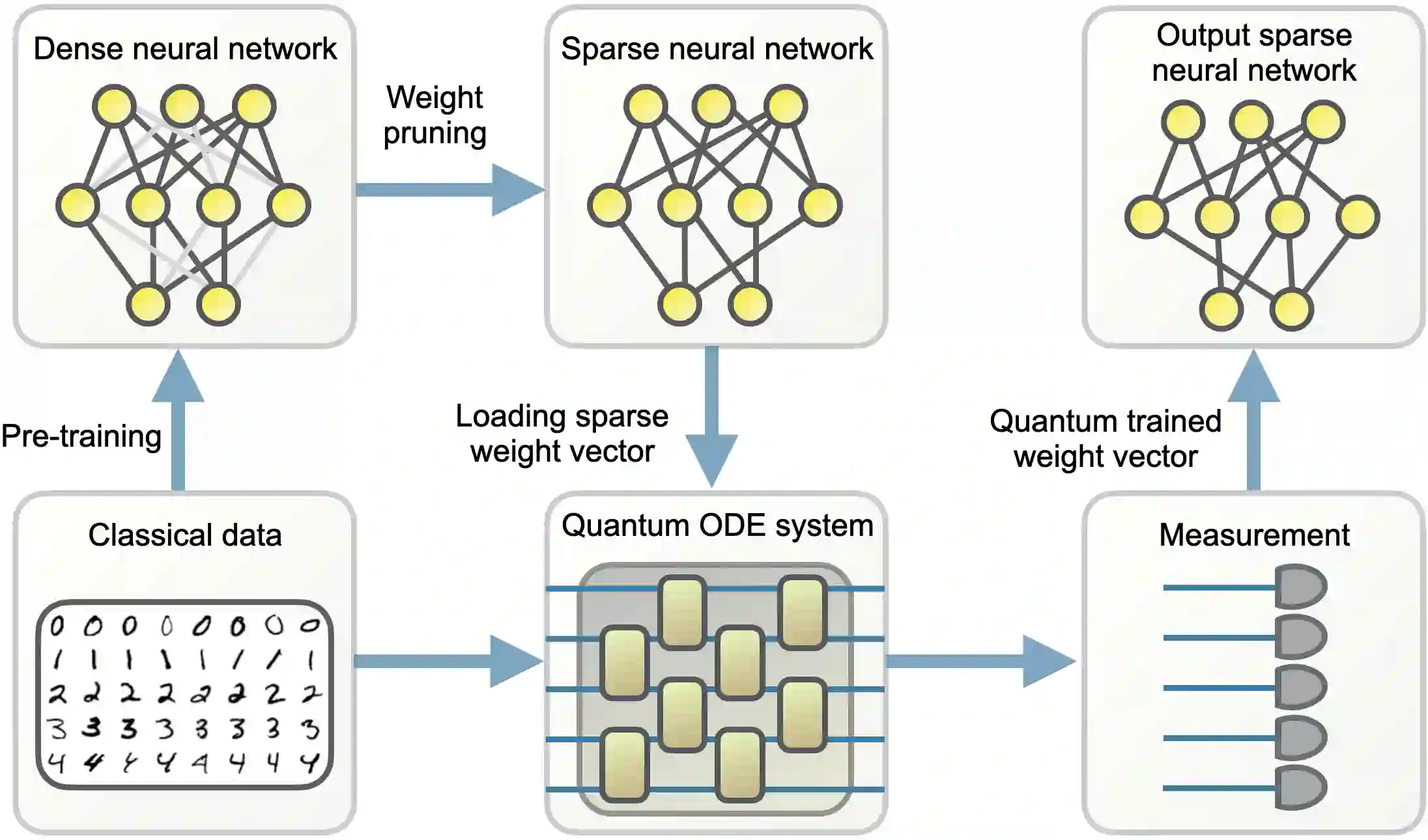
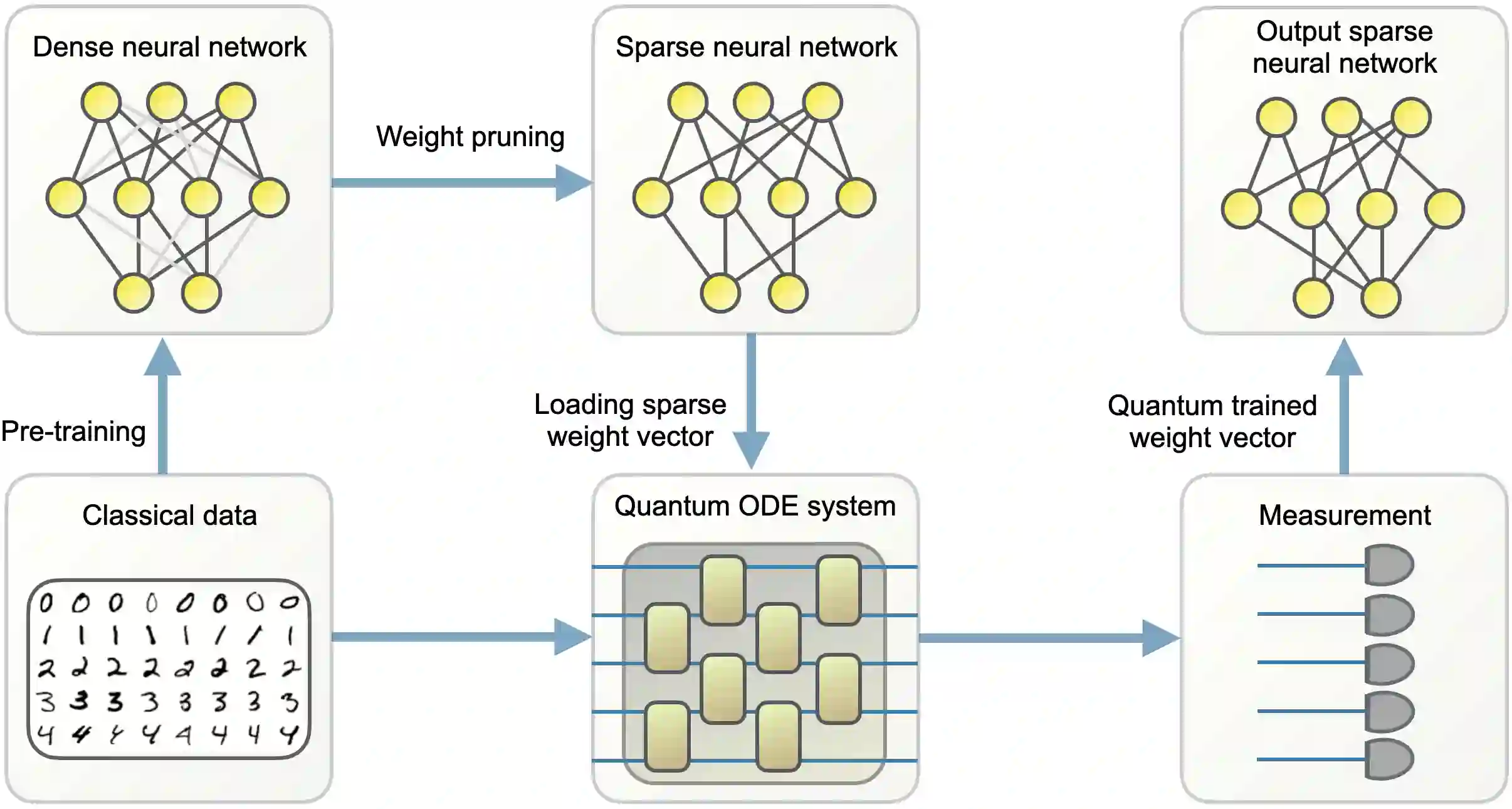
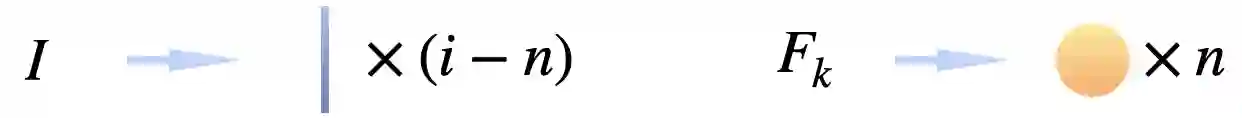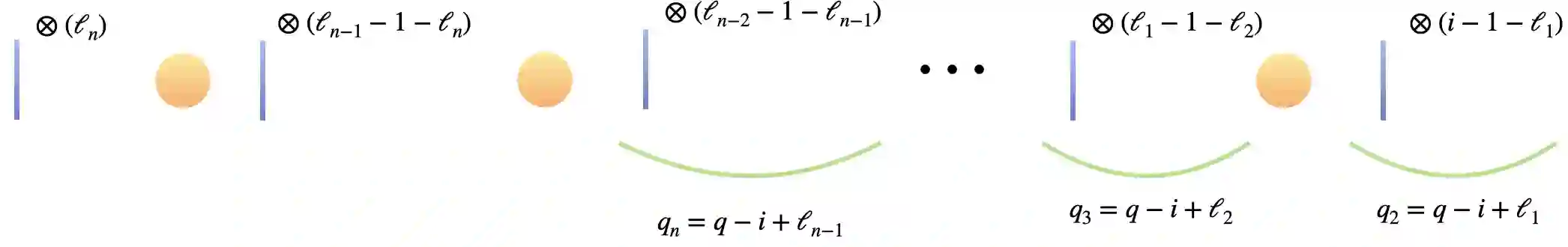Large machine learning models are revolutionary technologies of artificial intelligence whose bottlenecks include huge computational expenses, power, and time used both in the pre-training and fine-tuning process. In this work, we show that fault-tolerant quantum computing could possibly provide provably efficient resolutions for generic (stochastic) gradient descent algorithms, scaling as $\mathcal{O}(T^2 \times \text{polylog}(n))$, where $n$ is the size of the models and $T$ is the number of iterations in the training, as long as the models are both sufficiently dissipative and sparse, with small learning rates. Based on earlier efficient quantum algorithms for dissipative differential equations, we find and prove that similar algorithms work for (stochastic) gradient descent, the primary algorithm for machine learning. In practice, we benchmark instances of large machine learning models from 7 million to 103 million parameters. We find that, in the context of sparse training, a quantum enhancement is possible at the early stage of learning after model pruning, motivating a sparse parameter download and re-upload scheme. Our work shows solidly that fault-tolerant quantum algorithms could potentially contribute to most state-of-the-art, large-scale machine-learning problems.
翻译:大规模机器学习模型是人工智能的革命性技术,其瓶颈包括预训练和微调过程中巨大的计算开销、能耗和时间消耗。本研究证明,容错量子计算可为通用(随机)梯度下降算法提供近似高效的解决方案,其缩放尺度为$\mathcal{O}(T^2 \times \text{polylog}(n))$,其中$n$为模型参数量,$T$为训练轮次迭代次数,前提是模型需同时具备充分耗散性与稀疏性,且学习率较小。基于早期针对耗散型微分方程的高效量子算法,我们发现并证明了类似算法同样适用于机器学习领域的基础算法——(随机)梯度下降。实验部分,我们对700万至1.03亿参数规模的大规模机器学习模型实例进行基准测试,结果表明:在稀疏训练场景中,模型剪枝后的早期学习阶段可实现量子加速,从而催生了稀疏参数下载与重上传方案。本研究确凿表明,容错量子算法有望为当前最先进的大规模机器学习问题提供有效解决方案。