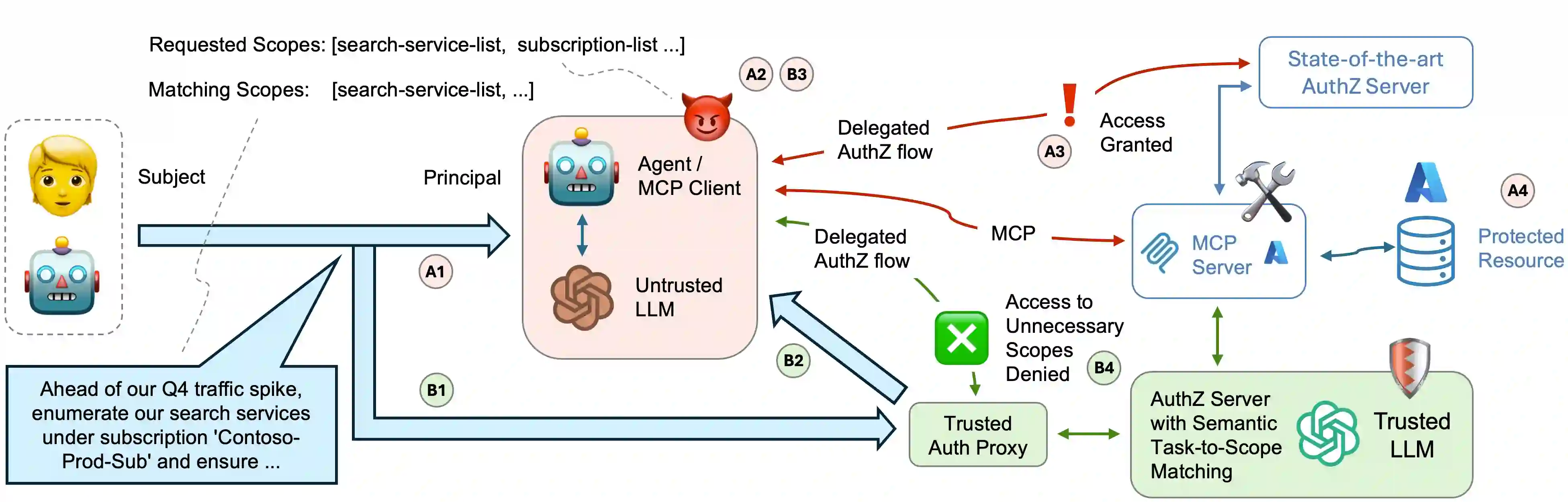
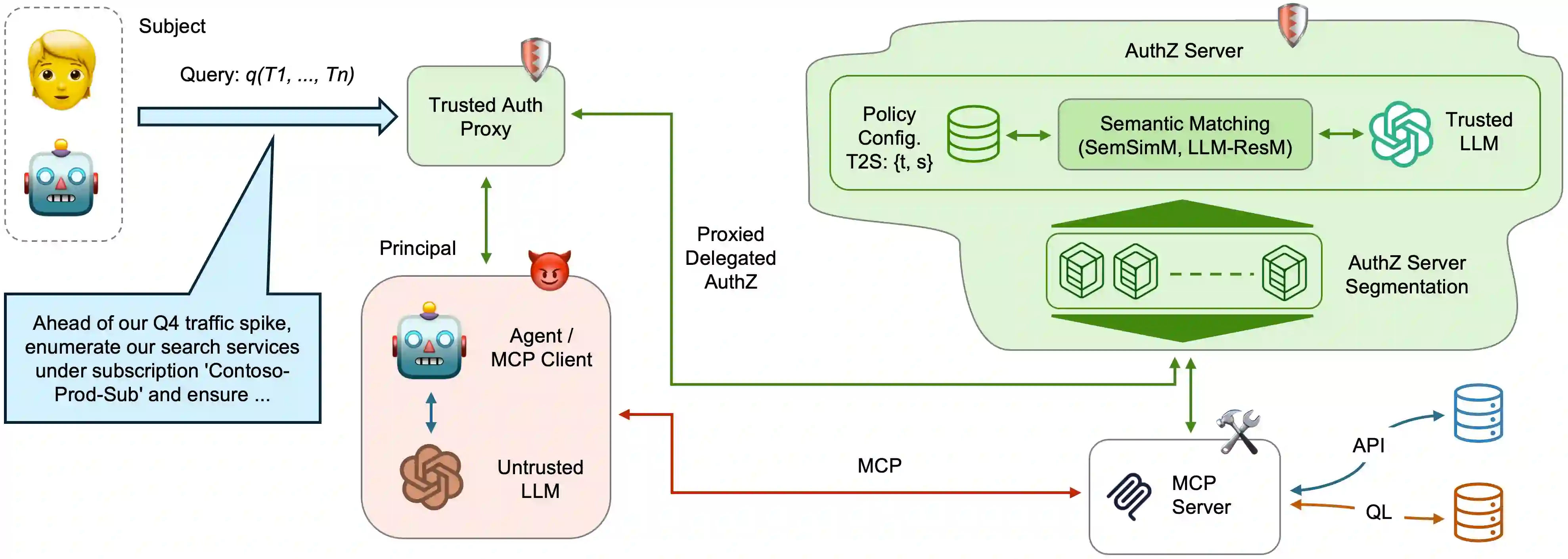
Authorizing Large Language Model driven agents to dynamically invoke tools and access protected resources introduces significant risks, since current methods for delegating authorization grant overly broad permissions and give access to tools allowing agents to operate beyond the intended task scope. We introduce and assess a delegated authorization model enabling authorization servers to semantically inspect access requests to protected resources, and issue access tokens constrained to the minimal set of scopes necessary for the agents' assigned tasks. Given the unavailability of datasets centered on delegated authorization flows, particularly including both semantically appropriate and inappropriate scope requests for a given task, we introduce ASTRA, a dataset and data generation pipeline for benchmarking semantic matching between tasks and scopes. Our experiments show both the potential and current limitations of model-based matching, particularly as the number of scopes needed for task completion increases. Our results highlight the need for further research into semantic matching techniques enabling intent-aware authorization for multi-agent and tool-augmented applications, including fine-grained control, such as Task-Based Access Control (TBAC).
翻译:为大型语言模型驱动的代理动态调用工具并访问受保护资源进行授权会带来显著风险,因为当前委托授权方法授予的权限过于宽泛,使得代理能够通过工具访问超出预定任务范围的资源。我们提出并评估了一种委托授权模型,该模型使授权服务器能够对访问受保护资源的请求进行语义检查,并签发仅包含代理执行指定任务所需最小权限范围的访问令牌。鉴于目前缺乏专注于委托授权流程的数据集,特别是包含针对给定任务的语义适当与不适当权限范围请求的数据,我们引入了ASTRA——一个用于基准测试任务与权限范围之间语义匹配的数据集与数据生成流程。实验结果表明,基于模型的匹配方法既展现出潜力,也存在当前局限性,尤其是在完成任务所需的权限范围数量增加时。我们的研究结果强调,需要进一步研究语义匹配技术,以实现多代理与工具增强应用中的意图感知授权,包括细粒度控制,例如基于任务的访问控制(TBAC)。