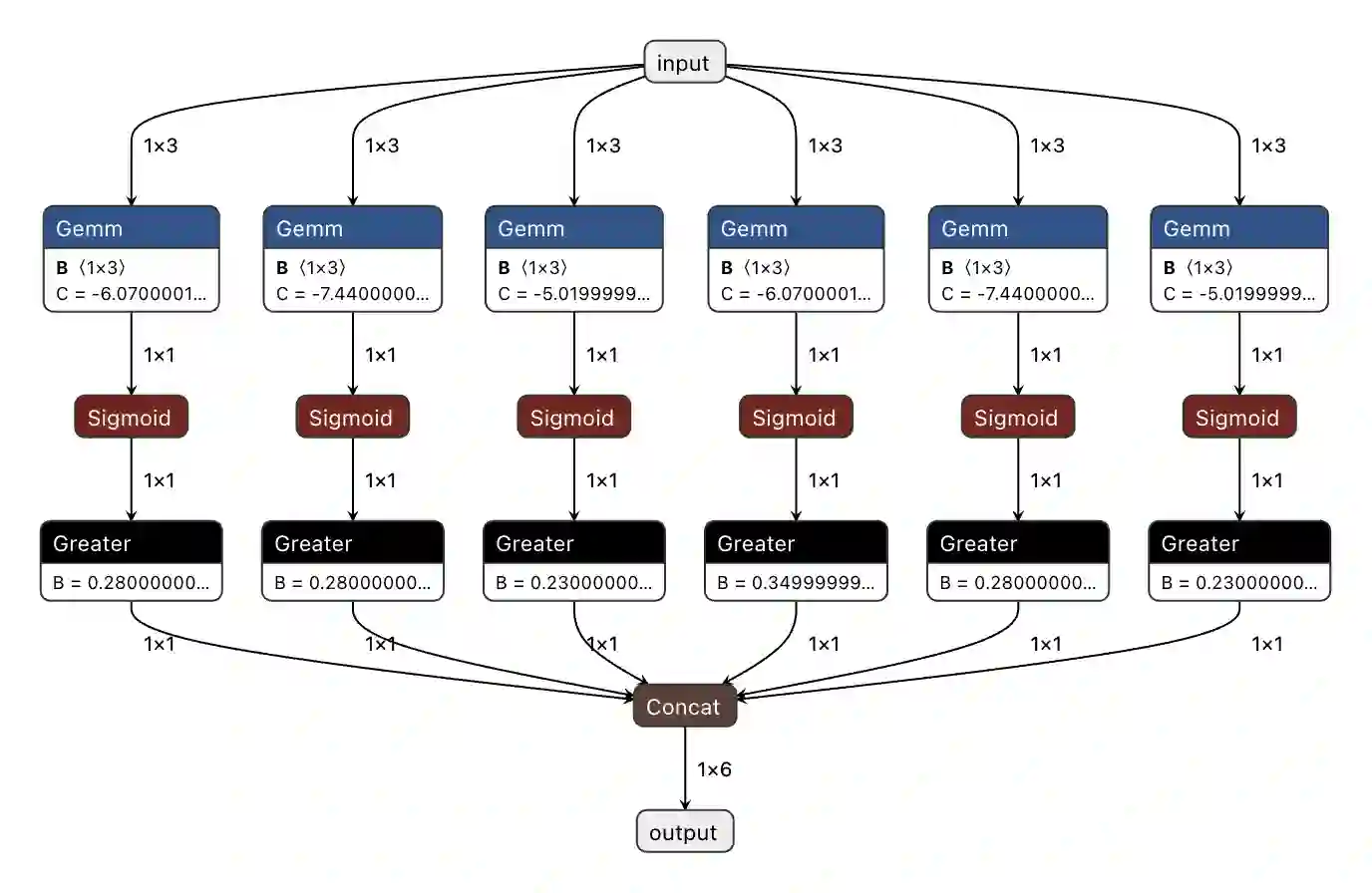
Space missions increasingly deploy high-fidelity sensors that produce data volumes exceeding onboard buffering and downlink capacity. This work evaluates FPGA acceleration of neural networks (NNs) across four space use cases on the AMD ZCU104 board. We use Vitis AI (AMD DPU) and Vitis HLS to implement inference, quantify throughput and energy, and expose toolchain and architectural constraints relevant to deployment. Vitis AI achieves up to 34.16$\times$ higher inference rate than the embedded ARM CPU baseline, while custom HLS designs reach up to 5.4$\times$ speedup and add support for operators (e.g., sigmoids, 3D layers) absent in the DPU. For these implementations, measured MPSoC inference power spans 1.5-6.75 W, reducing energy per inference versus CPU execution in all use cases. These results show that NN FPGA acceleration can enable onboard filtering, compression, and event detection, easing downlink pressure in future missions.
翻译:空间任务日益部署高保真传感器,其产生的数据量已超出星载缓冲与下行链路容量。本研究在AMD ZCU104开发板上评估了四种空间应用场景中神经网络(NN)的FPGA加速性能。我们采用Vitis AI(AMD DPU)与Vitis HLS实现推理过程,量化吞吐量与能耗,并揭示与部署相关的工具链及架构约束。相较于嵌入式ARM CPU基准,Vitis AI实现了最高达34.16$\times$的推理速率提升;而定制化HLS设计则达到最高5.4$\times$的加速比,并增加了DPU缺失的算子支持(如sigmoid函数、3D层)。实测显示这些实现的MPSoC推理功耗范围为1.5-6.75 W,在所有应用场景中均较CPU执行降低了单次推理能耗。结果表明,神经网络FPGA加速能够实现星载数据过滤、压缩与事件检测,为未来任务缓解下行链路压力。