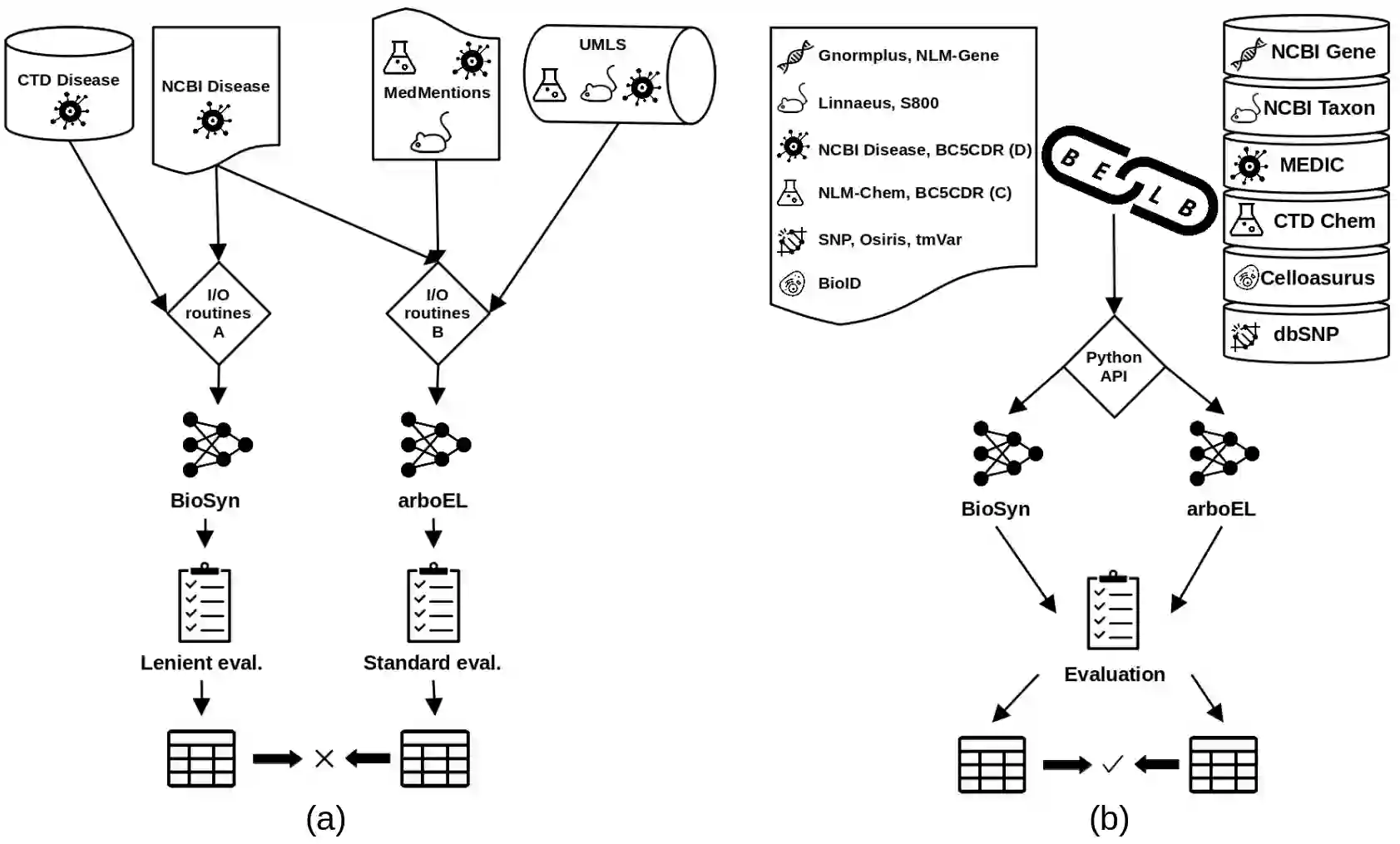
Biomedical entity linking (BEL) is the task of grounding entity mentions to a knowledge base. It plays a vital role in information extraction pipelines for the life sciences literature. We review recent work in the field and find that, as the task is absent from existing benchmarks for biomedical text mining, different studies adopt different experimental setups making comparisons based on published numbers problematic. Furthermore, neural systems are tested primarily on instances linked to the broad coverage knowledge base UMLS, leaving their performance to more specialized ones, e.g. genes or variants, understudied. We therefore developed BELB, a Biomedical Entity Linking Benchmark, providing access in a unified format to 11 corpora linked to 7 knowledge bases and spanning six entity types: gene, disease, chemical, species, cell line and variant. BELB greatly reduces preprocessing overhead in testing BEL systems on multiple corpora offering a standardized testbed for reproducible experiments. Using BELB we perform an extensive evaluation of six rule-based entity-specific systems and three recent neural approaches leveraging pre-trained language models. Our results reveal a mixed picture showing that neural approaches fail to perform consistently across entity types, highlighting the need of further studies towards entity-agnostic models.
翻译:生物医学实体链接(BEL)是将实体提及链接到知识库的任务。它在生命科学文献的信息提取流程中发挥着至关重要的作用。我们回顾了该领域的最新研究,发现由于该任务在现有生物医学文本挖掘基准中缺失,不同研究采用不同的实验设置,导致基于已发表数据的比较存在问题。此外,神经系统的测试主要针对链接到覆盖广泛的知识库UMLS的实例,而它们在更专业的知识库(例如基因或变异)上的性能则研究不足。因此,我们开发了BELB(生物医学实体链接基准),以统一格式提供对11个语料库的访问,这些语料库链接到7个知识库并涵盖六种实体类型:基因、疾病、化学物质、物种、细胞系和变异。BELB大大减少了在多个语料库上测试BEL系统的预处理开销,为可重复实验提供了标准化测试平台。利用BELB,我们对六个基于规则的实体特定系统和三种利用预训练语言模型的最新神经方法进行了广泛评估。我们的结果呈现出一幅复杂的图景,显示神经方法在不同实体类型上无法表现一致,凸显了进一步研究实体无关模型的必要性。